SCI论文(www.lunwensci.com)
摘要:在中国社会老龄化的背景下, 基于深度学习的摔倒检测方法研究日益重要, 而最有前景的当属基于普通 RGB 摄像机提取骨 骼点的摔倒检测方法。目前公开的摔倒数据集大多是视频流数据, 存在骨骼数据提取困难、标注需要耗费大量人力等不足, 而且 以往研究者们在研究基于骨骼点的摔倒检测算法时仅注重于训练出鲁棒的摔倒判别模型, 并没有重视目标检测与目标跟踪算法而 导致的整体系统不稳定、误判率高问题。基于此, 提出了一种骨骼捕捉策略及摔倒检测方法, 骨骼捕捉策略可过滤掉摔倒数据集 的干扰, 提取到更适合训练的骨骼点同时减少大量的人力; 而摔倒检测方法包括训练数据处理以及检测系统逻辑优化, 能实现系 统实时性的同时保证系统的稳定性, 降低摔倒检测系统的误判率。通过实验验证了方法的有效性, 在 Le2i Fall 数据集、 UP Fall 数 据集及 Mutiple Camers Fall 数据集上提取骨骼点来训练 LSTM 模型, 精度达 93%, 并采用自拍摄视频对系统进行了测试, 在 GTX1060 显卡中达到45 fps 同时达到较好的效果。
关键词:摔倒检测,骨骼捕捉策略,摔倒系统框架优化,现实泛化性
A Stable 2D Bone Capture Strategy and Fall Detection Optimization Framework
Chen Wenxuan, Zeng Bi ※, Guo Zhixing
(School of Computers, Guangdong University of Technology, Guangzhou 510006. China)
Abstract: In the context of China′s aging society, the research on fall detection method based on deep learning is becoming more and more important, and the most promising is the fall detection method based on ordinary RGB camera to extract bone points . At present, most of the disclosed fall data sets are video stream data, which is difficult to extract bone data and requires a lot of manpower for labeling . In addition, in the past, researchers only focused on training a robust fall discrimination model when studying the fall detection algorithm based on bone points, and did not pay attention to the target detection and target tracking algorithm, resulting in the instability of the overall system and high misjudgment rate. A bone capture strategy and fall detection method were proposed. The bone capture strategy could filter the interference of fall data set, extracted bone points more suitable for training, and reduced a lot of manpower at the same time. The fall detection method included training data processing and logic optimization of the detection system, which could realize the real-time performance of the system, ensured the stability of the system and reduced the misjudgment rate of the fall detection system . The effectiveness of the method was verified by experiments. Bone points were extracted from Le2i Fall data set, UP Fall data set and Multiple Cameras Fall data set to train LSTM model, the accuracy was 93%. The system was tested by self shooting video. It achieved 45 fps in GTX1060 graphics card and achieved good results at the same time.
Key words: fall detection; bone capture strategy; system framework optimization; reality generalization
0 引言
根据数据显示, 我国老年人口预计到 2025 年将达到 2.8 亿左右, 约占全国总人口的 19.3%。到 21 世纪中叶, 65 周岁以上的老年人口将接近峰值, 老年人口达到 4.83 亿, 占全国总人口比重将达到 34. 1%, 届时我国老年人 口将占到亚洲老年人口的 40%[1]。随着人口老龄化现象 不断加剧, 用于服务老年人的公共设施的数量和规模将 不再能满足社会的需求。老年人身体机能差, 平衡能力 不强, 应变能力弱, 就容易出现摔倒的情况, 而老年人 骨骼就像玻璃般脆弱, 一旦摔碎, 再难粘合恢复, 从而 引起严重后果[2]。
在过去 20 年间, 一直都有学者在研究跌倒检测方 法。国内外摔倒检测方法分 3 类: 基于环境传感器的方 法、基于视频的方法及基于可穿戴传感器的方法。基于 环境的方法[3] 有侵犯性小、算法效率高和实时性好的优 点, 但缺点也相当明显, 它难以判定掉落的是人还是物 体, 导致误判率非常高, 且场地需要有一整套完整的部 署, 造价昂贵, 限制比较大, 难以普及到大多数人的家 庭中。基于穿戴式的摔倒传感器[4-6]容易对使用者造成不 便, 而且传感器的电源供应也有局限, 导致老人并不喜 欢佩戴该类传感器。基于视觉的方法有更好的研究前景, 在于它全自动、普适性强且视频流能提供更多的场景信息。而在基于视觉的方法中, 将 RGB 图像[7]作为输入的 方法需要依靠深度网络学习排除图像中的冗余信息而导 致模型规模较大, 模型算力需求大而在现实中无法达到 实时性; 基于 RGBD 的方法需要特殊的深度传感器设备, 成本较高; 基于光流法需要基于前后两帧图像计算稠密 光流图像, 这个过程就会消耗大量的时间, 在现实中也 并不具有实用性。 Johansson[8] 在生物学观察中表明, 即 使缺乏外观信息, 人类也能够从人体几个关节连续的运 动中识别出不同的动作。这是因为在人的主观视角中, 人体骨骼是一种简洁的数据形式, 且序列化的骨骼数据 也能较好地描述人的动态变化信息。骨骼数据是所有人 体内所有关键关节的三维坐标, 其可以通过不同的姿态 估计方法从多帧图像或直接由 Kinect 等传感器采集得到, 时效性好, 因此基于骨骼点的摔倒检测方法具有良好的 应用前景。
但目前公开的摔倒数据集大多没有骨骼点数据, 而 且视频中存在多人走动、背景复杂等干扰因素, 需要摔 倒领域的研究者付出大量的人力成本才能标注好。再者 目前基于骨骼点的摔倒检测算法并没有较好的逻辑链条, 如 Yin Zheng[9] 和卫少洁[10]都使用目标检测与姿态估计方 法对现实场景中的人物进行骨骼提取, 获取一段骨骼序 列后输入到不同的判别模型进行判别。 Yin Zheng[9]使用 ST-GCN 图卷积模型, 而卫少洁[10]使用的是 LSTM 对摔倒 行为进行判别, 虽说这些方法能在公开数据集上得到很 好的效果, 但都仅针对判别模型进行改进, 都没有考虑 目标检测与目标跟踪对骨骼提取的稳定性问题。上述两 个问题都会导致在摔倒数据集上训练的算法系统难以泛 化到现实世界中。
本文主要研究解决如何将基于摔倒数据集训练出来 的模型, 能确切地应用在现实世界的问题: (1) 为减少 研究者在标注过程中的人力成本, 本文提出了一种骨骼 捕捉策略, 它利用单目标跟踪算法与目标检测相结合, 自动捕捉场景中人物骨骼点, 从而稳定有效地提取出 可用的训练骨骼点, 使得后续的模型训练更加有效; ( 2 ) 针对现有摔倒检测系统存在的缺点, 本文提出一种 优化的摔倒检测方法, 它利用 SORT 多目标跟踪算法跟 踪姿态估计方法生成的 BoundingBox, 并采用阈值法消取 多余的骨骼点, 该方法不仅有较好的时效性, 且能提高 整体的摔倒检测系统的稳定性, 降低系统误判率。
1 相关工作
目前所有针对摔倒行为的公开数据集并无骨骼点数 据。较大规模的摔倒数据集, 如 Le2i Fall Dataset 、UP Fall Dataset 、Multiple Cameras Fall Datasets 等[11- 13], 除了 UP Fall 数据集会有一些加速度传感器或光流图像数据其 他都只是视频流数据。而骨骼点坐标数据有 2D 或 3D。一般来说2D 姿态的质量优于3D 姿态。如图1所示, 图 1 (a) 中是 HRNet[14]估计的 2D 姿势可视化。显然, 它们的质量 比图 1 (b) 所示的 Kinect 传感器收集的 3D 姿态估计要 好得多。因此主要使用与现实任务关键点匹配度较高的 2D 姿态估计算法来将摔倒数据集转换为骨骼点坐标。
姿态估计算法分为两类, 一种是自顶向下, 较好的 算法是 CPN[15] 和 HR_Net, 算法的大概逻辑是先检测画面 中的所有人物, 将每一个 BoundingBox 中的图片输入到 单人姿态估计网络中进行估计。另一种是自下而上, 较 好的代表是 Openpose[16], 算法逻辑是检测画面中所有的 关节点, 再使用匈牙利算法等聚类算法进行最优匹配。
摔倒数据集中的视频流数据会有不同程度的干扰问 题。如 Multiple Cameras Fall 数据集数据集拥有 8 个不同 的视角, 为反映真实的生活状态, 视频中会有背景复 杂、目标遮挡、目标尺度过小等难点。而 Le2i Fall 数据 集和 UP Fall 数据集中有多人走动、背景阴暗、动作执行 者缺失等难点。如图 2 所示。这是从 UP Fall 数据集中截 取正向视角与侧面视角的几帧图像, 展示一个人模拟摔 倒的全过程。正向视角中出现了一个坐着的人, 而侧面 视角的玻璃外面有一个行走的人, 他们的行为都并不符 合当前帧动作执行者的标签。如果仅用姿态估计算法进 行骨骼提取, 会污染训练数据并且难以进行筛选。

摔倒判别系统有基于光流法[17- 18] 或基于深度图像[19] 的方法, 但它们受到环境中的光照或移动的物品影响较 大, 且相对于基于骨骼点的摔倒检测系统不够鲁棒或达 不到时效性。一般基于 2D人体姿态骨骼点的摔倒判别系 统框架主要分成 4 个部分, 分别是检测、跟踪、姿态估 计以及摔倒检测。分类模型可以是传统的 SVM[21] 或者 LSTM。算法逻辑是先用目标检测检测环境中的人物, 再 用单目标或多目标追踪算法累积骨骼序列, 最后进行分 类判断。基于实时性考虑, 目标检测算法会选择单阶段 的 YOLO 系列的算法。出于在实际家庭场景中多于两个 人的情况较多, 即便单目标跟踪能力要好于多目标跟踪 法也并不适用于现实。此时这个摔倒系统在现实应用时 极容易因为目标检测算法的不稳定而丢失跟踪, 导致后 续的判别模型无效。因为如今深度学习的模型在追求速 度的前提下就会损失一定的精度。图 3 所示为 YOLOv5[21]和 MiniYOLOv3[22] 目标检测算法对 UP Fall 数据集的人物 检测结果显示, 可以看到第 26 帧侧视角画面出现了误检 的情况, 对比后两帧正视角的连续画面, 虽然两者都没 有误检或漏检, 但 YOLOv5 对于检测人物边界的精确度 要远高于 MiniYOLOv3 且 MiniYOLOv3 对后两连续帧检测 的 BoundingBox 形变较为严重。这种情况容易导致跟踪 算法丢失追踪目标, 出现频繁切换运动目标 ID 的情况,进一步影响整体系统对摔倒系统的判断。但 YOLOv5 的 高精度源于其大参数模型, 它的速度远不如 MiniYOLOv3 高。因此本文针对上述问题提出了一种骨骼捕捉策略以 及摔倒检测方法。这两个方法都能使摔倒系统能更好地 应用在现实世界中
2 本文算法
2.1 骨骼捕捉策略
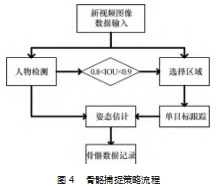
骨骼捕捉策略使用的是自顶向下的 HRNet 方法。基 于以下几点原因, 第一是自下而上的姿态估计算法依靠 聚类算法去划分关节点, 当目标显示不完全或两个多人 目标重叠的时候, 提取到的骨骼数容易缺失或错乱, 无 法转换为有效的训练数据; 第二是目前 SOTA 算法中自 下而上的姿态估计算法并无自顶向下的姿态估计算法精 度高。为了获得置信度更高且精确的骨骼坐标数据, 本 文使用的是自顶向下的姿态估计算法。针对视频中的多 人走动、动作者不在画面中、遮挡或背景阴暗的问题, 本文的骨骼捕捉策略引入了 RiamRPN++[23]单目标追踪算 法。整体算法流程的描述如下: 遍历每一个数据集的动 作视频, 人工框选动作执行者出现的第一帧画面, 利用 单目标跟踪算法对其进行跟踪并输入到姿态估计算法中, 这样就可以过滤掉多余的人, 筛选出主要的动作执行者。 但在 Multiple cameras Fall 数据集中拍摄的场景比较复杂, UP Fall 数据集动作执行者速度较快, 这些情况都容易导 致单目标跟踪算法丢失目标, 难以重捕获跟踪目标导致 转换出错误的骨骼数据污染训练数据。因此本文引入目 标检测算法, 利用目标检测得到的目标预测框不断纠正 单目标算法的跟踪区域。当目标检测框与单目标跟踪框 的 IOU 重合在[0.8.0.9]的区间内时, 对单目标跟踪框进行 修正, 使得跟踪更加稳定。当动作执行者消失在画面中 时, 提取到的骨骼点整体均值会小于 0.3 且无 IOU 重合度高的检测框, 此时应当抛弃当前帧的骨骼数据。整体骨 骼捕捉策略流程如图 4 所示。
2.2 摔倒检测优化方法
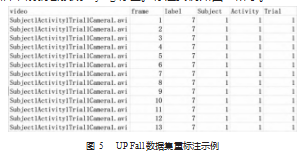
摔倒检测系统优化框架分两部分, 数据预处理优化及系统逻辑优化。在数据预处理部分, 要想在现实世界 中达到更好的泛化性, 就需要引入大量的数据训练。但 不同的摔倒数据集中标签和标注的方式并不统一。这就 需要对标签进行重标注, 而重标注需要选择合适的方式。 Le2i Fall 数据集只对摔倒的开始帧和结束帧作了编号。 Multiple Cameras Fall 数据集用数字 1~9 分别代表了Fall⁃ ing 、 Lying on the ground 、 Crounching 、 Moving down、 Moving up 、Sitting 、Lying on a sofa 以及 Moving horizontaly 这 9 种标签, 数据集对每一帧图像都标上了数字。而 UP Fall 数据集中则将摔倒分成了 5 种类型, 分别用数字 1~ 11 代 表 Falling forward using hands 、Falling forward using knees 、 Falling backwards 、 Falling sideward 、 Falling sit⁃ ting in empty chair 、Walking 、Standing 、Sitting 、Picking up an object 、Jumping 、Laying 共 11 种标签, 但数据集作 者在录制时限制了每个志愿者做的每个动作视频在 10~ 60 s 以内, 并对整个视频标注为当前的动作的数字。图 2UP Fall 数据集中的第 1 帧中志愿者是站立状态, 在第 17 帧开始有向前倾的动作, 在 47 帧时已经完全躺在保护 垫上并维持躺倒姿势直到视频结束的 172 帧。摔倒动作 发生在一瞬间, 仅持续了大概 30 帧的时间。如果标注方 式如 UP Fall 数据集那样将整个 10 s 视频都纳入摔倒标签 中, 容易和躺倒的动作混淆, 因此本文基于现实应用的 考虑采取了 Multiple Cameras Fall 的标注方式, 对每一帧 图像都标上一个动作标签, 人为判断每个动作之间分离 的界限。摔倒检测的任务集中在识别摔倒行为而非区分 众多不同的动作。因此本文结合了三个数据集的动作标 签描述, 在重标注数据集的时候将其简单概括为 7 类 (分别对应数字 1~7), Standing 、Sitting 、 Falling down、 Waliking 、Standing 、Sitting 、Lying down。例如 Le2i Fall 数据集中目标对象展示是一个扫地的动作, 就可以使用 Walking 或者 Standing 替代。 UP Fall 数据集中摔倒视频的 后半段就会换成 Lying 标签。标注实例如图 5 所示。
姿态估计算法会因为画面中遮蔽或光线等因素而对 当前关节点的准确度进行评估, 得到置信度 Ci。现实中 对一个动作是否发生的判断也应当是一个概率值。因此 置信度较差的骨骼点难以作为判断动作的有效依据, 因 此需要减少错误骨骼点对整体算法框架的影响。将标签乘上当前帧所有骨骼点的置信度平均值, 使得标签值成 为会根据姿态估计得到的可信度进行调整的概率值。计 算过程如下式所示:
C ave(t) =C i(t)
Labelt = Labelt × C ave(t)
式中: C ave(t)为 t 时刻下所有骨骼置信度的平均值, 融合到t 时刻下的 Labelt 并使其成为一个概率值。
不同的数据集的视频画面分辨率不同, 如 UP Fall 数 据集是 640×480. 而 Le2i Fall 数据集是 320×240.姿态估 计算法得到的是骨骼点在像素坐标系下的位置。需要将 骨骼点数据除以视频帧的长度和宽度, 缩放到基于数据 集视频帧的相对大小。此时需要进一步消除人物在不同 位置做动作带来的误差。以每帧所有骨骼点为单位作 Max-Min 归一化:
x ′ = 2 × - 1 ( 3 )
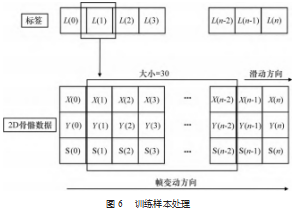
式中: xmax 、xmin 为单帧中最大、最小的关节点数据,一般基于骨骼的动作识别算法, 如文献[24], 使用 的是公开的 NTU120[25]数据集。虽说 NTU120 数据集对于 每一类动作的数据收集并无统一时间序列长度, 但为了 统一输入数据维度, 多数基于骨骼的动作识别文献会以 300 帧 (若不足 300 则填充 0~300) 作为时间维度的长 度, 然后选择其中的关键帧确立为更加短的时间维度长 度。本文主要任务是检测摔倒行为, 它是一种短暂甚至 是瞬时发生的行为。本文使用的数据集是设定摄像机在 18~30 fps, 在标注所有数据集的过程中, 本文总结出了 发生一次摔倒行为的视频中可供标注的画面在 30~75 帧 (取决于摄像机的帧率)。因此可以断定摔倒行为的持续时 长约在 1~2.5 s, 它可以简单概括为向下倾斜、倒下以及 完全躺倒 3 个状态。参考目前家庭监控摄像机多在 25 fps 以及摔倒行为持续的时长。本文选择将一次动作的判断 定义在 30 帧, 并参考文献[10]采取窗口滑动法提取用于 后续训练的骨骼序列样本。窗口滑动法如图 6 所示。其中 size 大小为 30.窗口沿帧顺序方向滑动一个单位即可 获得一个训练样本 Xi 以及对应标签 Li, 其中 Xi 由 30 个连 续帧的 14 个骨骼点的 x 坐标、 y 坐标以及骨骼置信度组 成, Li 则是融入骨骼置信度的标签。
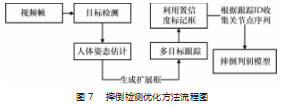
摔倒检测系统优化方法的整体流程如图 7 所示。多 目标跟踪算法为 SORT[26], 它是 2016 年中多目标跟踪领 域的 SOTA 方法。它没有使用深度学习, 但有极为良好 跟踪效果且能达到很高的时效性。针对图 3 中第 26 帧中 误检的问题, 如果只是单帧出现, 则不会被追踪算法分 配 ID, 更不会集满 30帧连续骨骼数据并输入到摔倒检测 网络中, 但如果在家庭中出现连续超过 30 帧误检时, 不 仅占据内存还会提高系统的误判率, 一直触发警报。因 此本文使用了阈值法对提取到的骨骼置信度进行筛选, 计算姿态估计算法提取的骨骼点的置信度均值, 如果骨 骼点的置信度均值连续 20 帧小于 0.35. 则将其 ID 标记 FalseSkeleton, 不输入到最后的判断中。针对图 3 第 27、 28 帧前后形变严重的问题, 因为姿态估计算法得到的骨 骼点形成的外边框比目标检测的 BoundingBox 变化更小更稳定, 因此本文利用多目标跟踪算法跟踪人体姿态估 计生成的人体框。
3 实验
3.1 实验设置
本文的实验环境是将 GTX2080Ti 11G 独立显卡作为 训练设备和骨骼提取设备, 而摔倒检测算法的测试设备 为 Intel Core i5-6300HQ 2.3GHz 处 理 器 与 GTX1060 6GB 独 立 显 卡 的 笔 记 本 电 脑 。 摔 倒 检 测 算 法 的 实 验 模 型 LSTM 是基于上述捕捉骨骼策略提取的所有摔倒骨骼数 据集进行训练。将整体 3 个数据集按 8:2 比例分成训练集 和测试集。模型训练批次大小为 256. 初始学习率设置 为 1×10-4. 训练 80 轮, 在第 20 轮与第 40 轮微调学习率 为原来的 0.5 倍, 使用 Adam 优化梯度下降, 权重衰减 1× 10-4. 其余采用默认参数。
3.2 实验分析
对骨骼捕捉策略进行实验, 实验效果如图 8 所示。 绿色框是 RiamRPN++单目标跟踪框, 为了跟踪算法能更 稳定地跟踪目标, 人工框的区域应该尽量小。因为姿态 估计算法需要较为完整的人物图像输入才会有更好的结 果, 因此采用基于跟踪框延伸的红色扩展框作为姿态估 计算法的输入数据, 绿色框仅作跟踪使用。蓝色框为YOLOv5 的目标检测算法的检测框。当检测框与扩展框 的 IOU 在 0.8~0.9 区间时, 就会使用检测框为跟踪框进行 修正。当 IOU 大于 0.9时, 选择目标检测算法作为姿态估 计算法的输入, 当检测框没有或者其小于 0.8时, 则使用 扩展框作为姿态估计算法的输入, 起到互补的作用。这 样一方面可以过滤掉场景中的其他检测框, 另一方面可 以纠正单目标跟踪算法的跟踪轨迹, 使输入到 HRnet 姿 态估计算法中的画面更适合, 从而提取更适用的骨骼数 据。从图 8 第一行视角也可以看到追踪算法始终稳定地 跟 踪 着 动 作 执 行 者, 而 且 图 8 中 第 一 行 全 部 帧 以 及 Frame126 与 Frame127 背景都出现了额外的目标, 但并无 提取出多余动作者的骨骼点。当第二行 Frame159 运动目 标消失在画面时, 目标跟踪框依旧在提取骨骼点, 但画 面右上角显示出骨骼的平均为 0.213 8 且并无高 IOU 的检 测框, 此时并不会存储到训练数据中。当 Frame197 重新 出现运动目标时, 单目标跟踪算法会重新捕捉并追踪。 实验效果表明骨骼捕捉策略可提取较高质量的骨骼数据, 减少大量的人工标注成本。

对摔倒检测优化框架中的系统逻辑优化进行效果实 验对比, 实验效果如图 9 所示。本文将同一个视频输入 到经过摔倒检测优化框架 (第一行) 以及没有经过优化 框架的摔倒检测系统 (第二行) 进行测试。从第 144 帧、 204 帧 和 第 214 帧 可 以 看 到, 第 一 行 与 第 二 行 人 物 的 Bounding Box 都不相同。优化策略的 Bounding Box 要比 Yolo 检测框小且变化是更加稳定的, 这是因为优化策略 的 Bounding Box 是基于骨骼点向外延伸。检测框更小的 变化更有利于跟踪。从后面 144帧摔倒到 295帧的完全站 立可看到, 优化策略一直捕捉到跟踪目标并稳定分配为 ID2.而普通策略在 260 帧中已丢失了原来的 ID4. 并在 295 帧开始重新分配了 ID5.虽然从 204 帧中多目标跟踪 算法跟踪了 YOLOv3 误检的环境中的凳子, 使得第一行 和第二行所分配的 ID 都不是从 1 开始。但从 144 帧开始, 普通策略的系统对凳子和人物的 ID 分配已经历多次的变 化。这是因为优化策略可继续对凳子进行跟踪并对低置 信度的骨骼点进行 FalseSkeleton 的标记, 从而不会输送到后续的动作判断模型中。此实验说明本文的摔倒检测 优化方法可以不牺牲算力的前提下使得摔倒检测系统对 目标的跟踪更稳定, 使得误判率更低。
图 9 同样是对经过摔倒检测优化框架中的数据预处 理的实验效果对比。本文的研究目的并非是摔倒检测模 型, 因此只选择了简单的 3 层 LSTM 模型进行训练。模 型对数据集的测试集精度达到了 93%。可以看到在模型 很好地学习到了本文基于骨骼捕捉策略所获得的较高质 量的数据集, 并能在现实视频中很好地检测出人物的动 作。如 144 帧中的 Fall Down, 204 、214 、260 的up (第 一行中因丢失目标而失去 up 动作判断) 以及 295 帧的 walking 动作。在显示黑框中, 动作可视化后面都是模 型输出对于当前动作的概率值, 如第二行的 260 帧与 295 帧, 因为当前帧提取到的骨骼点置信度较高, 模型 对其动作概率值判断约 65% 和 78%。这样更加贴合现实 的逻辑。
4 结束语
为了将在摔倒数据集上训练的老人摔倒检测系统能 更好地泛化到现实世界中, 本文提出了一种骨骼捕捉策 略, 经试验效果显示, 它能过滤摔倒数据集的干扰, 并 提取出适合训练的骨骼数据, 可以大幅度减少标注者的 工作量。为了进一步使得摔倒检测系统能更适用于现实 世界, 本文还介绍了一种摔倒检测优化方法, 它包括数 据预处理优化及系统逻辑优化。经实验对比验证, 基于 数据预处理优化策略训练的 LSTM 模型, 在逻辑优化的 系统中能准确识别自拍摄的测试视频, 在 GTX1060 显卡 中达到约 45 fps, 模型的准确率达到 93%。优化检测方法 不仅提高整体系统的稳定性, 还降低系统误判率。本论 文的工作离部署到边缘设备上还有一定的距离, 因此未 来的工作中需要在保证摔倒系统各部分精度的前提下进 行更加轻量化的实验, 以更低的算力成本植入到嵌入式 设备中。
参考文献:
[1] 张拓红 . 人口老龄化对健康服务体系的影响[J]. 北京大学学 报:医学版, 2015. 47(3):4.
[2] 薛源 . 基于多传感器的老人跌倒检测系统的研究与应用[D]. 武汉:武汉理工大学, 2011.
[3] Feng G, Mai J, Ban Z, et al. Floor Pressure Imaging for Fall De ⁃ tection withFiber-Optic Sensors[J]. IEEE Pervasive Computing, 2016.15(2): 40-47.
[4] Jefiza A, Pramunanto E, Boedinoegroho H, et al. Fall detection based on accelerometer and gyroscope using back propagation [C]// 2017 4th International Conference on Electrical Engineer⁃ ing, Computer Science and Informatics (EECSI). IEEE, 2017.
[5] 赵中堂 , 陈继光 , 马倩 . 摔倒检测中的样本失衡问题研究[J]. 计算机工程与应用, 2017. 53(23):142- 146.
[6] 戴乔森,何毅斌, 陈宇晨,等 . 基于圆周拉普拉斯算法的机械零 件边缘检测方法研究[J]. 机电工程, 2021.38(1):98- 102.
[7] Feichtenhofer CX3D: Expanding Architectures for Efficient Vid ⁃ eo Recognition[J]. IEEE, 2020.
[8] G. Johansson. Visual perception of biological motion and a model for it is analysis[J]. Perception and Psychophysics, 1973. 14(2): 201 –211.
[9] Yin Zheng, Dongping Zhang, Li Yang, Fall detection and recogni ⁃ tion based on GCN and 2D Pose[C]// The 2019 6th International Conference on Systems and Informatics (ICSAI 2019).
[10] 卫少洁, 周永霞 . 一种结合 Alphapose 和 LSTM 的人体摔倒检 测模型[J]. 小型微型计算机系统, 2019. 40(9):1886- 1890.
[11] 郝永飞,唐旭晟,程良利 . 基于机器视觉的自动仪表盘指针检 测研究[J]. 机电工程, 2022.39(1): 134- 140.
[12] Goudelis G, Tsatiris G, Karpouzis K, et al. Fall detection using history triple features[C]//Proceedings of the 8th ACM Interna⁃ tional Conference on PErvasive Technologies Related to Assis ⁃ tive Environments,2015.
[13] Martínez-Villaseñor L, Ponce H, Brieva J, et al. UP-fall detec ⁃ tion dataset: A multimodal approach[J]. Sensors, 2019. 19(9): 1988.
[14] Auvinet E, Rougier C, Meunier J, et al. Multiple cameras fall da⁃ taset[J]. DIRO-Université de Montréal, Tech. Rep, 2010. 1350.
[15] Sun K, Xiao B, Liu D, et al. Deep high-resolution representa⁃ tion learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog⁃ nition. 2019: 5693-5703.
[16] Chen Y, Wang Z, Peng Y, et al. Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE con⁃ ference on computer vision and pattern recognition . 2018: 7103-7112.
[17] Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2d pose estimation using part affinity fields[C]//Proceedings of the IEEE conference on computer vision and pattern recognition . 2017: 7291-7299.
[18] Núñez-Marcos A, Azkune G, Arganda-Carreras I. Vision- based fall detection with convolutional neural networks[J]. Wire⁃ less communications and mobile computing, 2017.
[19] Berlin S J, John M. Spiking neural network based on joint entro ⁃ py of optical flow features for human action recognition[J]. The Visual Computer, 2020(3):1- 15.
[20] Wang P, Li W, Ogunbona P, et al. RGB-D-based Human Mo⁃ tion Recognition with Deep Learning: A Survey[J]. Computer vi⁃ sion and image understanding, 2017. 171(6):118- 139.
[21] Manzi A, Dario P, Cavallo F. A human activity recognition sys ⁃ tem based on dynamic clustering of skeleton data[J]. Sensors, 2017. 17(5): 1100.
[22] Kuznetsova A, Maleva T, Soloviev V. Detecting apples in or⁃chards using YOLOv3 and YOLOv5 in general and close-up im ⁃ ages[C]//International Symposium on Neural Networks . Spring⁃ er, Cham, 2020: 233-243.
[23] Mao Q C, Sun H M, Liu Y B, et al. Mini-YOLOv3: real-time ob⁃ ject detector for embedded applications[J]. IEEE Access, 2019 (7): 133529- 133538.
[24] Li B, Wu W, Wang Q, et al. Siamrpn++: Evolution of siamese vi ⁃ sual tracking with very deep networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog⁃ nition. 2019: 4282-4291.
[25] Shi L, Zhang Y, Cheng J, et al. Two-stream adaptive graph con⁃ volutional networks for skeleton-based action recognition[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 12026- 12035.
[26] Liu J, Shahroudy A, Perez M, et al. Ntu rgb+ d 120: A large- scale benchmark for 3d human activity understanding[J]. IEEE transactions on pattern analysis and machine intelligence, 2019. 42(10): 2684-2701.
[27] Bewley A, Ge Z, Ott L, et al. Simple online and realtime track ⁃ ing[C]//2016 IEEE international conference on image process ⁃ ing (ICIP). IEEE, 2016: 3464-3468.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/58360.html