SCI论文(www.lunwensci.com):
摘要:人工智能技术从概念阶段进入到工业界落地实施阶段,各企业也希望将互联网的先进技术应用于企业智能化中。在企业内部实现基于人工智能的推荐系统,将企业内部新闻、知识、积累的技术向员工推送,改变传统的依靠员工在各种系统中人为检索的方式,实现从人找知识到知识找人的转变。本文描述了一种基于人工智能的企业级搜索推荐的实践方式。
关键词:人工智能;搜索;推荐系统;企业智能化
Implementation of Enterprise Information Recommendation Based on Artificial Intelligence Technology
LIU Wei
(ZTE Corporation,Nanjing Jiangsu 210012)
【Abstract】:AI technology has entered the implementation stage of industry from the concept stage.Enterprises also hope to apply the advanced technology of the Internet to the its intellectualization of internal data.The recommendation system based on AI is implemented within the enterprise to push the internal news,knowledge and accumulated technology to employees,change the traditional way of relying on employees to search artificially in various systems,and realize the transformation from people looking for knowledge to knowledge looking for people.This paper describes a practical method of enterprise search recommendation based on AI.
【Key words】:artificial intelligence;search;recommendation system;enterprise intelligence
0引言
我们国家从战略层面制订了新一代人工智能发展规划,从而推动人工智能技术在各行业的快速发展。推荐系统和搜索系统都能够实现人与信息的交互,其差别在于用户使用搜索系统时知晓寻找的内容是什么,通过关键字进行文章查找。推荐系统则是通过记录用户的行为日志,提取特征给用户画像和建模,再依托算法去推荐文章。简单说:搜索系统是人找信息,推荐系统是信息找人。同时,企业内部新闻和信息推荐系统与互联网企业的商品推荐、新闻推荐、视频推荐存在较大的不同。企业推荐的数据源主要是企业内部网页、文档、或者第三方对接的网页、文档,数据获取方式主要是API方式,排序方式为企业关注的内容和企业业务,权限管理较互联网复杂,数据存储方式多样。
1关键诉求及解决思路
推荐系统涉及的参与者有:最终用户、文章提供者和推荐系统[1]。好的推荐系统既可以准确预判用户兴趣,又可以拓展用户的兴趣范围,将被埋没在长尾中的好文档向兴趣匹配的用户推送。推荐效果的好坏主要考虑如下几方面:准确度、覆盖率、新颖性、信任度等。
1.1冷启动问题
推荐系统依靠用户的历史数据,依托算法来挖掘用户兴趣,预测用户行为,所以积累一段时间的用户日志,是推荐系统成功的关键和前置因素。新的系统在没有历史用户数据的情况下,也要有一个较好的推荐结果,需要解决的是冷启动问题。可以分为:用户冷启动、物品(文章)冷启动、系统冷启动。
解决思路:提供非个性化的文章推送,如TopN热
点阅读排行榜,待积累日志数据后再更改为个性化推荐。利用用户属性信息,如岗位角色、年龄司龄、业务领域等。对新加入的物品,利用其内容信息。
1.2用户画像和用户标签
用户画像和用户标签的目的是构造用户特征,既用于推荐算法的输入,又用于推荐结果的可解释性。
用户原始记录包括几个方面:用户静态信息:与用户相关的属性信息;用户内容数据:用户发表、查看的内容、搜索的关键词等,这些内容通常代表用户的兴趣点;用户行为日志:用户登陆的地点、终端类型,用户对内容执行的交互操作,在系统中就是点赞、转发、评论、收藏;外部数据:引入用户在其他系统中的数据;通过对用户个性化的原始记录,构造用户的画像。
标签:构造标签系统。司龄标签、岗位标签、员工所在地。
画像:每个用户具体的标签内容,如某销售处20届的李小明标签可以:新员工、销售、海外。用户可以分为静态画像和动态画像。静态画像:用户独立于产品场景之外的属性,信息稳定、具有统计意义。动态画像:用户在具体场景中产生的显式行为或隐式行为。显式行为:明确表达出的喜好,例如点赞、关注、正向评分和评论。隐式行为:没有明确表达的喜好,但通过点击、停留时长等形式表现出来。
1.3文档标签
按照文档的内容、特性构造文档标签,文档标签表明文档是什么,文档的种类,谁发布了文档,来源哪里等特性。文档标签分为:标签名、标题分类、文档业务种类、来源、文档产品生命周期、文档内容、文档类型、文档长度、作者信息、客户、生产商、创建时间、更新时间等。
2企业级推荐系统功能及实现
企业内部推荐系统的核心目标:降低信息获取难度,提升员工工作效率,推送合适的文档给员工[2]。
呈现方式:在“推荐”页面展示推荐结果。用户点击推荐菜单后,根据用户画像,用户历史搜索行为,输出推荐的文档。猜你喜欢:在用户读完一篇文档后,根据文档内容的关联关系,以“猜你喜欢”的方式显示一批文档,标题及链接,在搜索的结果文档显示该文档被推荐的理由。
文档置顶:对关键文章在一定时间段内对特定人群置顶,如年末时,将加紧回款通知,对销售和财务领域人员置顶。以及全员置顶新冠疫情信息。
去重与过滤:对相似度超过一定阈值的文档,仅显示一篇文档,其他文档不重复显示。选择显示哪篇文档需要从热度、是否有权限、时间早晚判断。过滤已读文档。
避免信息茧房:推荐系统的一个弊端是按照用户的历史行为进行推送,导致推荐的文章内容越来越趋于历史偏好。长期如此将导致用户对推荐文档不感兴趣。在系统设计时,除关注用户历史爱好外,还能够按照一定方式或规则推荐一些非用户历史兴趣相关的文档,探索和拓展用户的兴趣点。
系统监控:监控系统单位时间粒度的用户活跃度,监控每种算法的评价指标。监控系统中的文档、用户现有数量、新增数量,监控系统的运行状态,监控硬件资源的使用情况。
可扩展性及不停服升级:随着系统不断运行,可接入的数据会越来越多,所以系统的性能扩展性非常重要。推荐系统需要不断的对其中算法或者子系统进行调整,需要提供不断服务的情况下对不同组件进行升级的能力。整体架构如图1所示。
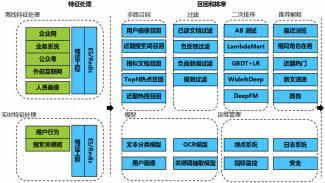
图 1 架构
部署方式,为提供一定的灵活性,搜索引擎系统以微服务方式部署,一个是容器管理,采用K8S组件,另一个是技术框架支持部署的服务可以被发现、被监控、统一鉴权、统一日志等。
2.1系统流程
整个系统由数据存储实体和算法组成,实体有文档、用户画像、日志,算法则分别是召回、排序、文本相似度与分类相关算法。系统支持算法的逐步迭代优化,逐步完善推荐效果。
从流程上看,当用户登陆后,从用户画像中提取用户信息如特征、历史行为等,从ES库中召回文档。再通过二次排序算法输出重排结果。当用户点击阅读某篇文档时,依据文档相似度提取最相似的若干篇文档,在用户正阅读的文档底边,生成文档标题和链接,供用户选择。和传统电商与IT系统不同,企业的人员相对固定。从人员数量和文档数量以及人员与文档的更新频度上看,做为企业内部的推荐系统,采用从基于用户的推荐或基于物品的推荐启步,依据推荐效果的监控,逐步优化和更新推荐算法。
做为数据存储的实体,用户画像模块存放用户的静态特征、动态特征和历史行为。在用户画像中用户的动态特征可以准实时构造,如系统每5分钟刷新一遍有行为的用户的动态特征。初期,可以仅用离线的静态特征进行用户画像构造。系统流程如图2所示。
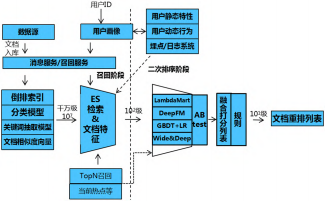
图 2 系统流程
2.2多路召回
召回的目的是快速从系统中的千万篇文档中提取出几百篇的文档。多路召回一方面要考虑用户的长期兴趣点、也要考虑用户的短期兴趣、当前热点等。
用户画像召回:基于用户画像的标签,获取按时间序列最新的文档。近期搜索词召回:基于用户近期的搜索词,输出搜索词的搜索结果。相似文档召回:基于用户最近阅读的文档,提取该文档的相似文档。如用户最近阅读了5G、冬奥会的文档,则召回该文档的相似文档。文档的相似度可以考虑文档关键词相似,构造文档向量,按照向量相似度比较。
TopN热点召回:当日、当周的点击率、阅读时长最长的文档。近期热搜召回:当日、当周热搜的关键词对应的搜索结果。如前一日Top5的搜索关键词。基于好友的推荐:基于有交互的好友如关注,把互动过的好友用户的点赞、转发、文档、进行推荐召回。
每篇被召回的文档打上召回原因做为召回解释,提升用户对系统的可信度。例如:用户画像为销售,则标注:售前文档;若当日的最大点击量文档,则标注为:当日最热等。每篇召回的文档打上召回的通道,一篇文档被多个通道召回的记录多个通道,用于后续评估和优化召回算法。召回的关键点是速度快,要在几百毫秒内完成。每路召回算法设置为单独的微服务。
2.3文档过滤
已读文档过滤:在日志埋点系统中记录用户的浏览记录,剔除已读文档。负反馈过滤:剔除用户显示反馈过的不喜欢的文档,如“踩”过的文档,评论中为“极端负面情绪”的文档。负面新闻过滤:对文档进行情感分析,高于一定阈值的负面文档剔除。规则过滤:人工设置规则,比如含有某些汉字、反社会、不和谐、涉及黄赌毒的文档剔除。
2.4二次排序算法
对召回的文档使用二次排序算法,输出排序结果。采用的二次排序算法有:GBDT+LR、DeepFM、Wide&Deep,以及采用比较常见的双塔模型。GBDT+LR方法用于其推荐系统,优势是速度快。DeepFM模型其Wide模型部分为FM模型具有自动学习交叉特征的能力,避免了原始Wide&Deep模型中浅层部分人工特征工程的工作。其共享原始输入特征Feature Embedding,原始特征将作为FM和Deep模型部分的共同输入,使得训练更快,更加准确。
2.5标签和用户画像
对用户和文档均构造标签。人员或文档的标签越丰富,越能体现其差异性。文档关键词依赖关键词抽取模型的能力,与手工标签结合能提升推荐的准确度。通过打静态标签可以解决人员和文档冷启动问题,提供推荐结果结果差异性的兜底能力。用户画像中存储用户的静态标签、动态标签、动态or定时更新的历史搜索行为。用户画像中存放用户的历史行为,如历史点击的文档(文档ID等)、时间、停留时长。当前端发来用户ID后,使用画像中的不同特征,和召回服务交互,获取对应的文档。召回是多路的,分阶段从简到难实现每种特征及其召回结果。
2.6 AB测试与灰度发布
推荐系统的特征构造和算法选择是一个永不终止的迭代过程,需要通过AB测试实现新特征、新算法的线上测试验证。在算法进行灰度发布前,已经进行过离线评估,但离线评估无法完全还原线上的所有变量,通过线上AB测试验证新算法、新特征的有效性。AB测试又称为分流测试、分桶测试,将用户随机分为实验组和对照组,对实验组施以新模型,对照组使用原模型,比较实验组和对照组在线上评估指标的差异。在实现中需要注意,同一个用户在测试的全过程中只能被分到一个桶中。
AB测试分层和分流的机制:层与层之间的流量是“正交”。层与层之间的独立试验的流量是正交的,实验中的每组流量穿越该层后,都会被再次随机打散,且均匀分布在下层实验的每个实验组中。同层之间的流量“互斥”。同层之间的多组AB测试,不同测试之间的流量是不重叠的。
红名单用户不参与新算法的测试,使用稳定可信的算法。白名单:指定参与AB测试的友好用户。在界面配置算法、红白名单、流量占比,监控算法指标。
2.7用户日活和指标监控
用户活跃度监控:小时粒度、日粒度的搜索用户数、搜索次数;在界面以图形和表格方式展现。支持筛选展示的内容;从人员的角度分:管理干部和普通员工;岗位角色:销售、售后、研发;从地域角度分,国内城市和海外。算法指标监控:监控已上线的指标,显示算法的名称,该算法对应的用户数。监控用户的停留时长。
2.8隐私保护、加密与合规
用户搜索记录涉及用户隐私,系统中避免直接存放用户ID类信息。服务端与客户端使用HTTPS协议进行数据传输。设计和使用加密与脱敏功能。在日志中涉及用户ID、姓名的字段采用加密和脱敏,如:公司的员工工号采用加密算法转换为数字和英文大小写字母,如209910099999,转换为2abd876DEF99;用户姓名使用星来替换,比如:诸葛亮,转换为诸**,或者诸*亮。
3展望
传统企业也具有强烈和迫切地使用人工智能技术的需求。随着数字化的发展,内部数据种类迅速增长,企业知识复杂化,内部人员迫切地需要采用智能推荐技术在客户服务、内部管理提效、企业知识传递等方面进行改造,以弥补传统手段的不足。在人工智能技术浪潮快速发展的今天,有幸参与了若干企业业务智能化应用,并有良好的效果。除了现有的推荐方法,如何实现推荐效果的不断提升,进行闭环控制是今后要发力的地方。
参考文献
[1]项亮.推荐系统实践[M].北京:人民邮电出版社,2012:23+78.
[2]王喆.深度学习推荐系统[M].北京:电子工业出版社,2020:72+80+227.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/39012.html








