SCI论文(www.lunwensci.com):
摘要:近年来,网络黑产犯罪事件层出不穷,形成较完备网络黑色产业链。为维护网络信息安全,中央网信办、工信部、公安部、中国人民银行等部门持续开展治理工作,相关企业也不断加大整治力度。信用卡盗用盗刷是网络黑产常见形式之一。本次研究基于信用卡历史交易数据,借助半监督学习,构建反欺诈预测模型,对信用卡盗刷行为及时预警。
关键词:网络黑产;信用卡盗刷;异常检测;半监督
Research on Financial Fraud Detection Based on Semi-supervised Modeling
GAO He
(Beijing Financial Security Industrial Park,Beijing 100005)
【Abstract】:In recent years,cyber-crimes have emerged one after another,and a relatively complete industry chain has been formed.In order to maintain cyber information security,the Central Cyberspace Administration,the Ministry of Industry and Information Technology,the Ministry of Public Security,the People's Bank of China and other departments have continued to improve the governance,and relevant companies have also increased rectification.Credit card fraud is a common cyber-crime,and the study is based on credit card historical transaction data,with the help of semi-supervised learning,to construct an anti-fraud prediction model and to provide timely warning.
【Key words】:cyber black market;credit card fraud;anomaly detection;semi-supervised
近年来,网络黑产犯罪问题日益突出,已经形成了上游收集资源、中游开发工具、下游交易变现的黑色产业链。为维护网络信息安全,中央网信办、工信部、公安部、中国人民银行等部门持续开展治理工作,相关企业也不断加大整治力度。在黑产犯罪中,信用卡盗用盗刷是较常见的欺诈形式之一。特别是电商、网游及近年较火爆的直播、短视频等业态,带动支付业务增长的同时,也引起黑产团伙关注,盗用盗刷信用卡以谋取暴利,对上述行业健康发展形成巨大威胁。
随数据科学不断发展,异常检测作为一个重要分支受到广泛关注,可在大批量样本中识别特殊个体,对金融欺诈识别具有重要意义[1]。传统基于监督学习的建模方法能够在固定的场景下建立准确行为模型,但需事先手工标记大量训练样本。半监督学习建模方法能够自动建立行为模型,减轻人工负担的同时提升算法适用性。本次研究基于半监督学习和深度学习理论,构建反欺诈预测模型,实现对信用卡盗刷行为及时预警。
1金融欺诈—概念与现状
“金融欺诈”是指以非法占有为目的,以隐瞒真相或虚构事实等手段,骗取财物或授信、破坏金融管理秩序的违法行为。随着数字经济的普及,金融欺诈手法也日趋与数字技术结合,衍生出新型金融欺诈手段。当前,数字金融领域欺诈主要表现为高利理财、网络借贷、网络众筹、消费金融、非法集资等五大类型。其中,消费金融类欺诈中信用卡盗用盗刷是较为典型的手段。
《2016年国内银行卡盗刷大数据报告》显示,超过一半以上的盗刷通过快捷支付完成,另有一部分通过网银支付完成。在快捷支付盗刷案件中,97%的用户都是遭遇了第三方支付盗刷。此外,线下支付渠道情况也不乐观。2016年,工商银行全年投诉量达1923次,用户损失达3874.8万元;建设银行全年盗刷案件投诉达1507次,用户损失3720.4万元;招商银行位居全行业第三,盗刷投诉量达875次,用户损失金额2358.3万元。
2019年8月,北京银保监局印发《关于加强银行卡风险防控的监管意见》,针对当前银行卡业务面临的电信诈骗、盗刷、信用卡授信不审慎等问题,从六大方面明确了十三项具体监管要求。以信用卡盗用盗刷为代表的金融欺诈风险已引起全社会的高度重视。
2工作目标设定及技术路径选择
本次研究基于信用卡历史交易数据,借助半监督学习,构建反欺诈预测模型,对信用卡盗刷行为及时预警[2]。主要技术实现步骤如下:
(1)数据处理:接入合作金融机构提供的相关数据,分析其中的盗刷行为,完成数据预处理、数据转换、特征提取等,将多源异构数据转为模型可识别的数据结构;
(2)模型构建:基于上述数据源进行学习建模,过程中将模型偏差、新特征、不确定特征等进行专家手动评估并标注,以主动学习框架持续优化数据,最终训练出稳定且符合预期的盗刷识别模型;
(3)模型迭代:使用上述模型分析金融机构客户交易行为数据,预测结果经风控专家进一步会商,进行深度解读,并基于专家解读反馈到模型学习中,起到模型持续迭代的效果。
3数据处理
原始数据来自合作金融机构,为持卡人两天内的信用卡交易数据,已经脱敏处理。
(1)数据导入:数据包含多个维度,如用户基础信息、行为数据以及客户提供的少量标签数据,以及与行为关联的IP地址、UA和设备指纹等环境数据。手机号仅显示前7位,其余通过Hash加密。
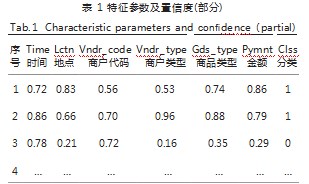
(2)数据统计:持卡人消费方式常呈现独有的统计特征,系统将经预处理的数据按照用户进行统计,并存储统计结果,以备后续计算置信度。其中,对刷卡时间进行时段频率统计;对刷卡地点、购买商品类型、交易商户代码、交易商户类型分类统计,并按照正态分布确定刷卡金额标准差σ、均值μ。
(3)置信度计算[3]:
1)离散型数据:
以商品类型为例:设消费次数为n,购买商品类型记为X={x1,x2,…,xn},其中xi,i=1,2,…,n,是第i次购买的商品类型,以mxi表示在商品xi上的刷卡次数,则对于任意xi,其发生的置信度C(xi)为:

,其中,0≤mxi≤n(1)
其他离散型数据同理。
2)连续型数据:
刷卡金额通常符合正态分布,设消费次数为n,X={x1,x2,…,xn},其中xi,i=1,2,…,n,是第i次消费的刷卡金额,持卡人刷卡金额标准差为σ,均值为μ,则第i次刷卡金额置信度为:
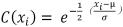
经计算后的各特征及特征置信度如表1所示:
置信度越高意味着某特征出现的可能性越高,经预处理后的结构化数据也将便利半监督学习过程。
4模型构建
模型构建是本次研究最核心的部分。系统采用少量标签数据和大量无标签数据进行机器学习建模,融合图分析、分类和聚类等算法的优点,在海量数据中识别弱关联,发现数据中的异常,并输出结果。
传统的监督机器学习可利用多维数据建立复杂模型。就银行风控场景而言,可根据欺诈交易的概率为每条规则逐一加上权重,再将规则转为可以计算数值,最终得到该类事件的概率。监督机器学习通常使用大量标签样本训练模型,并以此预测新样本。但标签只代表历史事件,当欺诈手段升级后,以往的标签逐渐失效。标签太少,模型就不够准确,而增加标签,又显著增加风控成本。因此,对监督机器学习而言,可用标签数量的多少其实是控制风控成本和提高风控效率之间的博弈。
半监督学习(Semi-Supervised Learning,SSL)将监督学习与无监督学习相结合,是模式识别和机器学习领域的研究重点。半监督学习使用大量的未标记数据,结合部分标记数据进行模型构建。减少人工成本的同时,又能够带来较高的预测精度。
4.1算法公式
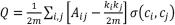
(3)
其中,Aij表示节点i和节点j所形成的边的权重,即特征维度权重;ki=Aij表示所有与节点i连接的边的权重之和;ci表示节点i所属的聚类;m=1/2 Aij表示所有边的权重之和。
4.2算法过程
(1)以经处理后特征作为输入,计算边的权重,提取最关键的特征维度。
(2)算法遍历样本数据中全部节点,并进一步遍历每个节点的全部相邻节点,计算该节点加入其相邻节点所在聚类所带来的收益,并选择收益最大的相邻节点,加入其所在的聚类。按上述方法反复迭代,直至聚类结果收敛。
(3)进一步分析步骤(2)中获得的聚类,将拥有相似账户或强相关的聚类建立关联,并计算各聚类间边的权重,以及各聚类内部所有点间边的权重之和,用于下一轮遍历计算。
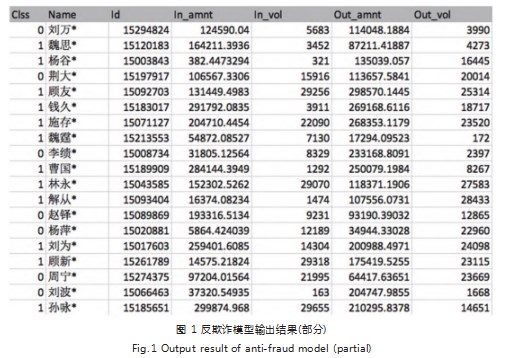
(4)对已检出的账户按照聚类可疑度排序,分值从0.0到1.0,分值越大可疑度越高。(如图1所示)
取20次测试均值并绘制ROC曲线可知,模型有较好识别力,阈值取0.5时性能最佳,模型对刷卡行为异常检测的正确肯定率为92.3%,错误肯定率为11.16%。
5模型迭代
模型接入实时业务系统后,可进一步通过可视化界面输出用户等级评分和行为分类,融合安全专家和反黑灰产专家的经验,逐步实现可疑交易由主要依赖手工判断,过渡为专家经验与人工智能手段相结合实现。通过对接金融机构基于规则的可疑交易监测系统,对检测出的可疑交易进行基于上述模型的自动排序和等级分类。
内控合规专家可以进一步根据等级排序,灵活安排不同程度的人工审核,模型基于半监督主动式机器学习的方案融合图分析、聚类和分类等算法的优点,综合少量标签数据和大量无标签数据,基于账号信息、交易行为和对手关联等数据进行高效建模,提高覆盖率,降低误伤率。同时,通过专家知识介入,使得模型能够自主学习新的经验、方法和技能,促进模型持续优化迭代,让模型更加贴近真实场景,主动适应日益变化的市场环境,应对未知风险[4]。
6总结
本次研究采用半监督主动式机器学习方法,将专家经验与人工智能有机结合,在已有的标签体系下对系统收集来的各类型数据进行分类及关联分析,可准确监测刷卡异常行为,有助提升金融机构服务能力和监管效率。
参考文献
[1]葛文超,魏超,王玉涛,等.基于潜在空间矩阵的半监督异常检测[J].计算机应用研究,2020,37(S2):318-320.
[2]琚春华,陈冠宇,鲍福光.基于kNN-Smote-LSTM的消费金融风险检测模型:以信用卡欺诈检测为例[J].系统科学与数学,2021,41(2):481-498.
[3]胡国清,陈辽林,刘谦波,等.结合特征置信度的背景感知相关滤波跟踪算法[J].现代电子技术,2021,44(17):72-79.
[4]丁尧相.人机协同机器学习[D].南京:南京大学,2020.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/39839.html