SCI论文(www.lunwensci.com)
摘要:手写数字识别属于图像分类问题。因个体手写数字的差异,传统的图像分类方法实现快速有效识别的难度相对较大。随着人工智能和计算机硬件技术的快速发展,基于深度学习卷积网络的手写数字识别逐渐成为研究热点。使用PyTorch搭建了经典的网络模型LeNet-5和改进的ResNet18模型进行手写数字识别。采用交叉熵损失函数和Adam优化算法,并设置学习率为0.001,在MNIST数据集上进行了训练和测试,鉴于ResNet18比LeNet-5网络结构深,在训练时花费的时间比LeNet-5多。经过100个Epoch后,使用LeNet-5模型在测试集上准确率达到99.18%,使用ResNet18卷积模型的准确率高达99.55%,可以识别自制的手写数字,为人工智能识别系统的发展提供了一定的参考价值。
关键词:手写数字识别;LeNet-5;ResNet残差网络
Research on Method of Handwritten Digit Recognition Based on Artificial Intelligence
Huang Mingchun,Tian Xiuyun※,Xie Yuping,Wang Wenhua,Xie Qin,Shi Wenqing(Faculty of Electronics and Information Engineering,Guangdong Ocean University,Zhanjiang,Guangdong 524088,China)
Abstract:Handwritten digit recognition is an image classification problem.Due to the differences of individual handwritten digits,it is relatively difficult for traditional image classification methods to achieve fast and effective recognition.With the rapid development of artificial intelligence and computer hardware technology,handwritten digit recognition based on deep learning convolutional networks gradually becomes a research hotspot.The classical network model LeNet-5 and the improved ResNet18 model were built using PyTorch for handwritten digit recognition.The cross-entropy loss function,Adam optimization algorithm,and learning rate of 0.001 were used to train and test on the MNIST dataset.Given that ResNet18 had a deeper network structure than LeNet-5,it took more time to train than LeNet-5.After 100 epochs,the accuracy reached 99.18%on the test set using the LeNet-5 model and 99.55%using the ResNet18 convolutional model.It can recognize homemade handwritten digits,providing some reference value for the development of artificial intelligence recognition systems.
Key words:handwritten digital recognition;LeNet-5;ResNet residual network
0引言
手写数字识别是利用计算机对手写数字的一种自动识别技术,这一识别技术在现实中有很大的应用需求,比如快递的自动分拣,智能终端的手写数字输入[1-2],银行的票据核对,资料表、试卷分数的自动录入等,这些领域的手写数据庞大[3],需要耗费大量的人力,利用人工智能自动识别的方法可以减少人力的消耗,且在一定程度上减少人为因素导致的错误,使得该工作更自动化和高效化。国内手写数字识别方法大致可分为以下两大类[4]。
(1)基于手写体数字集的字符结构特征的识别方法,此种方法注重于数字的本身结构特征,通过模板匹配的方式直观地描述数字图像的特征来实现识别,但是遇到书写潦草,字符出现严重变形时识别效果不好,且提取特征的过程非常繁杂。
(2)基于统计数字集模型特征的识别方法,其识别过程理论上分为3个阶段:预处理[5-6],特征提取阶段,分类阶段。通过大量的学习数据样本的特征表现,来学习获得近似样本数据集的特征,利用学习到的特征训练分类器,最后对未知的数据集进行预测识别,基于深度学习卷积网络的手写数字识别属于此类,但文献中手写数字识别研究很多采用的tensorflow框架,随着PyTorch框架的广泛应用,使用PyTorch框架训练成为一种趋势。
本文结合人工智能深度学习的理论知识和卷积神经网络模型,基于PyTorch框架搭建网络模型,在单GPU电脑上进行模型训练,使训练好的模型能识别自制的手写数字,为人工智能识别系统的发展提供一定的参考价值。
1相关理论
1.1卷积神经网络基本结构
卷积层[7](Convolutional Layer):卷积神经网络中的每个卷积层都是由数个卷积单元组成,每个卷积单元里的权值参数是通过反向传播(BP)算法不断最佳优化得到的,目的是提取输入图像的特征,根据调节卷积核的大小,移动的步长以及对输入图像是否填充,来自动获取图像的局部特征,往往前面层次的卷积层只能提取比较低级的特征,更多层的网路能从低级特征中继续迭代提取,从而获得更复杂的特征。
池化层[8](Pooling Layer):池化是卷积神经网络中的一个重要概念,是一种对数据的下采样,通常有两种方式,一种是最大池化(Max Pooling),另一种是平均值池化(average Pooling),具体形式是对输入图像按照一定大小进行划分,最大值池化输出每个区域的内的最大值,平均值池化是输出每个区域的平均值,这一过程可以使得参数的数量和计算量下降,同时舍去了部分数据,也在一定程度上减轻了过拟合现象。
全连接层(Fully Connected Layer):全连接层的作用主要就是实现分类,一般在池化层到输出层之间,作用是将前面的数据打平,按照一定的权值进行计算,最后通过激活函数等处理,得出分类结果。
1.2损失函数
损失函数(Loss Function)是用来估计模型预测值和真实值之间的差距程度的函数,损失函数越小说明预测值越接近真实值,一般可以分为两类损失函数:回归损失函数和分类损失函数。手写数字识别属于分类问题,常见的分类损失函数有两种。
(1)Logistic损失函数,其定义式为:
Logistic损失函数只能用于处理二分类问题,对于多分类问题一般使用交叉熵损失函数,常常与Softmax一起使用,手写数字识别属于多分类问题。
1.3 Dropout方法
深度神经网络中拥有很多的非线性隐藏层,通过学习可以拥有很强的表达能力,但其强大的学习能力在较小的训练数据集下会出现严重过拟合的现象,以往为了减小这个现象,需要花费很多的时间来训练多个模型,效果也不是很好。
在2012年,Hinton[9]提出了Dropout这个方法,这个术语可以理解为丢弃,在前向传播时,通过在每个神经元上加入一定的概率来丢弃部分神经元,并不是真正意义的丢弃,而是暂时的隐藏,在下一批次训练中可能会出现,以至于每批次训练的时候,都可以近似看作在训练不同的模型,泛化性更强,通过此方法可以大大节省训练多个模型的时间,减轻过拟合现象。
1.4批量归一化
批量归一化[10](Batch Normalization,BN),通过对输入和中间网络层的输出进行标准化处理后,减少了内部层间输入分布的改变,具有以下特点:
(1)使得大部分的数据都处在非饱和区域,从而保证了梯度能够很好地反向传播,避免了梯度消失和梯度爆炸;
(2)减少梯度对参数或其初始值尺度的依赖性,使得可以使用较大的学习速率对网络进行训练,从而加速网络的收敛,让模型变得更加健壮,稳定性更强;
(3)增加了网络的独立性,使后面的神经元单元不过分依赖前面的神经元单元。所以,它也可以看作是一种归一化手段,提高了网络的泛化能力,使得可以减少或者取消Dropout,优化网络结构。
2网络模型
随着硬件计算能力的提升,卷积神经网络的研究在近几年得到很快的发展,网络的层数变的越来越深,本文主要介绍LeNet-5和ResNet经典网络结构。
2.1 LeNet-5
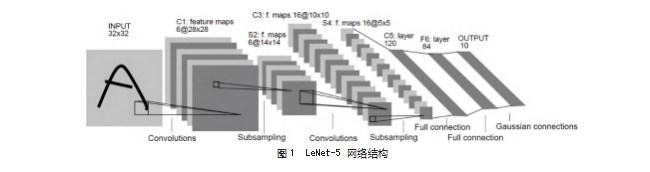
LeNet-5[11-13]是非常经典的一个神经网络模型,可以说是CNN的开山之作,由CNN之父Yann LeCun在1998年提出,起初的目的是用于做数字识别,网络结构图1所示。从输入到输出一共有8层结构,其中包括两层卷积层,两层池化层,两层全连接层,卷积核都是5×5,步长为1,池化层使用最大池化层。
2.2 ResNet
网络深度的提升一定程度上可以提高模型的表达能力,但是后来人们发现如果一味的提升网络,并不能一直提升网络的性能,网络的层数过深时,会导致梯度弥撒或梯度爆炸等问题,而且还降低了收敛的速度,在排除了数据集过小导致的过拟合等问题后,发现网络过深确实会减低分类的准确度,减低了性能,针对这个问题,何凯明和他的同事在2015年提出了深度残差网络,利用残差学习尽可能的提高了网络的层数,并在2015年的ImageNet图像识别挑战赛获得冠军,并深刻影响了后来的深度神经网络的设计。
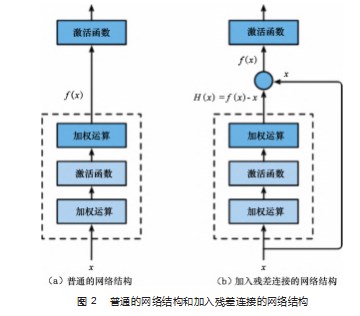
如图2(a)所示,在普通的网络结构中,设输入是x,期望的输出是f(x),学习的目标就是使输入x进过训练得到的输出近似等于f(x),训练时如果x本身就比较大,x与f(x)微小的差距并不会显著改变权值,训练速度很慢,难度也高。如图2(b)所示,在加入残差连接的网络结构中,将输入直接短接到输出层,既令f(x)=H(x)+x,其中H(x)就是残差,这时需要学习的目标就转变为使H(x)很小的差距也能出现显著的变化。
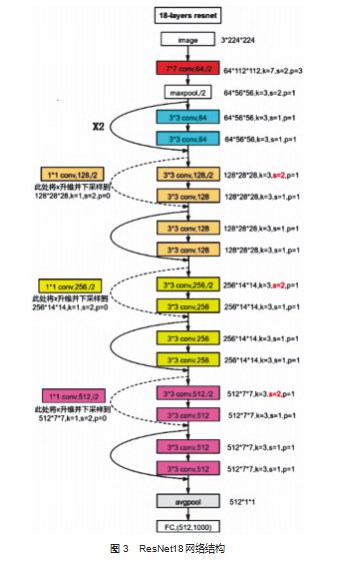
图3所示为ResNet18的残差网络结构。残差网络的优势不是在于模型的表征方面,残差网络并不能更好地表征模型的某一特征,但是允许一层一层深入地表征更多的模型,残差网络的加入使得反向传播算法进行更加顺利,缓轻了梯度消失问题,残差网络使得优化较深层模型变得更为简单。
3手写数字识别系统设计
3.1开发环境
网络模型均使用PyTorch进行搭建,PyTorch是由Facebook推出的一个开源的Python机器学习库,能够实现强大的GPU加速,同时还支持动态神经网络,模型的训练和测试是在一块英伟达的GPU(型号GTX-1050)上完成。
3.2数据集
MNIST数据集[14]是机器学习领域里非常经典的一个手写数字集,一共由4个部分组成。包括训练图片集、训练标签集、测试图片集、测试标签集,分为6万张训练图和1万张测试图[15],每张图片以28×28的像素大小保存,图片在数据集内被展开成一个长度为784的向量,因此在训练数据集文件中是一个形状为[60 000,784]的矩阵,第一个维度是图片的索引,第二个维度是具体的图片数据,标签集使用的是one-hot编码,用0和1在一个长度为10的向量上表示10个数字,比如6的编码为[0,0,0,0,0,0,1,0,0,0,0]所以训练标签集是一个[60 000,10]的矩阵,均以二进制码保存。
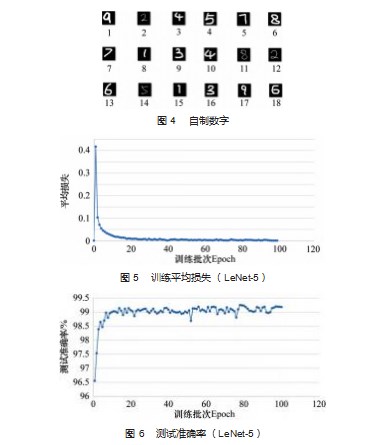
自制18张手写数字图片,大小为28×28像素,与MNIST的图片一样,白底黑字,如图4所示。
3.3基于LeNet-5的手写数字识别
超参数设置:BATCH_SIZE=256,EPOCH=100,训练结果如图5~6所示。
可以看出随着训练批次的增加,平均损失在逐渐减小,准确率也从96.55%提升到了99.18%,得知此网络在MNIST数据集上有不错的训练效果,下面导入自制的18张手写数字图片来测试网络,识别步骤:(1)打开训练好的模型;(2)使用PIL工具包打开并处理需要测试的图片,并用Numpy将图片转为数据格式;(3)放入网络模型,进行预测。效果如图7所示。从结果来看,网络可以识别部分的自制数字,在预测的18个数字里有2个数字是预测错误,正确率为89%效果比较好。
3.4基于ResNet的手写数字识别
因为MNIST数据集的图片像素比较小,而残差网络ResNet18原输入是像素大小为224×224的图片,所以这里是对ResNet18进行了改变,具体分析如下。
第一部分为卷积层,使用64个大小为3×3,步长为2的卷积核对输入为1×28×28图像进行特征提取,图像需要宽为1的填补,输出为64个14×14的特征图,再对输出进行批量归一化,并使用ReLu函数进行激活。
第二部分为残差块,对64×14×14的输入进行两次卷积处理,两次都使用3×3,步长为一的卷积核来提取特征,均对输入进行宽度为1的填补,输出仍为64×14×14,每次卷积之后都使用批量归一化对数据进行优化,避免过拟合问题,最后进行将最初的输入与卷积输出进行短接。
第三部分为相同的结构的残差块,第一次卷积使用大小为3×3,步长为的2的卷积核来提取,第二次卷积使用大小为3×3,步长为1的卷积核,不同之处在于输入和输出的大小不同,因为输入和输出的通道数大小不同,无法直接短接,需要先处理。
最后一个部分是全连接层,先把最后一个残差块的512×2×2输出,采用适应平均池转化为512×1×1的张量,再将张量打平并进行全连接。
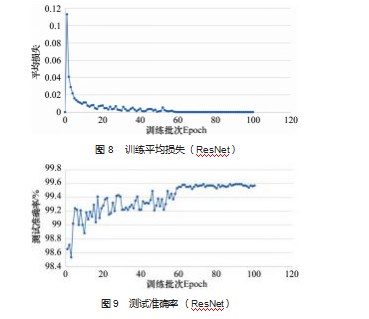
超参数设置:BATCH_SIZE=256,EPOCH=100,训练结果如图8~9所示。
可以看出使用随着训练批次的增加,准确率可高达99.55%以上,在MNIST数据集上有不错的拟合效果,下面使用自制数字测试,结果如图10所示。网络可以识别自制的数字,并且在18个数字中只出现了一个错误,正确率为94%,效果比较不错。
4结束语
本文基于Pytorch深度学习框架,分别采用LeNet-5和ResNet18对MNIST数据集进行训练和测试,绘制训练集上的loss曲线,直观地观察模型收敛情况,同时给出测试集上的准确率曲线。结果表明,LeNet-5在测试集上准确率为99.19%,自制数据集的准确率为89%;ResNet18在测试集上准确率为99.55%,自制数据集的准确率为94%,相比LeNet-5识别结果要好一些。但因为ResNet18的网络比LeNet-5要深,在训练时花费的时间比LeNet5多,ResNet18训练1个Epoch约70 s,LeNet-5需要30 s左右。
参考文献:
[1]何帅.卷积神经网络在手写数字识别中的应用[J].电脑知识与技术,2020,16(21):13-15.
[2]方定邦.基于卷积神经网络的手写数学公式字符识别的算法研究[D].福建:华侨大学,2020.
[3]黄志超,乔振华.基于机器学习模型的手写数字识别[J].电脑知识与技术,2019,15(33)215-217.
[4]覃帅.基于深度残差网络的手写体数字识别研究[D].西安:西安电子科技大学,2019.
[5]胡玲琳,张若男,李培年,等.手写数字体自动识别技术的研究现状[J].浙江万里学院学报,2015,28(2):72-78.
[6]田一然.手写体数字识别技术的研究与实现[D].长春:吉林大学,2015.
[7]郑继燕.基于CNN的手写数字识别与试卷管理系统设计[D].北京:北京邮电大学,2020.
[8]陈庭轩.基于集成卷积神经网络的手写体数字识别研究[D].武汉:华中师范大学,2020.
[9]Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:A simple way to prevent neural networks from overfitting[J].The Journal of Machine
LearningResearch,2014,15(1):1929-1958.
[10]时梨,蔡林.基于Python语言构建神经网络识别手写数字的研究[J].电脑编程技巧与维护,2021(2):117-118.
[11]吴翔宇.基于残差网络的快速手写体数字识别算法[D].西安:西安电子科技大学,2019.
[12]王风盼.基于深度学习的手写数字识别方法研究[D].重庆:重庆大学,2018.
[13]李斯凡,高法钦.基于卷积神经网络的手写数字识别[J].浙江理工大学学报(自然科学版),2017,37(3):438-443.
[14]Pooja Lakhane,Milind Rane.Handwritten Digital Recognition[J].Journal of Research in Science and Engineering,2021,2(12):89-98.
[15]宗春梅,张月琴,石丁.PyTorch下基于CNN的手写数字识别及其应用研究[J].计算机与数字工程,2021(6):1107-1112.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/61240.html