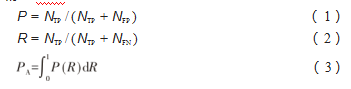摘要:针对电子产品玻璃边缘表面的电极区域与非电极区域深加工过程中产生的大划伤、小划伤、划痕、异物等缺陷,提出了一种基于改进的YOLOv7的玻璃表面缺陷小样本检测方法。首先,在主干网络中加入卷积注意力模块(Convolutional Block Attention Module,CBAM)提高了通道注意力与空间注意力,解决了玻璃表面缺陷面积较小、在图像中分布差异较大、提高卷积神经网络在缺陷区域学习鲁棒性的特征表示的问题。其次,考虑到工业生产过程中缺陷样本较少、样本量不均衡,采用随机高斯噪声、Mixup、随机填充图像和随机拼接等图像增强方法,将样本进行扩充,并使样本均衡化。最后,将增加一个预检测头用于细长且轻浅的划痕检测,结合其他3个预测头,四预测头结构可以有效缓解过大差异对象带来的尺度方差引起的负面影响。实验结果表明,改进的YOLOv7算法相较于原始算法,平均精度提高了6.15%(mAP),检测效果优于当前YOLOv7网络,在一定程度上提高了工业生产过程中玻璃表面缺陷的小样本检测精度。
关键词:YOLOv7,玻璃表面缺陷检测,卷积注意力模块
0引言
随着电子工业生产的不断发展,玻璃表面作为电子产品的电极承载区域被广泛使用。在玻璃表面电极区域与非电极区域深加工过程中,往往会产生各种缺陷,例如在手机玻璃的生产和加工过程中,机器故障、设备不当操作、磨具磨损、材料质量、运输和处理、使用环境、异物污染等原因将产生大划伤、小划伤、划痕、异物等缺陷。这些缺陷不仅会降低产品质量,还可能导致产品的早期损坏和不稳定性。因此,精确且高效地检测这些表面缺陷对于保证产品质量和提高生产效率至关重要。
传统的玻璃表面电极区域与非电极区域缺陷检测方法通常依赖于人工视觉检查,即通过人眼对样本进行观察和判断。然而,人工检查方法存在一系列不可忽视的问题,如:人力成本相对较高,需要训练有素的专业人员,从而增加了企业的运营成本;人工检查的效率较低,尤其在大规模生产场景下,难以满足快速检测的需求,人的主观性在评估缺陷的程度和类型时可能会导致不一致的结果,从而影响了检测结果的可靠性和一致性。所以人工检测限制了其在实际应用中的可行性和效率。
近年来机器视觉的快速发展为解决这些问题带来了新的希望。特别是在计算机视觉领域,目标检测方面的深度学习方法取得了巨大的突破。此类方法的基本原理是首先构建图像视觉表示模型,然后将该模型在带有标签的训练数据集中进行训练,确定算法的模型参数,最后在测试数据集中验证算法的优劣性。从视觉特征表示角度看,基于视觉的玻璃表面电极区域与非电极区域缺陷检测方法大致上可分为两类:基于传统视觉图像处理算法[1-4]和基于深度学习特征[5-7]。传统图像处理算法指人们根据图像的颜色、灰度值、纹理、边缘等像素分布的特点,构建多种视觉特征表达模型,例如灰度值分布直方图[3]、局部纹理分布图、局部二值模式[4]等。传统图像处理算法由于特征表示简单,因此在实际应用中多为对特征组合筛选,以达到表达特征的效果。例如,王飞等[8]提出读入图像后进行滤波除噪、图像灰度化、边缘检测与跟踪、阈值分割、亚像素定位进行寻找玻璃表面缺陷。郑天雄等[9]提出根据缺陷在不同照明下的灰度纹理差异计算灰度、几何特征等一系列相对偏差特征。深度学习特征指通过深度神经网络模型对图像建立视觉特征表达,其广泛应用的神经网络模型为深度卷积神经网络[10]。目标检测类代表算法主要有YOLO[11]、SSD[12]、YOLOv2[13]、YOLOv3[14]、YOLOv4[15]、YOLOv5、YO⁃LOv6[16]、YOLOv7[17]等。模型主要通过卷积层、池化层、激活层、全连接层创建深度学习神经网络模型进行图像分类,底层卷积层提取局部浅层视觉特征,高层卷积层提取丰富的全局语义特征。与传统视觉图像处理算法不同,深度学习模型特征表达是从图像像素中学习具有判别力的特征,其特征表达与训练数据密切相关,而传统视觉图像处理算法只与特征组合有关。例如,熊红林等[18]提出使用多尺度卷积神经网络MCNN、使用softmax分类器,通过混淆矩阵和FI(准确率与召回率的调和平均值)值来评估学习器技能。Acciani等[19]提取测试图像中感兴趣区域的特征,然后构建多层神经网络进行缺陷检测。Zhi Yangyu等[20]提出一种可重复使用的高效率两阶段深度学习的工业环境下的表面缺陷检测方法。Feng等[21]提出一种深度主动的学习系统来最大化模型识别性能。Ren等[22]提出一种基于深度学习的通用表面缺陷检测方法,该方法的创新点在于只需要很小的数据集。所有这些方法虽然都取得了很好的效果,但是误判、漏判情况较为严重。
总之,近几年非常优秀的目标检测网络在产品质量检测,尤其是玻璃表面缺陷检测上的应用研究较少[23-26]。
首先,玻璃表面电极区域与非电极区域缺陷的采集相对困难,涉及到大量的人力和时间,导致数据集规模有限。其次,由于工业生产过程中缺陷样本较少且样本量不均衡,传统的深度学习目标检测算法在这种小样本场景下往往表现不佳,容易产生过拟合等问题。这使得直接将YOLO算法应用于手机玻璃缺陷检测任务存在一定的挑战。
为了解决这些问题,本文提出了一种基于改进的YOLOv7算法的玻璃表面缺陷小样本检测方法。该方法充分利用了YOLOv7的优势,结合卷积注意力模块(CBAM)、图像增强技术以及多检测头检测机制,以提高对小样本、不均衡样本的检测效果。方法具有以下几点创新。
(1)为了解决玻璃表面电极区与非电极区域缺陷面积较小、在图像中分布差异较大的问题,在YOLOv7的主干网络中加入了卷积注意力模块(CBAM)。CBAM可以自适应地学习图像中不同区域的特征权重,从而提高卷积神经网络在缺陷区域学习鲁棒性的特征表示,有效提高了检测的精度和鲁棒性。
(2)考虑到工业生产过程中缺陷样本较少且样本量不均衡的情况,采用了多种图像增强方法,包括高斯噪声[27]、Mixup[28]、随机填充图像[29]和随机拼接[30]等,对样本进行扩充和均衡化。这样做不仅增加了训练数据的多样性,还可以有效缓解小样本场景下的过拟合问题,提高了模型的泛化能力。
(3)针对细长且清浅的划痕等难以检测的缺陷,增加了一个额外的预检测头,使得改进的YOLOv7模型由原来的3个检测头结构变为4个检测头结构。这种设计可以有效缓解过大差异对象带来的尺度方差引起的负面影响,提高对细小缺陷的检测准确率。
本文通过大量实验验证了改进的YOLOv7算法在玻璃表面缺陷检测上的有效性。实验结果表明,相较于原始算法,该方法平均精度提高了6.15%(mAP),检测效果优于当前YOLOv7目标检测网络。因此,相信这项研究将在一定程度上提高工业生产过程中玻璃表面缺陷的小样本检测精度,为提高产品质量和生产效率提供有力的支持。
通过本文的研究,对于改进目标检测算法在小样本场景下的应用有了更深刻的理解,并且也为其他领域中的小样本问题提供了一种可行的解决思路。希望本文的工作能够对相关领域的研究和应用产生积极的影响。
1数据集的采集与制作
1.1实验数据采集
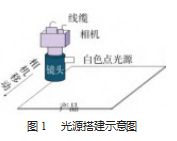
实验数据采集于电子产品玻璃生产现场,采用MV-CS032-10GM的320万像素、像元尺寸为3.45μm、分辨率矩阵为2 048像素×1 536像素相机。镜头选用型号为WWH05-110CT的0.5X远心镜头,可接点光,放大倍率为0.5X,光源选用直径为25 mm,光源功率为3W的JL-DL25-3W白色点光,视野为14.131 2 mm×10.598 4 mm,工作距离为110 mm固定距离,光源控制器选用JL-DSL-3W-2光源控制器,光源搭建方案分别如图1、图2所示。
本文首先进行产品的批量采集,经过数据清洗,将失焦、抖动、曝光、模糊的图片给去掉。数据集中主要包含大划伤、小划伤、划痕、异物4类传统的玻璃表面电极区域与非电极区域缺陷图片,4种类型的样本数量分别为1 048、1 432、1 947、986张,样本实例如图3所示。
1.2图像处理与数据标注
当前采集的数据大小为2 048像素×1 536像素,考虑到后续图像检测速度与训练速度,本文将所有图像大小进行重新resize并做归一化处理,将图片像素更新为1 500像素×1 500像素,作为直接训练数据,采用La⁃belme数据集标注工具对样本图像进行标注,标注格式为COCO格式。
1.3数据增强
本文每张图片分辨率大小为1 500像素×1 500像素,虽然采集数据集时尽量保证玻璃表面电极区域与非电极区域缺陷样本的数量均衡,但是由于产品的类型不同,所产生的同一缺陷种类的形状、大小、数量也各不相同,如果玻璃表面电极区域与非电极区域缺陷检测模型直接在该数据集下训练,可能导致在样本较少的数据集类型下性能表现较差。
为解决样本数据较少且不均衡所导致的模型性能下降这一问题,本文将采用多种类型数据增广,将每种类型的数据集进行扩充。首先,本文通过高斯噪声、Mix⁃up、随机填充图像和随机拼接图像增强方法对图片进行扩充,图4所示为数据集增强效果,增强后大划伤、小划伤、划痕、异物4类传统的玻璃表面电极区域与非电极区域缺陷图片样本数量分别为5 240、7 160、9 735、4 930张,总计27 065张。
为了减少数据集划分对本实验的影响,本文采用hash算子[31]进行样本随机划分,将增广数据集按照7∶2∶1比例分成训练集、验证集和测试集,采用交叉验证的方式进行验证。
2基于改进YOLOv7的目标检测算法
2.1 CBAM注意力模块
在图像信息处理、语音识别和自然语言处理等多个应用领域,注意力机制都得到了广泛的使用,这是一种信息处理的方法[32]。研究表明,注意力模块(Atteihion Mecharnism)的引入能在一定程度上提升目标网络模型的表示能力,在目标检测任务中,这能有效减少无效目标的干扰,从而提高对焦目标检测的效率[33]。
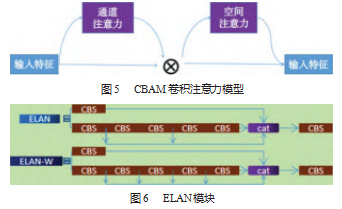
在本项目中玻璃表面电极区与非电极区域缺陷面积较小、在图像中分布差异较大,且同一类中形状也差异较大,为了使卷积神经网络集中在玻璃表面电极区与非电极区域缺陷学习鲁棒的特征表示,所以本文在YO⁃LOv7网络Head的高效层聚合网络层(ELAN)中引入注意力机制(Convolutional Block Attention Module,CBAM)[34]。CBAM由通道注意力(Channel Attention Module,CAM)和空间注意力(Spartial Attention Mod⁃ule,SAM)两个部分组成。如图5所示,输入一张尺寸为H×W×C的特征图,其中H、W、C分别指特征图的高度、宽度以及通道数。接下来,对其执行全局最大池化和全局平均池化操作,这些操作都基于水平和垂直的方向,通过这种方式,获得了两个1×1×C尺寸的特征图。这两个特征图各自进入一个包含两层的全连接神经网络,也就是通常提到的多层感知机。这个神经网络的第一层神经元的数目等于C除以r(r在这里表示压缩率),并且采用了ReLU激活函数。神经元的数量在第二层是C。对多层感知机产生的两个特征向量执行了元素加和运算,接着使其经过Sigmoid激活函数处理,从而获得了通道的注意力特征。然后,将此属性与输入属性进行元素级别的相乘,然后将产生的效果输入到空间注意力子模块中。再利用空间注意力子模块产生的特征图以全局最大值池化和全局平均值池化操作这两种通道为基本的方式,对通道注意子模块生成的特征图进行了预处理,并获得了两张H×W×1尺寸的特征图。接着,把这两个特征图按照通道进行了拼接,也对它们进行了7×7的卷积操作,获得了一个H×W×1的特征图。经由Sigmoid函数对特征图进行激活处理后,得到了空间通道特征,并且将其与特征图进行了元素级别的运算,最终获得了需要的特征输出。本文将CBAM注意力模块放在Head的ElAN模块后,在ELAN模块进行多次卷积后进行特征表达能力的增强,ELAN模块如图6所示。
2.2多检测头优化
在目标检测网络模型中选择VGG[35]、ResNet[36]、DenseNet[37]、MobileNet[38]、EfficientNet[39]、CSPDarknet53[40]、Swin Transformer[41]等已经被证实在分类等任务上有极强特征抽取性能的常见主干网络,所以本文在YOLOv7的BackBone中使用原网络架构。主干网络并不具备执行定位任务的能力,而头部则负责通过从骨干网中提取的特征图来检测目标的位置和类别。头部通常分为两大类:一级目标检测器和二级目标检测器。二级检测器历来都是目标检测行业的主要策略选择,其中,最显著的代表就是RCNN系列[25-26]。相比之下,一级检测器则能够同时预测目标的边界框和种类。尽管初级检测器运行速度较快,但其精确度相对较低。但是随着深度学习的发展,一级目标检测器中以YOLO系列[11,13-17],SSD[12]和Reti⁃naNet[42]为代表。特别是YOLO检测器在YOLOv3后使用了3个预测头,其设计更加复杂,融合了不同的检测尺度和特征层级,使得模型在各种场景下有了更出色的表现。
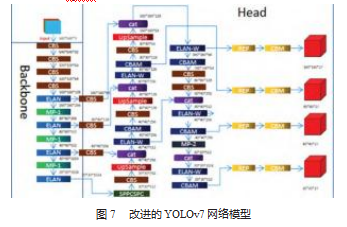
通过研究发现玻璃表面电极区域与非电极区域缺陷大划伤、小划伤、划痕区域缺陷部分为轻浅、细长的不规则缺陷,在卷积神经网络中通过对特征的提取很容易丢失特征信息,因此增加了一个预测头用于对清浅划痕的多级特征检测。结合其他3个预测头,四头结构可以有效缓解小样本场景下的过拟合问题。如图7所示,增加检测头后,虽然增加了计算量和内存开销,但对微小物体的检测性能有了很大的提高。改进的YOLOv7检测头模型中,20×20×27中的27代表(本文所使用的4类缺陷+预测框xywh坐标+置信度)×3个anchor。
3实验结果与分析
3.1实验平台
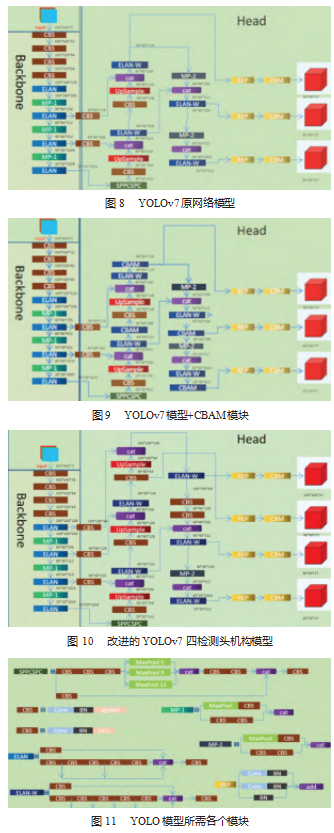
本实验基于Pytorch1.13.0框架,在Pycharm平台上进行,模型训练通过GPU加速,在Windows11、64位操作系统、NIVIDIA GeForce RTX3060、6 G显存、24 G内存、12th Gen Intel(R)Core(TM)i9-12900H 2.50 GHz处理器、CUDA11.6和CUDNN8.5环境下完成,编程语言为Python。本文分别采用原始YOLOv7模型、YOLOv7模型+CBAM模块、改进的YOLOv7四检测头机构模型、改进的YOLOv7模型+CBAM模块进行测试对比。图8为YOLOv7原网络模型,图9为YOLOv7模型+CBAM模块,图10为改进的YOLOv7四检测头机构模型,图11为YOLO模型所需各个模块。
3.2网络训练与测试
本次实验的评价指标为深度学习中的评价指标:精度(precision,P)、召回率(recall,R)、平均精度(av⁃erage precision,PA)、平均精度均值(mean average preci⁃sion,mAP)。其中精度P、召回率R、平均检测精度mAP公式为:
式中:NTP为已被准确效验出的目标总数;NFP为被错误地验出的目标数目;NFN为未被发现的目标数量;n为一共进行分类的类别数量;PA为目标类别的平均精确度。
3.3实验结果与分析
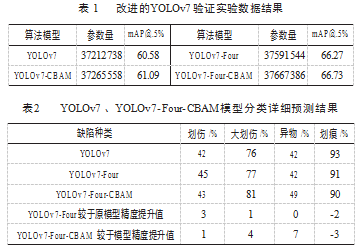
为了验证本文提出的改进YOLOv7的玻璃表面缺陷小样本检测模型的有效性,同时也为了与其他模型的数据进行比较,本文以YOLOv7模型为基础,将算法中是否加入CBAM注意力机制,是否更改检测头机构的4组算法分别称作YOLOv7、YOLOv7-CBAM、YOLOv7-Four、YOLOv7-Four-CBAM,使用同一组增强后数据集,将这4种算法进行实验对比,实验结果如表1和表2所示。
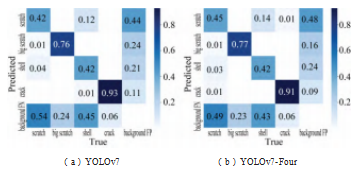
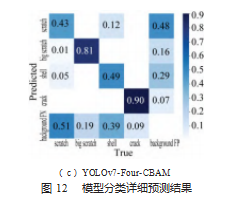
从表1中可以看出,通过在YOLOv7原模型基础上增加四检测头机构,模型的参数量没有发生显著变化,且模型的精度值提升了6.15%,说明了该改进算法的有效性。结合表1、表2可以看出,通过引进CBAM模块,与改进四检测头机构,模型的参数量没有发生显著变化,相较于四检测头机构,嵌入CBAM模块,模型精度值提升0.46%;四检测头机构提高了较于细长且轻浅的大划伤、小划伤精度值,分别为1%,3%;嵌入CBAM模块,使得小缺陷异物的精度值在原模型中提升7%,虽然划痕检测精度值有所下降,由于划痕检测精度较高,为93%,精度值降低3%,在可接受范围内,且算法仍然保持了较好的检测精度。图12为YOLOv7、YOLOv7-Four、YO⁃LOv7-Four-CBAM模型分类详细预测结果图。
具体大划伤、小划伤、异物实物检测精度提升对比图如图13所示。
4结束语
为实现在当前玻璃表面电极区域与非电极区域缺陷检测环境下,精度的提升,本文采集实际环境下电子产品玻璃生产流水线环境下图像,以YOLOv7为基础算法,引入CBAM机制,并增加多检测头机制,对模型进行改进,得出以下结论:改进YOLOv7的玻璃表面缺陷小样本检测模型YOLOv7-CBAM、YOLOv7-Four、YOLOv7-Four-CBAM在原YOLOv7模型上检测精度都得到了有效的提升,其中YOLOv7-Four-CBAM检测精度最好,在原来的基础上提升了6.15%,说明了该改进算法的有效性。其中相较于四检测头机构,嵌入CBAM模块,模型精度值提升0.46%;四检测头机构提高了较于细长且轻浅的大划伤、小划伤精度值,分别为1%,3%;嵌入CBAM模块,使得小缺陷异物的精度值在原模型中提升7%,虽然划痕检测精度值有所下降,由于划痕检测精度较高,为93%,精度值降低3%,在可接受范围内,且算法仍然保持了较好的检测精度。
参考文献:
[1]马鹏鹏,周爱明,姚青,等.图像特征和样本量对水稻害虫识别结果的影响[J].中国水稻科学,2018,32(4):405-414.
[2]景晨.基于无人机平台和图像处理的水稻感染稻纵卷叶螟虫害自动识别技术[J].农业开发与装备,2018(11):98-100.
[3]鲍文霞,邱翔,胡根生,等.基于椭圆型度量学习空间变换的水稻虫害识别[J].华南理工大学学报(自然科学版),2020,48(10):136-144.
[4]杨颖,文小玲,章秀华.基于方向梯度直方图和局部二值模式混合特征的水稻病虫害识别方法研究[J].河南农业大学学报,2021,55(6):1089-1096.
[5]黄双萍,孙超,齐龙,等.基于深度卷积神经网络的水稻穗瘟病检测方法[J].农业工程学报,2017,33(20):169-176.
[6]谭云兰,欧阳春娟,李龙,等.基于深度卷积神经网络的水稻病害图像识别研究[J].井冈山大学学报(自然科学版),2019,40(2):31-38.
[7]范春全,何彬彬.基于迁移学习的水稻病虫害识别[J].中国农业信息,2020,32(2):36-44.
[8]王飞,崔凤奎,刘建亭,等.基于机器视觉的玻璃表面缺陷检测系统的研究[J].玻璃与搪瓷,2009,37(5):6-10.
[9]郑天雄,冯胜,伍凯凯,等.一种平板玻璃表面缺陷检测方法[J].包装工程,2022,43(13):257-263.
[10]郑果,姜玉松,沈永林.基于改进YOLOv7的水稻害虫识别方法[J].华中农业大学学报,2023,42(3):143-151.
[11]REDMON J,DIVVALA K S,GIRSHICK B R,et al.You Only Look Once:Unified,Real-Time Object Detection.[J].CoRR,2015,abs/1506.02640.
[12]Wei Liu,Anguelov D,Erhan D,et al.SSD:Single Shot Multi⁃Box Detector[C]//European Conference on Computer Vision,2016:21-37.
[13]Redmon J,Farhadi A.YOLO9000:Better,Faster,Stronger[J].CoRR,2016,abs/1612.08242.
[14]Redmon J,Farhadia.YOLOv3:An Incremental Improvement[J].arXiv:Computer Vision and Pattern Recognition,2018.
[15]Bochkovskiy A,Wang Chienyao,Mark Liao.YOLOv4:Optimal Speed and Accuracy of Object Detection[J].CoRRabs/2004.10934(2020).
[16]Li Chuyi,Li Lulu,Jiang Hongliang,et al.YOLOv6:A Single-Stage Object Detection Framework for Industrial Applications[J].CoRRabs/2209.02976(2022).
[17]Wang Chienyao,Bochkovskiy A,Mark Liao.YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[J].CORR abs/2207.02696(2022).
[18]熊红林,樊重俊,赵珊,等.基于多尺度卷积神经网络的玻璃表面缺陷检测方法[J].计算机集成制造系统,2020,26(4):900-909.
[19]Acciani G,Brunettig,Fornarelli G.Application of neural net⁃works in optical inspection and classification of solder joints in surface mount technology[J].IEEE Transactions on Industrial In⁃formatics,2006,3(2):200-209.
[20]Yu Zhiyang,Wu Xiaojun,Gu Xiaodong.Fully convolutional net⁃works for surface defect inspection in industrial environment[C]//Proceedings of International Conference on Computer Vi⁃sion Systems.Berlin,Germany:Springer⁃Verlag,2017:417⁃426.
[21]Chen Feng,Liu Mingyu,Kao CC,et al.Deep active learning for civil infrastructure defect detection and classification[C]//Pro⁃ceedings of ASCE International Workshop on Computing in Civ⁃il Engineering.Reston,Va.,USA:American Society of Civil Engi⁃neers,2017:298⁃306.
[22]Ruoxu R,Terence H,Chen K T.A Generic Deep-Learning-Based Approach for Automated Surface Inspection[J].IEEE transactions on cybernetics,2018,48(3).
[23]LI Yiding,XIE Qingsheng,HUANG Haisong,et al.Research on surface defect detection based on faster R⁃CNN[J].Computer Integrated Manufacturing Systems,2018,25(8):1897⁃1907.
[24]Gupta S,Girshick B R,Arbelaez P,et al.Learning Rich Fea⁃tures from RGB-D Images for Object Detection and Segmenta⁃tion.[J].CoRR,2014,abs/1407.5736.
[25]Girshick B R.Fast R-CNN[J].CoRR,2015,abs/1504.08083.
[26]Ren S,He K,Girshick B R,et al.Faster R-CNN:Towards Re⁃al-Time Object Detection with Region Proposal Networks[J].CoRR,2015,abs/1506.01497.
[27]Narin A,Sengul D,Ozmen G K.Automated Classification of Brain Diseases Using the Restricted Boltzmann Machine and the Generative Adversarial Network[J].Engineering Applica⁃tions of Artificial Intelligence,2023,126(PA).
[28]Park M,Kim J.Self-Training with Entropy Based Mixup for Low-Resource Chest X-ray Classification[J].Applied Sciences,2023,13(12).
[29]Devries T,Taylor G W.Improved regularization of convolutional neural networks with cutout[J].arXiv preprint,2017:1708.04552.
[30]刘通,胡亮,王永军,等.基于卷积神经网络的卫星遥感图像拼接[J].吉林大学学报(理学版),2022,60(1):99-108.
[31]毕敬霖.基于离散量子游走的Hash函数构造研究[D].北京:北京工业大学,2019.
[32]Li B,Tang H,Ma D,et al.A Dual-Attention Mechanism Deep Learning Network for Mesoscale Eddy Detection by Mining Spa⁃tiotemporal Characteristics[J].Journal of Atmospheric and Oce⁃anic Technology,2022,39(8).
[33]张海镔,裴斐,雷帮军,等.改进YOLOv7的复杂环境下铅封小目标检测[J/OL].计算机工程与应用:1-12[2023-08-15].http://kns.cnki.net/kcms/detail/11.2127.TP.20230706.1213.024.html
[34]Woo S,Park J,Lee J Y,et al.CBAM:convolutional block atten⁃tion module[M].ComputerVision-ECCV 2018.Cham:Springer International Publishing,2018:3-19.
[35]Karen S,Andrew Z.Very deep convo-lutional networks for large-scale image recognition[J].arXivpreprint arXiv:1409.1556,2014.
[36]He K,Zhang X,Ren S,et al.Deep Residual Learning for Image Recognition[J].CoRR,2015,abs/1512.03385.
[37]Huang G,Weinberger Q K.Densely Connected Convolutional Networks[J].CoRR,2016,abs/1608.06993.
[38]Andrew G Howard,Zhu Menglong,Bo Chen,et al.Mobilenets:Efficient convolu-tional neural networks for mobile vision appli⁃cations[J].arXivpreprint arXiv:1704.04861,2017.
[39]Tan M,Le V Q.EfficientNet:Rethinking Model Scaling for Con⁃volutional Neural Networks[J].CoRR,2019,abs/1905.11946.
[40]Wang C,Mark Liao,Pingyang Chen.CSPNet:A New Back⁃bone that can Enhance Learning Capability of CNN[J].Comput⁃er Vision and Pattern Recognition,2019.
[41]Wang Ze,Lin Yutong,Cao Yue.Swin transformer:Hierarchical vision transformer using shifted windows[J].arXiv preprint arX⁃iv:2103.14030,2021.
[42]Priya G,Ross G.Focal Loss for Dense Object Detection[J].IEEE transactions on pattern analysis and machine intelligence,2020,42(2).
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/78151.html