SCI论文(www.lunwensci.com):
摘 要: 本文论述了通过后结构化技术对文本病历进行处理,改善计算机对文本病历的理解能力,解决基于文本病历难以开展大规模的医疗质控、临床决策支持、临床科研、医疗大数据应用的难题。该技术的重点是采用自动训练方法对大批量病历进行学习辅以人工审核校对构建一个医学语料库,在此基础上对需要抽取的病历进行句法分析、实体识别标注、信息抽取和组织,最终将抽取到的信息组成树状结构,以 XML 文件的格式进行存储。
关键词: 电子病历;文本病历;结构化病历;后结构化;信息抽取
本文引用格式:陆鹏, 刘金星. 具有自学习能力的电子病历后结构化技术研究[J]. 世界最新医学信息文摘,2018,18(73):192-193.
0引言
随着医疗信息化建设的逐步推进,大多数的医院应用了电子病历系统。按照录入及存储分类,电子病历主要包括结构化电子病历、非结构化电子病历及半结构化电子病历。结构化电子病历系统采用结构化录入,避免了用词的随意性, 为后续的数据收集、研究提供了方便。然而,结构化录入也存在一些弊端,如不符合医生病历书写习惯,书写效率低, 无法满足医生工作忙碌追求高效的需求;结构化病历模板维护工作复杂,不同科室、不同病种甚至同一病种不同疾病分组都要使用不同的病历模板,在一些病种细分不足的科室如儿科、内科难以实现为全部病历设置相应的模板;病历模板结构雷同,限制医生临床思维表达,在书写主诉、现病史、病程记录时尤为明显。上述问题的存在,导致很多医院即使使用了功能上支持全结构化录入的电子病历系统,但是医生往往还是习惯采取自由文本或半结构化录入的方式来完成日常病历书写工作 [1]。
1问题的提出
同时,很多医院存在着大量的历史文本病历,部分病历甚至是采用 Word 等文本编辑工具来编辑书写。这些文本病历的颗粒度难以支撑后续的病历数据利用(如医疗质控、临床决策支持、临床科研等),限制了医疗大数据的应用。如何通过对文本病历的语义标注、数据抽取、知识发现来支撑病历数据的二次利用成了很多医院当前迫切需要解决的问题。
本研究采用后结构技术来解决上述问题。后结构化技术是指以医学信息学为基础,采用医学本体知识及自然语言理解人工智能技术,对以自由文本方式录入的医疗文书按照医学术语规范、病历书写规范进行结构化分析,将病历非结构化信息转换为结构化信息的一种手段。通过后结构化技术, 抽取出文本病历中的关键词如症状、体征、手术、诊断、检验指标结果等信息,并按照医学逻辑进行分类组织,不仅可以直接展现给用户,还可以实现计算机自动识别,为进一步的信息处理及利用如病历语义检索、数据查询、数据挖掘等打下基础 [2-5]。
2后结构化设计方法
后结构化设计主要有两大方法:一是知识工程方法(Knowledge Engineering Approach),二是自动训练方法(Automatic Training Approach)。
知识工程方法主要靠手工编制规则使系统能处理特定知识领域的信息抽取问题,这种方法要求编制规则的知识工程师对该知识领域有深入的了解。自动训练方法不一定需要如此专业的知识工程师,系统主要通过学习已经标记好的语料库获取规则,任何对该知识领域比较熟悉的人都可以根据事先约定的规范标记语料库,经训练后的系统能处理没有识别过的新文本,这种方法要比知识工程方法快,但需要足够数量的训练数据,才能保证其处理质量。在病历中需要抽取的信息包括了时间、疾病、症状、手术、病因、体征、药品、手术、转归等多种复杂属性,医学术语量非常庞大。在研究中,考虑到医学的专业性和特殊性,我们综合了知识工程方法和自动训练方法两种方式的应用 [6-8]。首先,我们寻找能够引用的标准医学术语集,包括 ICD-10 疾病诊断编码、ICD-9-CM-3 手术编码以及 SNOMED CT 医学术语库,将这些术语进行统一维护,便于后续在进行句法分析时识别文本病历中的术语。
然而,仅仅由这些标准术语并不能完全解决问题,因为医生在书写病历时往往并不遵循标准字典,如医生使用的诊断术语可能与 ICD-10 不完全一一对应。因此我们进一步采用自动训练方法从大量的病历中学习医生的常用术语表达, 并将学习到的内容加入到语料库,使语料库能够自我学习、自动更新、不断丰富,从而未为后结构化分析提供更加强大语料库的支持。很多大型医院存在的海量病历为自动训练方法的应用提供了有利的基础。在自动训练的方法实施前,我们首先对病历的描述和表达进行分析,我们对病历进行分析研究发现病历中存在着大量的词对,如“神志——清楚”“营养——中等”“精神——良好”。我们对从海量病历中抽取出词对,对这些词对的描述出现频率进行自动排序,由人工审核后加入语料库。在此过程中需要识别哪些是同义词描述, 如“神志清”和“神志清楚”往往是同一意思,由人工进行同义词标注后加入语料库。对于一些出现频率比较低的描述一般是由于医生书写不规范或笔误造成,也需要由人工审核排除,最终生成一个学习后的、符合医生日常描述习惯的、规范的语料库。学习的越多、语料库越丰富,后期基于语料库进行信息抽取的准确率就越高 [9-10]。
3后结构化分析基本流程
后结构化技术对自由文本病历的分析通常使用自然语言处理技术,其抽取规则主要建立在词或词类间句法关系的基础上。后结构化技术根据预先定义的模板,从文本病历中抽取特定的信息并形成结构化的数据,并组织成树状结构。模板定义的颗粒度越细,需要识别和抽取的内容越多。总体来说, 后结构化分析需要经过的处理步骤包括:文本划分、句法分析及语义标注、抽取和填充模板。
3.1文本划分:
将文本病历进行分段,主要参考国家卫生计生委发布的《电子病历基本数据集》进行分段,如将入院记录划分为:患者基本信息、主诉、现病史、既往史、体格检查等段落。在此过程中,我们主要是通过关键词识别来划分文本[11]。
3.2句法分析:
通过一个或多个步骤的句法分析,识别文本中的各种语法结构,完成各类实体的识别,如症状、体征、诊断等,这是一个比较关键的过程。我们将关键词匹配和自然语言处理(NLP,Natural Language Processing)两种技术有机融合来实现对各类实体识别。关键词定位简单高效, 而且准确率比较高,但在一些情况下仅仅通过关键词来识别不能达到要求,如鉴别出现病史中哪些是发病症状、哪些是否定症状,又比如鉴别出主诉中的主要症状、伴随症状以及各自的发病时间,这些情况完全依赖于关键词就无法解决问题,需要通过 NLP 来对句法进行上下文语义分析。我们采用语料库对文本病历进行标注,将一切看成名字的组合,将文本病历的结构化问题转变为带标序列的学习问题,最终完成对语义的准确理解。
3.3抽取:
按照预先定义的模板确定抽取任务及要求,利用抽取模式识别文本中的实体间的关系,将相应的信息抽取出来,以完成具有实体关系的抽取任务。
3.4模板生成:
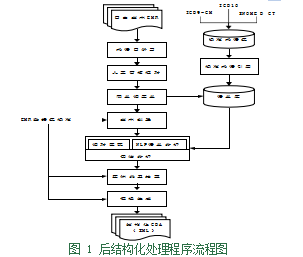
依据已抽取到的信息自动生成相应的结构化病历模板,并将之前抽取到的信息对模板进行填充,形成完整的信息文档描述架构,完成模板填充任务。本文研究的模板采用树状的结构设计, 用节点和分支节点来对结构化信息进行合理组织,采用 XML(Extensible MarkupLanguage)即可扩展标记语言作为数据存储语言。XML 语言是一种元标记语言,具有很好的扩展性,元标记之间可以层叠嵌套,能够准确描述出各个节点之间的关系。后结构化处理最终将信息抽取结果输出到 XML 格式的 CDA(Clinical Document Architecture)即临床文档架构文件中 [12],后结构化处理程序流程如图 1 所示。
4后结构化技术应用效果
该项技术已在国内多家医疗机构应用。采用后结构化技术为文本病历的数据二次利用提供了技术基础,可以有效解决医院面临的下述问题:①历史存留的大量文本病历甚至是Word 编辑的病历无法利用的问题;②建设数据中心时,医院文本电子病历系统数据不能满足标准化数据中心颗粒度要求的问题 [13];③医生书写病历时不采用全结构化模板书写导致数据后续无法二次利用的问题;④文本病历不能满足病历质控、医疗质控、疾病监控、院内感染监控、临床科研等医疗大数据利用需求的问题,图 2 显示文本病历后结构化处理效果。

图 2 文本病历结构化处理效果
后结构化技术现实了对文本病历信息的结构化抽取,数据的利用不依赖于对医务人员的病历全结构录入,对医务人员的录入方式不做要求,兼顾医生病历书写效率的同时解决了数据二次利用的问题,同时也为医院历史病历数据在统计、科研等方面的二次利用提供了技术基础。该技术的应用有效地改善了计算机对文本病历的理解能力,解决了基于文本病历难以开展大规模的临床科研、统计分析、医疗大数据利用等难题 [14-15]。
参考文献:
[1]李毅 , 保鹏飞 , 薛万国, 等. 中文电子病历的信息抽取研究 [J]. 生物医学工程学杂志,2010,27(4):758-762.
[2]刘丹红 , 张林 , 杨喆 , 等. 医学语言与临床数据标准化概述 [J]. 中国卫生信息管理杂志 ,2014,11(1):14-17.
[3]李昊曼, 段会龙, 吕旭东 , 等. 医学语言处理技术及应用 [J]. 中国数字医学,2008,3(11):11-13.
[4]李昊 , 李莹, 段会龙, 等. 中文病历文档的术语提取和否定检出方法[J]. 中国生物医学工程学报 ,2008,27(5):716-721.
[5]李俊杰. 基于最大熵原理的医疗文本信息结构化 [J]. 临床医学工程 ,2010,17(10):119-121.
[6]徐一新, 应峻 , 董建成. 医学信息学的发展 [J]. 中国医院管理,2006,26(3):30-32.
[7]肖强, 吴伟斌 , 陈联忠, 等. 自由结构录入法在电子病历系统中的应用 [J].解放军医院管理杂志 ,2005,12(3):222-228.
[8]刘知远 , 崔安欣. 大数据智能 : 互联网时代的机器学习和自然语言处理技术[M]. 电子工业出版社 ,2016.
[9]王祥配 , 宋毅鹏, 何丽云. 医院病历信息数据化的路径与方法研究[J].世界科学技术- 中医药现代化 ,2015,17(2):389-393.
[10]吴嘉伟, 关毅 , 吕新波. 基于深度学习的电子病历中实体关系抽取 [J].智能计算机与应用 ,2014,4(3):38-40.
[11]苏韶生, 余元龙, 程敏婷. 半结构化病历文档信息抽取应用 [J]. 中国数字医学,2012,07(9):23-25.
[12]李伟. 非结构化病历文档结构化转换方法研究 [D]. 河北工业大学,2013.
[13]陈莺莺. 病历信息抽取方法的研究与实现 [D]. 浙江工业大学,2010.
[14]李莹. 文本病历信息抽取方法研究 [D]. 浙江大学生物医学工程与仪器科学学院 ,2009.
[15]陈艳慧. 中文病历文本的信息抽取与结构化研究 [D]. 中国人民大学,2011.
《具有自学习能力的电子病历后结构化技术研究论文》附论文PDF版下载:
http://www.lunwensci.com/uploadfile/2018/1116/20181116030223941.pdf
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/yixuelunwen/1653.html