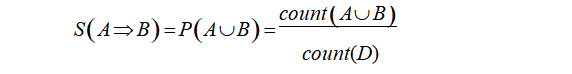SCI论文(www.lunwensci.com):
摘 要:随着教育数据的不断增多,成绩数据不断积累,而这些数据大部分不能被充分利用,造成数据浪费, 因此采用数据挖掘技术挖掘数据中潜藏的有价值的信息是有必要的。本研究以某高校 2016 级教育技术学本科生的课程成绩为研究对象,使用 SPSS Modeler 软件对 K-means 和 Apriori 算法构建模型,对课程成绩进行深层次挖掘和分析,通过对挖掘结果详细的分析,帮助教学管理者进行课程的安排以及教学计划的制定,从而提高教师的教学质量和学生的学习质量。
关键词:数据挖掘;K-means 算法;Apriori 算法
本文引用格式:赵美玲 , 陈琦, 方嘉文. 基于K-means 和Apriori 算法的学习成绩和课程关系的挖掘和分析[J]. 教育现代化 ,2020,7(92):110-114.
Mining and Analysis of Learning Performance and Course Relationship based on K-means and Apriori Algorithm
ZHAO Meiling, CHEN Qi, FANG Jiawen(Hubei Normal University, Huangshi Hubei)
Abstract: With the continuous increase of education data, the achievement data keeps accumulating, and most of these data cannot be fully utilized, resulting in a waste of education data. Therefore, it is necessary to use data mining technology to mine the valuable information hidden in the data.
In this study, the course scores of 2016 undergraduate educational technology students of a university were used as the research object. The model of K-means and Apriori algorithms was constructed using SPSS Modeler , and the scores of the courses were deeply excavated and analyzed. Through detailed analysis of the mining results, it helps teaching managers to arrange courses and make teaching plans, thereby improving the quality of teaching and learning.
Key words: data mining; K-means algorithm; apriori algorithm
一 引言
伴随高等教育招生规模越来越大,教育数据不断增多。面对积累的教育数据,教学管理人员一般是对数据的简单整理,例如平均分、合格率等的计算,不能对隐含在成绩数据中有价值信息进行有效的提取与分析。对教育数据进行资源化、知识化 , 正确运用数据的分析结果并进行准确的分析和预测 , 有利于教育管理的可持续发展 [1]。
二 理论基础
数据挖掘是指从海量的、不完整的实际应用数据中,提取隐含在其中人事先不知道的,但又可能有用的信息和知识的过程 [2]。挖掘的结果既能判断学生的学习状态,提高学生的学习成绩, 又能为课程的设置提供有效的额外信息 [3],从而提高教学质量。本研究将采用数据挖掘技术中的K-means 和 Apriori 算法对学习成绩和课程之间的关系进行研究。
K-means 算法是一种经典的聚类分析算法, 通过公式计算每个数据对象到聚类中心的距离, 并划分到最近的类中,不断迭代更新中心点,使得中心距离稳定在某个数字,输出聚类结果。计算公式如(1)所示
一般把欧式距离作为计算距离的公式,即q=2。聚类中 k 值通常根据相应领域的背景知识并结合实际情况确定,通常取 k=2 至 7 的数值 [4]。
关联规则即从大量数据中寻找项集之间的关联性 [5],Apriori 算法是关联规则中最典型算法 [6]。关联规则评价使用支持度和置信度两个指标进行度量,支持度(S)是数据集 D 中同时包含项集A 和项集 B 的事物个数占总事物总数的百分比, 是用户规定的关联规则必须满足的 min sup 记作S(A=>B),如公式(2); 置信度(C)是指物数据集 D 中同时包含 A 和 B 项集的事物个数占包含事物 A 个数的百分比,是用户关联规则必须满足的min con,记作 C=(A=>B) 如公式(3)。
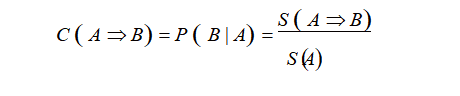
(2)聚类结果分析
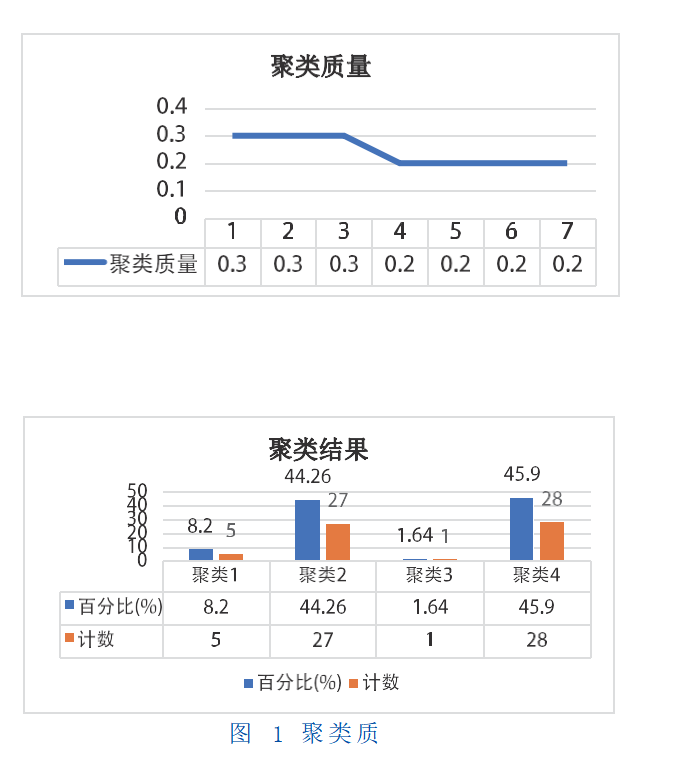
k=4 时 , 聚类结果如图 2 所示。
观察图 2 发现:聚类 1 数值为 5,占总数的Apriori 算法的思想是找到数据集中的强关联规则,即在关联规则中,支持度和置信度都大于等于 min sup 和 min con。需要注意的是 Apriori 算法是基于 Boolean 关联规则的挖掘算法 [7],因此需要将数据转换为布尔型数据。
三 挖掘过程以及结果分析
(一) 数据来源
研究数据来源于某高校 2016 级教育技术学专业 6 个学期的 57 门课程考试成绩,确定数据后对数据进行整合、清理:将课程数据中的通识教育类课程进行删除,例如:形式与政策,思想道8.2%,这类学生属于成绩一般的,占的比重较小, 因此教师对该类学生进行个性化的指导,以提高学生成绩;聚类 4 占总人数的 45.9%,这类学生学习成绩良好,属于初级成绩的中等层次,由于该类学生人数较多,因此要加大对这类学生的关注。观察聚类结果发现该班级整体成绩质量比较好。
区别于传统的成绩划分方法,将聚类均值作为划分学生的成绩等级的依据,这样会使学生的评价更为客观,更具有说服力。每个聚类各个科目学生成绩情况如表 1 所示:教师可以获取不同科目的成绩分布情况,学生的重视程度和掌握情况。
(二) 基于聚类算法的学习成绩分析
(1)k 值的选取
研究中 k 值的选取是根据学生的成绩分布情况和样本的数量确定 [8], 初步选取值 k=2-7, 每运行一次记录一次聚类质量,绘制折线图 1。发现当 k=4 时,聚类质量进行下降,因此选此拐点, 作根据得到的结果,关注重点课程,适当增加比较重要的课程的学时,安排教学经验较丰富的教师承担教学任务。比如对于下一届该专业的学生的课程安排中,可以重点关注图 3 中变量重要性数值大的课程。
观察折线图,发现同一门课程,不同聚类具有不同的数值。通过分析聚类的结果,学生可以确定自己所处的类别,以及与其他学生的相差程度,此外学生还可以根据聚类结果,发现自己擅长哪些科目,哪些科目比较落后。
(三) 基于关联规则的学习成绩数据挖掘
图 4 成绩均值折线图使用 SPSS Modeler 软件对 Apriori 算法建模, 深入分析学生的课程成绩数据,挖掘课程(1)成绩数据离散化成绩数据离散化:将课程成绩根据聚类结果分为四个等级:优秀、良好、中等、合格,分别
对应 a、b、c、d。以数据库课程为例,通过聚类获得四个聚类中心 [82.2,87,69.2,60],根据成之间绩形成的四个聚类划分课程等级:将 [86,100] 的成绩编码为 a,[77,85] 成绩编码为 b,[65,76] 成绩编码为 c,[0,64] 为 d,如表 2;根据课程成绩等级分类情况,对学生本人课程成绩进行编码: 将学生的实际成绩和表 2 的成绩进行对比,划分学生本人成绩所处的类别,并将其编码为 1 如表 3。
(2)关联挖掘结果分析
在 SPSS Modeler 软件中随机设置最低条件支持度、最小规则置信度和最大前项数。发现当前项数为 5 的时候,规则数已经稳定不变。观察关联规则发现关于高级语言程序设计的关联规则占绝大多数。为了验证上述说法,研究通过改变支持度和置信度进行试验,发现尽管设置的支持度和置信度不同,该课程的关联规则都占绝大多数, 最低达到 63%,最高得到了 100%,见折线图 5。
为了避免规则太少导致分析事物不够全面, 或者规则太多分析不透彻。研究对图 5 中参数设置和规则个数综合分析,最终设置 min sup=30.0, min con=80%,前项数为 5,得到 52 条关联规则。按照顺序将规则进行编码 1-52,在此仅列举对结果影响比较大的规则。
观察 52 条关联规则发现高级语言程序设计课程的规则达到 40 条,约占总规则的 77%,表明该课程的重要程度。由于高级语言程序设计课程与多个课程有关联,可见其综合性很强。而且该课程是计算机类相关专业的专业基础课程,该课程成绩的高低从一定程度上反映了学生的综合能力和水平 [9]。因此学校应该高度重视该课程的学习。观察规则 1 发现面向对象程序的设计与高级语言程序设计的成绩的支持度达到 41.94,置信度达到100%,得出两门课程的关联性最强,从两者的决定关系看,面向对象程序设计 => 高级语言程序设计。观察关联规则 1,2 发现面向对象的程序设计和高等数学均影响高级语言程序设计,对应规则23;观察规则 18 发现面向对象程序设计会影响高等数学成绩。得出:面向对象程序设计 => 高等数学 => 高级语言程序设计。
观察规则 12 发现平面动画制作与高级语言程序设计支持度达到 48.39,从整个规则看,51 条规则中 10 条规则涉及到平面动画制作课程,约占总数的 20%,得出平面动画制作与高级语言程序这两门课程相关性较强。从规则 50 和 51 发现面向对象程序设计、高等数学、高级语言程序设计和平面动画制作这四门课程联系紧密,从关联规则 39,40 发现平面动画制作影响高等数学,从规则 44 和 51 进一步确定平面动画制作影响面向对象程序设计。得出:平面动画制作 => 面向对象程序设计 => 高等数学 => 高级语言程序设计。
观察规则 32,39 发现大学物理影响高等数学、线性代数,从规则 22 发现高级语言程序设计的成绩会影响大学物理,其支持度达到了 40.32,得出高等数学影响高级语言程序设计,结合规则 33 得出大学物理,高等语言程序设计和平面动画制作三者联系紧密。因此:平面动画制作 => 面向对象程序设计=> 高等数学 => 高级语言程序设计 => 大学物理。 观察规则 17 发现线性代数的成绩会影响高级语言程序设计,支持度达到了 43.55,观察规则26,当高等数学和线性代数都为优秀时,高级语言程序设计课程的成绩也为优秀,置信度达到了94.74%。综上得出:线性代数与高等数学和高级语言程序设计联系较为紧密。
观察规则 4,5 发现教育技术研究方法的成绩会影响多媒体技术基础和 Internet 基础和应用,因此在开设三门课程之前可以先进行教育技术研究方法的教学。
观察规则 8 发现多媒体技术基础的成绩会影响数据库原理及应用;观察规则 34 发现两者的支持度和置信度相等,得出两门课程互相影响,因此建议这两门课程可以同学期进行开设,学生可以进行互补学习。
四 总结
本研究利用数据挖掘软件通过对 K-means 和Apriori 算法建模,挖掘课程成绩中潜在的有价值的知识和信息。得出的结论可以使教育工作者了解不同课程重要程度以及不同课程之间的关联性和影响程度,进而提高学生学习成绩,并对课程的安排, 教学计划的改进提供指导和借鉴意义。此外,本研究对于课程成绩的研究思路以及数据挖掘的思想也可以为教育管理工作者提供一定的借鉴。
参考文献
[1]张圆圆 . 基于数据强国架构的教育数据治理 [J]. 教育现代化 ,2018,5(32):142-145.[2]
韩家炜, 堪博. 数据挖掘: 概念与技术[M]. 范明, 孟小峰, 译.3 版 . 北京 : 机械工业出版社 ,2012: 186-188.
[3]张甜 , 尹长川 , 潘林 , 等 . 基于改进的聚类和关联规则挖掘的学生成绩分析 [J]. 北京邮电大学学报 ( 社会科学版 ),2018,20(02):91-96.
[4][8] 付希 . 基于蚁群算法的聚类分析在学生成绩评价中的应用研究 [D]. 成都 : 西南交通大学 , 2013.
[5]马志新 . 频繁项集挖掘问题的研究 [D]. 兰州 : 兰州大学 ,2005:16-18.
[6]敖希琴,费久龙,陈家丽 . 基于关联规则的高校学生成绩分析研究 [J]. 教育现代化,2017,4(45):240-244.
[7]严的兵 . 基于数据挖掘的学生成绩分析 [D]. 合肥 : 安徽大学 ,2011:5-8.
[9] 苑俊英 .《高级语言程序设计》课程成绩分析 [J]. 教育现代化 ,2019,6(17):86-90.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jiaoyulunwen/32337.html