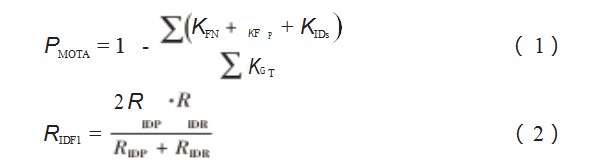SCI论文(www.lunwensci.com)
摘要:跟踪技术是自动驾驶领域非常重要的一种技术。为解决复杂场景下跟踪行驶车辆时产生的目标形变、外观相似等问题,提出了一种结合注意力机制与多层特征融合的多目标跟踪算法。该算法采用ResNe作为主干网络,在特征提取过程中采用特征金字塔网络结构来融合不同网络层级的目标特征。通过在主干网络中添加Coordinate Attention注意力模块来获得更加准确的位置信息,同时在特征金字塔层中使用可变形卷积来适应目标形变的特征提取。在公开数据集UA-DETRAC上进行的对比实验结果表明,改进算法在UA-DETRAC测试集上的多目标跟踪准确率为67.03%,比原ResFPN主干网络提高了4.91%,且跟踪速度为35.87 f/s,能够满足视频帧实时处理的速度需求。因此所提算法具有较好的跟踪效果和实时性。
关键词:多目标跟踪;协调注意力机制;特征金字塔网络;可变形卷积网络;残差网络
Vehicle Tracking Algorithm Based on Attention Mechanism and Multi-layer Feature Fusion
Lu Xiaotian,Dong Chaojun,Huang Wanxia,Ou Kaitong
(Faculty of Intelligent Manufacturing,Wuyi University,Jiangmen 529020,China)
Abstract:Tracking is a very important technology in autonomous driving.In order to solve the problems of object deformation and appearance similarity when tracking moving vehicles in complex scenes,a multi-target tracking algorithm combining attention mechanism and multi-layer feature fusion is proposed.Based on ResNet-34 backbone network,feature pyramid network structure is used to integrate the target features of different network levels.In addition,Coordinate Attention module is added in the backbone network to obtain more accurate position information,and deformable convolution is used in the feature pyramid layer to adapt to the feature extraction of target deformation.Results from experiments conducted on UA-DETRAC vehicle pubilc data set show that the improved algorithm has a multi-target tracking accuracy of 67.03%,which is 4.91%higher than the original ResFPN backbone,and the tracking speed is 35.87 f/s.It can meet the requirement of real-time video frame processing speed.Therefore,the algorithm proposed in this paper has good tracking and real-time performance.
Key words:multi-object tracking;coordinate attention mechanism;feature pycamid network;deformable convolution network;residual network
0引言
目标跟踪作为机器视觉领域的重要研究课题,在无人驾驶、智能交通系统中得到广泛应用。多目标跟踪是一项关键的视觉任务,可以解决诸如拥挤场景中的遮挡、相似外观、身份切换等问题[1]。目标跟踪技术通常与目标检测技术联合使用,为了完成目标跟踪任务,首先需要在视频帧图像中定位目标,然后给每个目标分配一个单独的唯一的身份ID,最后连续帧中相同身份ID的目标将生成一条轨迹。
目前基于深度学习的多目标跟踪框架可大致分为基于检测的跟踪[2-3](Detection Based Tracking,DBT)和联合检测的跟踪(Joint Detection Tracking,JDT)。基于检测的跟踪算法仍然是主流,但随着人们对实时性的要求越来越高,联合检测的算法也逐渐兴起。DBT类算法分为检测与跟踪两个模块,其性能取决于检测器的性能。而JDT类算法是对部分模块进行融合,增强模块间的联系。主流的JDT算法有JDE、CenterTrack、FairMOT。Wang等[4]基于YOLOv3[5]检测网络引入目标重识别任务[6],实现多任务学习,将目标的检测和目标重识别两个步骤合并为一个步骤,有效地提升了跟踪器的速度。Zhou等[7]基于CenterNet进行改进,提出将检测和跟踪两个模块合并成一个网络构建CenterTrack,实现了多模块联合学习,在提升系统跟踪速度的同时能达到较高的跟踪准确度。Zhang等[8]基于JDE的多任务学习和CenterTrack的多模块学习方式,通过提取高分辨率特征来定位目标中心,提出了FairMOT。FairMOT是一种能够让两个任务充分学习的方法,有效解决了身份嵌入特征与对象中心的对齐问题。但由于FairMOT是以目标中心点作为采样区域提取特征,当目标中心点定位不准确,特别是两个实例的中心点重叠时,目标重识别分支可能无法提取到能区分不同实例的特征,从而导致在密集区域的身份切换问题。
基于以上讨论,本文以FairMOT为基础提出了一种空间特征融合的多目标跟踪算法,通过将主干网络替换成更轻量的ResNet和特征金字塔网络来进一步提升整体跟踪速度,同时在主干网络中引入注意力机制,提高网络对目标位置特征的捕捉能力;在特征金字塔层应用可变形卷积(Deformable Convolution)[9]来增大网络感受野。最后在UA-DETRAC公开数据集上对本算法进行实验,以验证本文改进算法的有效性。
1相关工作概述
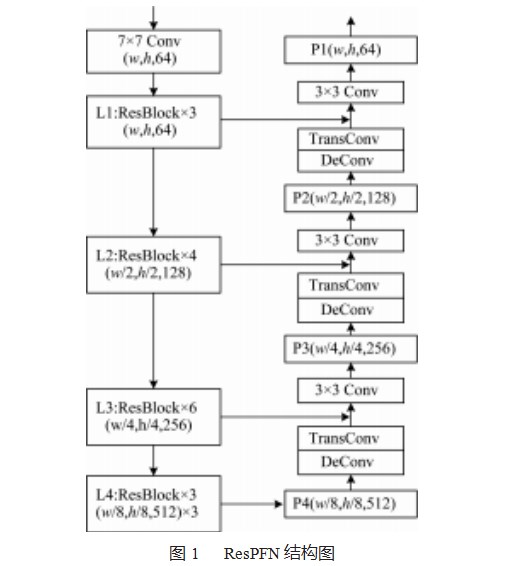
1.1 ResFPN-34主干网络结构
在FairMOT中,采用Anchor-Free方法的CenterNet[10]作为检测网络,主要采用DLA-34、ResNet-34[11]作为主干网络。DLA-34结合DenseNet[12]的密集连接和特征金字塔网络[13](Feature Pyramid Network,FPN)的多层特征融合结构,聚合了语义信息和空间信息。而ResNet-34则能很好地平衡整体的跟踪精度和跟踪速度。本文将采用ResNet-34和FPN相结合的网络来作为骨干网络,称作ResFPN-34,其结构图如图1所示。
在ResFPN-34中,ResNet-34共有4个网络层,其中L1-L4中各有3、4、6、3组残差块。图像经过L2、L3、L4时分别进行2倍、4倍、8倍下采样,将下采样得到的特征图分别输入到对应的特征金字塔层级中。随后采用卷积核大小为4、步长为2的反卷积(Transpose Convolu⁃tion)操作进行上采样,再由侧向连接将ResNet网络层中相同分辨率的特征与通过相加的方法进行融合,从而实现深层语义特征与浅层位置特征的融合。在FairMOT的设置中,ResFPN-34主干网络将金字塔层上采样操作中的3×3卷积替换为可变形卷积来增加卷积的感受野。
1.2注意力机制概述
注意力机制通常作用于卷积神经网络中,可在众多输入信息中聚焦对于当前任务更为关键点的信息,降低对其他信息的关注度,提高任务处理的效率和准确性。这种方法已经被广泛应用于提高深度神经网络的性能。孙孚斌等[14]采用注意力机制来改进基于YOLOv5的人脸检测算法,加速了模型的收敛速度;李青[15]等人通过引入注意力机制来捕获重要特征,并将优化后的算法应用到光伏板分割中。
常用的注意力机制有通道注意力机制[16](Squeeze-and-Excitation Networks,SE),SENet通过全局池化和全连接层来建模特征图通道间的相互依赖关系,然而SENet只关注通道信息而忽略了位置信息。另一个注意力机制CBAM[17](Convolution Block Attention Module)弥补了SENet的不足,在通道注意力后添加了一个空间注意力模块,输入的特征图依次通过通道注意力模块和空间注意力模块,既关注了通道信息也关注了位置信息。随后,协调注意力[18](Coordinate Attention,CA)机制被提出,发现CBAM即使使用了卷积也只能获取局部信息,并不能建模长距离依赖。因此提出的CA注意力通过在通道注意力中嵌入空间注意力,在水平、垂直两个空间方向上捕获长距离依赖的同时能够更准确地定位目标位置。本文将采用CA注意力模块引入主干网络中,提升网络的定位能力。
2空间特征融合的检测网络
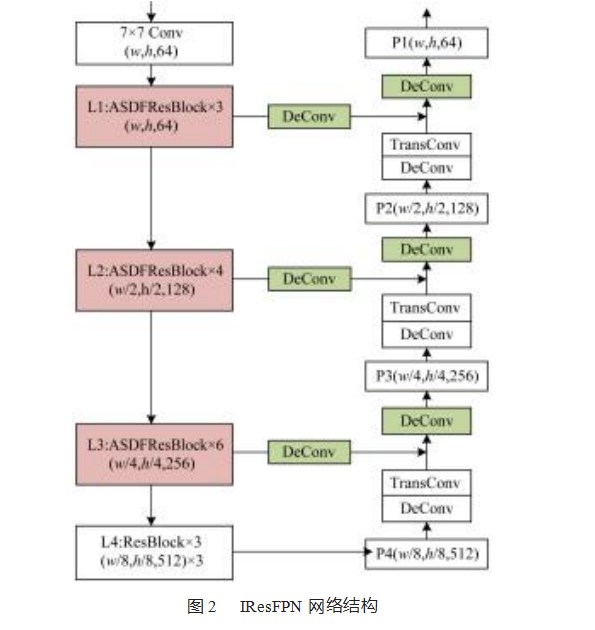
本文提出的网络结构IResFPN(Improved ResFPN network)图2所示。
2.1 ResNet改进
为了让网络在提取目标特征时可以聚焦目标车辆的特征而不受背景、其他目标等因素的干扰,通过在残差块中引入协调注意力机制来增强目标区域特征,抑制其他不必要的特征。本文将CA注意力机制引入构成主干网络的残差结构中,构建聚合空间方向特征的残差块(Aggregate Spatial Direction Feature for Residual Block,ASDFResBlock)。ASDFResBlock结构图如图3所示。在神经网络中,由于浅层网络包含较多的几何信息,因此将ResNet的L1、L2、L3前3层的残差块替换成ASD⁃FResBlock,让协调注意力利用浅层网络的高分辨率信息来帮助网络进行准确的目标定位。
对于输入ASDFResBlock的特征图,首先经过一个3×3卷积得到特征Xt,然后将特征Xt输入CA注意力模块中对Xt特征进行增强。CA注意力把全局池化操作分解成一对自适应平均池化操作,使用一对大小为(H,1)、(1,W)的池化核分别编码每个空间通道的水平区域和垂直区域,这两个编码操作分别沿两个空间方向提取特征,生成一对具有方向感知能力的特征图yh、yw。然后再将两个空间方向的特征进行融合,融合后的特征图可以在水平方向和空间方向中编码位置信息。
随后融合特征f沿空间维度再次被分解成水平和垂直方向上两个独立的张量fh、fw,分别用两个1×1卷积修正fh、fw两个张量的通道数,使其与输入通道数相同。最后经过sigmoid函数输出分别作用于水平和垂直方向的注意力权重。最后模块的输出由水平方向的特征权重wh、垂直方向的特征权重ww以及初始输入Xk三者融合得到,生成具有融合空间方向的特征。最后CA注意力输出的特征再次经过一个3×3的卷积,进行批量归一化和非线性函数激活,完成特征图内目标位置特征的增强。
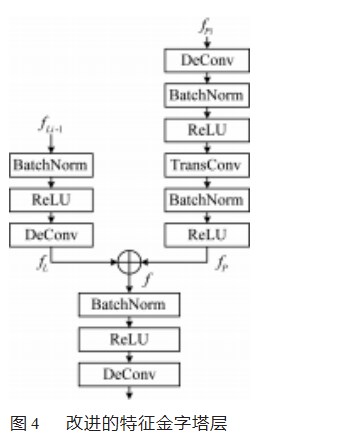
2.2特征金字塔层改进
为了融合深层网络的语义特征和浅层网络的图像特征,本文采用特征金字塔网络对深层特征和浅层特征进行融合。本文改进的特征金字塔层结构如图4所示。该结构有两个输入,输入pi是上一个金字塔层输出的特征图,首先经过一个3×3的可变形卷积,通过对采样点的位置增加偏移量来自适应调整目标区域,扩大卷积的感受野。然后再经过一个卷积核大小为4、步长为2的转置卷积操作进行上采样来实现从小分辨率特征图到大分辨率特征图的映射得到特征fp。
另一个输入Li-1来自主干网络,通过侧向连接与特征金字塔结构相连。在侧向连接中,依然使用了一个可变形卷积扩大卷积的感受野。在经过可变形卷积之前,首先经过BatchNorm对输入数据进行归一化,再经过ReLU[19]函数为结构增加非线性[16]。最后将fp和fl两个特征进行拼接,拼接后的特征f再次经过一组可变形卷积来生成最后的特征图,以此上采样操作产生的混叠效应[16]。经过3次上采样操作,最终输出的特征图大小为64×152×272。
3实验结果与分析
3.1数据集与评价指标
本文采用UA-DETRAC[20]公开数据集对模型进行验证。UA-DETRAC采用交通监控视频视角,数据集从多个场景中采集的视频分成100个视频序列,其中包含超14万个视频帧,涵盖了晴天、多云、雨天以及黑夜4种常规情况。本文从UA-DETRAC中选取60个视频序列作为训练数据,10个视频序列作为测试数据。
本文采用MOT任务主流的MOT Challenge[21]评价指标对模型的多目标跟踪精度(MOTA)、正确识别的检测与平均真实数和计算检测数之比(IDF1)和每秒传输帧数(FPS)等多个方面进行评估,如式(1)~(2)所示。此外,还采用目标检测评价指标中的精确率Prcn(preci⁃sion)对改进网络的检测效果进行评估。
3.2实验环境与训练设置
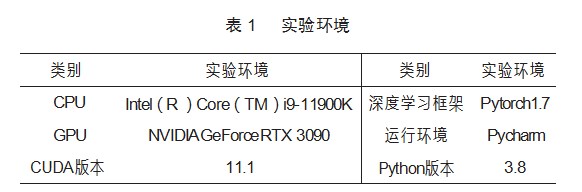
以下所有实验均在同一实验环境下进行,实验环境见表1。本文实验均采用Adam作为优化算法,批量大小(Batch Size)为16,总训练轮数30轮,默认初始学习率为1×10-4。在训练后期模型收敛缓慢,因此在第20轮时将学习率衰减为1×10-5以加速模型收敛。
3.3消融实验
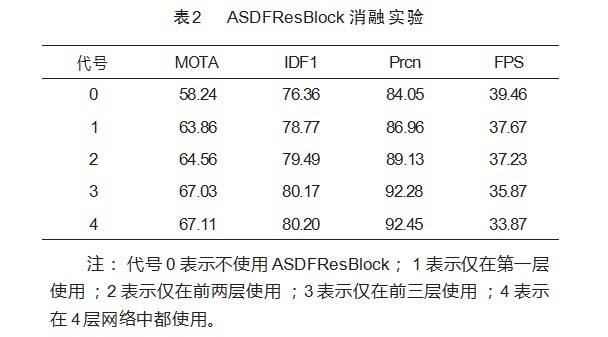
本文设置消融实验对模型改进的有效性进行验证。针对协调注意力模块的引入,ASDFResBlock在不同网络层的替换对网络性能的影响。实验结果如表2所示。在表中,对比第一行的基准网络,当在网络层中使用ASDFResBlock时,检测指标和跟踪指标均有不同程度的提升。当在第一层网络中使用ASDFResBlock时,Prcn有明显的提升。当同时在第一层和第二层中使用ASDFResBlock时,Prcn相较于仅在第一层网络中使用提升了2.17%。当同时在前三层中使用ASDFResBlock时,Prcn相较于同时在前两层网络中使用提升了3.23%。由表2可见,当Prcn上升时,对应前面两个实验,MOTA(+0.7%,+2.47%)和IDF1(+0.72%,+0.68%)也随之上升。由此可见检测器的性能对跟踪结果的影响是不可忽视的。
当在4层网络中都使用ASDFResBlock时,对网络性能(+0.08%MOTA,+0.3%IDF1,+0.17%Prcn)的提升没有明显效果,且跟踪速度每秒下降了两帧。由于第四层网络输出的是深层特征,深层特征中包含较少的位置信息,因此在不能提供更多位置信息的情况下,无法对网络的定位能力起到提升作用,进而影响了整体的检测效果。因此当ASDFResBlock同时在前3层网络中使用时,获得的空间融合特征是具有鲁棒性的。
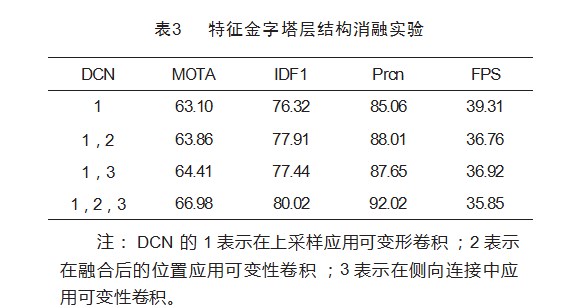
以下是特征金字塔层中对可变形卷积的应用进行实验。实验结果如表3所示。
在许多工作中已经证实将可变形卷积应用在特征金字塔层中的上采样可以提升模型的拟合能力。因此本次实验仅对其他两个位置的应用情况进行探讨。对比基准实验DCN1,实验DCN1,2(+0.76%MOTA、+1.61%IDF1、+2.95%Prcn)和实验DCN1,3(+1.31%MOTA、+1.12%IDF1、+2.59%Prcn)在各项指标上均有提升。当在3个位置同时应用可变形卷积时,可以看到各项性能有明显提升(+3.88%MOTA、+2.7%IDF1、+6.94%Prcn),虽然可变形卷积的应用损失了一些跟踪速度,但依然能够达到实时性。当整个结构中部分卷积为标准卷积时,标准卷积不能自适应调整卷积核,无法应对上层可变形卷积输出的特征。因此当在3个位置中同时使用可变形卷积,能得到更鲁棒的特征。
3.4实验结果
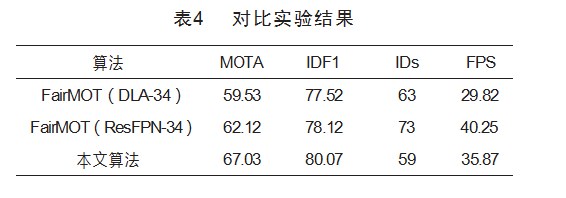
本文将改进的算法与FairMOT(DLA-34/ResFPN-34)在UA-DETRAC上进行比较,实验结果见表4。
对比FairMOT(ResFPN-34),本文的改进算法在MOTA、IDF1上分别提升了4.91%、1.95%和;对比FairMOT(DLA-34),本文的改进算法在MOTA、IDF1上分别提升了7.5%和2.55%。对比本文替换的ResFPN和DLA-34,在MOTA提升(+2.59%)的同时跟踪速度(+10.34 f/s)也得到了提升,说明ResFPN的有效性。在FairMOT中是以检测行人为主,而车辆由于其批量生产的原因,对于行人来说没有太多的个性特征,因此本文算法所采用的ResPFN提取网络已经能够很好地提取车辆的特征,而DLA-34过于复杂的结构可能会使整个网络过于冗余,导致跟踪效果不如ResFPN。在身份切换(Identity Switch,IDs)问题上,本文提出的算法因为增强了目标的定位能力,有效地提取了目标特征,因此也有效地缓解了该问题。本文算法在跟踪速度上达到35.87 f/s,达到实时要求。
4结束语
针对复杂场景下对行驶车辆进行跟踪时出现的目标形变、外观相似等问题,提出了改进的ResNet-34主干网络和改进的特征金字塔网络结构相结合的特征提取网络。该网络在兼顾多层特征融合结构的基础上让整个结构更轻量化,且通过在ResNet网络层中添加注意力模块来增强卷积特征,让网络能够捕获更精确的目标位置信息,使不同目标车辆间有更好的辨识度。同时在特征金字塔层中使用可变形卷积,能够很好地解决因标准卷积不能自适应调整卷积核形状而不能适应形变目标的特征提取问题。实验结果表明,所提出的算法的整体跟踪精度为67.03%,跟踪速度达到35.87 f/s,检测精度总体维持在90%以上。目前主要对检测器进行改进,接下来的工作可以尝试改进目标间的关联匹配策略来提高跟踪成功率。
参考文献:
[1]LUO W,XING J,MILAN A,et al.Multiple object tracking:A liter⁃ature review[J].Artificial Intelligence,2021,293:103448.
[2]CAO J,WENG X,KHIRODKAR R,et al.Observation-centric sort:Rethinking sort for robust multi-object tracking[J].arXiv preprint arXiv:2203.14360,2022.
[3]WOJKE N,BEWLEY A,PAULUS D.Simple online and realtime tracking with a deep association metric[C]//2017 IEEE Interna⁃tional Conference on Image Processing(ICIP).IEEE,2017:3645-3649.
[4]WANG Z,ZHENG L,LIU Y,et al.Towards real-time multi-object tracking[C]//Computer Vision–ECCV 2020:16th European Con⁃ference,August 23-28,2020,Glasgow,UK.Chambridge:Springer International Publishing,2020,Ⅺ(16):107-122.
[5]REDMON J,FARHADI A.Yolov3:an incremental improvement[J].arXiv preprint arXiv:1804.02767,2018.
[6]TAUFIQUE A M N,SAVAKIS A.LABNet:local graph aggrega⁃tion network with class balanced loss for vehicle re-identification[J].Neurocomputing,2021,463:122-132.
[7]ZHOU X,KOLTUN V,KRÄHENBÜHL P.Tracking objects as points[C]//Computer Vision–ECCV 2020:16th European Con⁃ference,August 23-28,2020,Glasgow,UK.Chambridge:Springer International Publishing,2020,Ⅳ:474-490.
[8]ZHANG Y,WANG C,WANG X,et al.Fairmot:on the fairness of detection and re-identification in multiple object tracking[J].In⁃ternational Journal of Computer Vision,2021,129:3069-3087.
[9]ZHU X,HU H,LIN S,et al.Deformable convnets v2:more deform⁃able,better results[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,New York:IEEE,2019:9308-9316.
[10]ZHOU X,WANG D,KRÄHENBÜHL P.Objects as points[J].arXiv preprint arXiv:1904.07850,2019.
[11]HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Comput⁃er Vision and Pattern Recognition,New York:IEEE,2016:770-778.
[12]HUANG G,LIU Z,VAN DER MAATEN L,et al.Densely con⁃nected convolutional networks[C]//Proceedings of the IEEE Con⁃ference on Computer Vision and Pattern Recognition,New York:IEEE,2017:4700-4708.
[13]LIN T Y,DOLLÁR P,GIRSHICK R,et al.Feature pyramid net⁃works for object detection[C]//Proceedings of the IEEE Confer⁃ence on Computer Vision and Pattern Recognition,New York:IEEE,2017:2117-2125.
[14]孙孚斌,朱兆优,陈思超,等.基于改进YOLOv5的人脸检测算法[J].机电工程技术,2023,52(2):172-176.
[15]李青,李海涛,李辉,等.注意力机制和全局卷积在光伏板分割的应用[J/OL].计算机工程与应用:1-11[2023-03-17].http://kns.cnki.net/kcms/detail/11.2127.TP.20230214.1537.062.html.
[16]HU J,SHEN L,SUN G.Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,New York:IEEE,2018:7132-7141.
[17]WOO S,PARK J,LEE J Y,et al.CBAM:Convolutional block at⁃tention module[C]//Proceedings of the European Conference on Computer Vision(ECCV),September 8-14,2018,Munich,Ger⁃man.Chambridge:Springer Science,2018:3-19.
[18]HOU Q,ZHOU D,FENG J.Coordinate attention for efficient mo⁃bile network design[C]//Proceedings of the IEEE/CVF Confer⁃ence on Computer Vision and Pattern Recognition,New York:IEEE,2021:13713-13722.
[19]GLOROT X,BORDES A,BENGIO Y.Deep sparse rectifier neu⁃ral networks[C]//Proceedings of the fourteenth international con⁃ference on artificial intelligence and statistics[J].JMLR Work⁃shop and Conference Proceedings,2011:315-323.
[20]WEN L,DU D,CAI Z,et al.UA-DETRAC:a new benchmark and protocol for multi-object detection and tracking[J].Comput⁃er Vision and Image Understanding,2020,193:102907
[21]DENDORFER P,REZATOFIGHI H,MILAN A,et al.Mot20:A benchmark for multi object tracking in crowded scenes[J].arXiv preprint arXiv:2003.09003,2020.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/77281.html