SCI论文(www.lunwensci.com)
摘要:生命周期评价是一种分析机械产品的全生命周期环境影响的有力工具, 但是其前期的清单收集工具极其繁琐且耗时, 为了 简化机电产品生命周期评价的步骤中清单数据收集工作, 降低清单数据的数据填充难度, 提出了一种基于 BP 神经网络的清单数据 智能填充算法 。该算法基于文本相似度和数据相似度算法分别计算该零部件的各项参数与案例库中已知零部件的各项参数信息之 间的相似度, 并把这些参数的相似度信息作为神经网络输入, 经输出层计算出零部件之间整体的相似度, 分别求取所有零部件和 缺失数据的零部件之间的相似度信息并排序, 从而求得零件库中与缺失信息的零部件之间最相似的零部件, 用求出的最相似的这 个零部件的信息完成缺失数据的零部件信息的智能填充。
关键词 :机电产品清单数据,BP 神经网络,相似度,智能补全
Research on Intelligent Completion Algorithm of Mechanical and Electrical Product List Data Based on BP Neural Network
Ding Yongxin1. Li Tao2 ※, Guo Zhiwei1. Zhang Hongchao3
( 1. School of Mechanical Engineering, Dalian University of Technology, Dalian, Liaoning 116081. China;
2. Institute of Major Equipment Design, Dalian University of Technology, Dalian, Liaoning 116081. China;
3. Department of Industrial Engineering, Texas Tech University, Lubbock, TX76001. USA )
Abstract: Life cycle assessment is a powerful tool for analyzing the environmental impact of mechanical products in the whole life cycle , but its early inventory collection tool is extremely cumbersome and time-consuming . Because of the difficulty of data filling in data, an intelligent filling algorithm for inventory data was proposed based on BP neural network . The similarity between the various parameter information, and the similarity information of these parameters was used as the input of the neural network , the overall similarity between the parts was calculated through the output layer, and all parts and parts with missing data were obtained respectively . The similarity information between them was sorted, so as to obtain the most similar parts in the parts library to the parts with missing information , and the obtained information of the most similar parts was used to complete the intelligent information of parts with missing data filling .
Key words: mechanical and electrical product list data; BP neural network; similarity; intelligent completion
0 引言
近些年, 机械制造业在迅速地发展, 与此同时造成 了非常严重的环境问题, 如全球变暖 、生态恶化 、水体 污染 、水体富营养化等, 严重阻碍了可持续发展的进 程[1-2] 。经研究表明, 机电产品在制造和使用阶段是影响 全球环境生态的最重要因素之一, 据统计, 机电产品的 生产制造过程产生污染物占到了全球污染物排放量的 73%以上[3] 。而生命周期评价 (Life cycle assessment) 是 可以从产品的全生命周期角度量化潜在环境影响的方法, 可以用来评价产品设计方案中表达的产品生命周期内经 历的环境影响, 是一个有效的方案决策支持方法[4] 。但 是由于生命周期评价所需的清单数据繁多, 并且追逐源 头所需的物力和精力巨大, 因此进行生命周期周期评价的最难的问题就是清单数据中缺失数据的填充。
刘云等[5]利用对称加权算法对数据分析中数据集缺 失矩阵进行补全, 通过正则化方法进行低秩矩阵的分解 补全结合块坐标下降和交替最小二乘法进行数据补全 。 杨亚洲等[6]基于 k-means 聚类方法的曲线按比例伸缩置换 法提出了一种缺失数据的补全算法用于填充历史电力负 荷缺失的数据, 与传统的插值法和平均日负荷曲线补全 法相比, 预测的准确性提高了很多 。刘琚等[7] 提出了一 种基于多向延迟嵌入的平滑张量补全算法分类框架用于 补全 BraTS 脑胶质瘤影像数据, 并于 7 种基线模型进行了 比较, 得到最后的准确率高达 91.31%。
本文通过分析机电产品物料清单的数据类型, 借助 莱温斯坦距离和神经网络提出了一种清单数据智能补全方法, 可用于 LCA 软件在评价过程中自动补全缺失的 数据。
1 生命周期评价
生命周期评价可以对机电产品的全生命周期阶段所 造成得影响进行定量分析 。经过很多年的发展己经在产 品的生产制造中发挥作用[4] 。其过程主要包括 4 个步骤: 目的与范围的确定 、清单分析 、影响评价和结果解释。
( 1 ) 目的和范围的确定
确定评价的 LCA 评价目的, 根据评价的机电产品的 特点和目的划分评价范围。
( 2 ) 清单分析
清单分析是最浪费时间和精力的阶段, 即对机电产 品整个生命周期中的输入输出进行统计和量化, 如果清 单数据存在数据缺失则需要对评价范围进行修改。
( 3 ) 影响评价
影响评价指根据清单分析的结果, 对机电产品生命 周期中潜在的环境影响进行量化 、分析和评价。
( 4 ) 结果解释
结果解释是对机电产品进行分析后得到结论和建议的 阶段, 在这一阶段中对重要的输入、输出、评价方法进行 不确定性检查以及选择性评价, 并对结论和建议予以说明。
然而以上步骤的顺利执行都依赖于清单数据的完整 性和准确性, 如果存在清单数据缺失, 那么 LCA 分析的 结果会存在一定准确性的问题 。因此本文根据机电产品 物料清单的特征, 基于莱温斯坦距离和神经网络提出一 种清单自动补全算法, 可以实现案例的重复利用, 减少 清单数据收集的准备工作。
2 基于 BP 神经网络的补全算法
2.1 物料清单
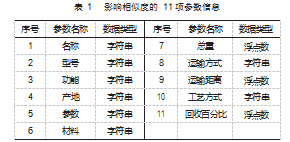
机电产品的物料清单指进行生命周期评价的数据清单, 其中包括了机电产品的生命周期信息, 比如: 零件 名称 、重量 、产地 、零件型号 、材料 、运输距离 、运输 方式 、工艺 、回收等信息 。加上和这些信息相关的其他 信息一共 11 项, 如表 1 所示。
2.2 BP 神经网络及数据补全
BP 神经网络是由科学家 Rumelhart 和 McClelland 提出 的概念, 是一种根据误差反向传播进行训练的多层前馈网络[8], 主要思想是梯度下降, 利用梯度搜索技术使得神 经网络的输出期望值和输出真实值的差值的均方差最小。
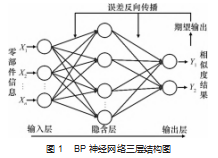
BP 神经网络结构包含一个输入层 、一个或多个隐含 层和一个输出层 (如图 1 所示), 通过权值和阀值将相邻 层的神经元连接起来 。其中隐含层所包含的神经元数量 需要通过公式计算得到。
结合 2. 1 节, 一个零部件的信息一种由 11 种, 但是 因为每一种信息在相似度计算时所占的权重不同, 所以 并不能直接加和, 同时因为 BP 神经网络天生就可以用于 计算输入参数的权重信息, 因此本文采用 BP 神经网络来 进行相似度结果的计算。
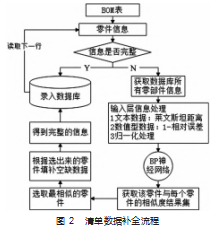
因为三层的神经网络有较好的函数逼近的作用, 并 且网络结构简单, 因此本文采用三层 BP 神经网络结构, 其计算相似度补全数据的流程如图 2 所示。
2.3 BP 神经网络设计
2.3. 1 训练样本选择
训练样本来自零件库 。每条样本包含 3 大部分, 当 前零件的 11 项参数信息 、比较对象的 11 项信息以及两个 零件是否一致, 共计 220 条数据。
2.3.2 输入参数处理
因为输入的参数含有文本类型 (如材料 、运输方式、 工艺方式等), 也有含有数字类型的数据 (如运输距离、 回收百分比等), 因此这 11 项参数并不能直接输入神经 网络, 需要先进行文本类数据处理, 数值类数据处理。
( 1 ) 文本类数据相似度计算
文本数据相似度的计算, 常用的计算文本相似度的 方法包括欧氏距离、曼哈顿距离、闵科夫斯基距离、余弦 夹角相似度以及切比雪夫距离等[9], 但是大多都针对复杂 文本, 本文所使用的文本多是单个词语不包含主谓宾等句 子结构以及不需要进行分词处理, 因此本文计算文本的相 似距离采用基于字符的编辑距离的一种莱文斯坦距离。
莱文斯坦距离即由一个字符串变成另一个字符所需 的最少操作次数 。允许的操作包括删除字符 、替换字符、 插入字符[10] 。在数学上, 如式 ( 1 ) 所示, leva, b (i,j ) 是字 符串 a 的前 i 个字符和字符串 b 的前j 个字符之间的距离。
■ max (i,j ) min (i,j ) = 0
leva, b (i,j ) =〈|min〈b(b)leva, b (i - 1.j - 1) + 1(ai ≠ bj )( 1 )
输入层的参数可能受文本类数据长度的影响, 编辑 距离会大小不一, 而变化幅度大的输入值会增加权重和 阈值的调节难度, 因此需要将样本数据归一化到[0. 1] 之间 。本文所采用的归一化方法如式 ( 2 ) 所示 。Xmin 代 表字符串 A 和 B 之间最少字符个数, Xmax代表字符串 A 和 B 之间最多字符个数, X′ 代表归一化结果。
Xi - Xmin Xmax - Xmin
( 2 ) 数值型数据相似度计算
对于数值型数据, 计算当前值和目标值之间的相对 误差, 然后 1 减去相对误差即为该参数的相似度[11], 即 式 ( 3 ) 所示, 其中 A 代表当前值, B 代表目标值, Dnum表示A 和 B 之间的相似度。
激活函数 ( Activation Function ) 是运行在人工神经 网络的神经元上的数学函数, 它负责把输入端映射到输 出端 。本文的算法所采用的激活函数为 Sigmoid 函数[12], 该函数是生物学中常见的 S 型函数, 也称逻辑斯谛回归 函数 。如式 ( 4 ) 所示:
f (x) =( 4 )
损失函数是用来评价算法模型的真实值和预测值之 间的差异程度, 损失函数选择的越好, 算法模型的性能 也就越好 。不同的模型采用的损失函数也不是固定不变 的, 根据实际应用场景, 本文的损失函数选择交叉熵损
失函数, 如式 ( 5 ) 所示:
L (, y ) = -y log () - (1 - y )log (1 -) ( 5 )
2.3.4 输入层 、输出层 、隐含层数量
输出层对应着输入参数的个数, 有几个参数, 输入 层的结点个数就设置几个, 根据对输入样本的分析, 输入 层神经元的数量设置为 11 个, 分别对应 11 项参数信息。
输出层对应着预测的结果, 因为该神经网络预测的 模型的结果只有两个, 一致和不一致, 因此输出层的神经 元的数量设置为 2 个, 分别对应一致和不一致两个结果。
隐含层的设计是训练神经网络的最为重要的一环, 隐 含层最主要的就是用来确定神经元的数量。隐含层神经元 数量太多会使神经的网络学习时间变长, 太少会使非线性 网络逼近的精度降低, 与此同时也会使模型的容错性误差 增大。一般通过式 ( 6) 来确定神经元的结点的数量, 即:
m =+ a ( 6 )
式中: n 为输入层神经元数量; l 为输出层神经元数量; m 为隐含层神经元数量; a 通常取[1. 10]之间的常数。
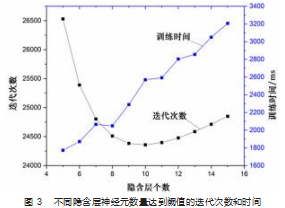
计算时, m 的值可以用四舍五入法进行相应的调整。 分别测试在达到 98% 的准确率条件下隐含层不同神经元 数量的训练次数和训练时间, 训练结果如图 3 所示 。 因 此隐含层神经元数量确定为 10 个。
2.4 实验验证
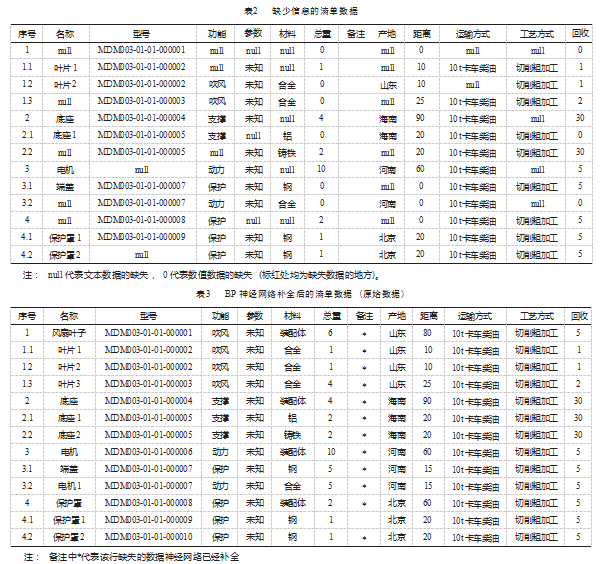
原始数据集即表3 (测试数据和补全数据一致), 手动 删掉一些信息 (文本类数据填null, 数值型数据填0), 测试 数据如表2所示。将表2的信息输入神经网络进行补全测试。
补全后的数据如表 3 所示, 所有空缺数据均已补全, 补全零部件的信息在备注里会提示*, 没有缺失数据备注 就为空 。和原始完整的数据进行对比, 发现该相似度计 算模型补全了所有相似信息并且正确率达 100%。
3 结束语
本文通过分析机电产品的数据清单的特征, 将缺失 数据分为文本型数据和数值型数据, 针对不同类型的数 据分别采用不同的相似度就算方法, 通过一个设计好的 三层的 BP 神经网络, 将一个零部件的 11 项相似度信息 输入到神经网络中, 从而计算出与之最为相似的零部件, 从而智能补全缺失数据 。经过实验验证, 本文所提出的缺失数据智能补全算法可以有效地利用已有的数据案例 并填充缺失数据, 极大地简化了生命周期评价过程中清 单数据的收集工作, 加快了机电产品 LCA 分析的速度。
参考文献:
[1] 方圆, 张万益, 曹佳文,等 . 我国能源资源现状与发展趋势 [J]. 矿产保护与利用, 2018(4): 34-42.
[2] RAMANI K, RAMANUJAN D, BERNSTEIN W Z, et al. Integrat⁃ ed sustainable life cycle design: a review [J]. 2010.
[3] KONG L, WANG L, LI F, et al. A New Sustainable Scheduling Method for Hybrid Flow-Shop Subject to the Characteristics of Parallel Machines [J]. IEEE Access, 2020(8):79998-80009.
[4] 郑秀君, 胡彬 . 我国生命周期评价 (LCA) 文献综述及国外最 新研究进展 [J]. 科技进步与对策, 2013. 30(6): 155-60.
[5] 刘云, 郑文凤, 张轶 . 对称加权算法对数据矩阵补全的优化研 究 [J]. Journal of Sichuan University (Natural Science Edition), 2021. 58(4): 043001.
[6] 杨亚洲, 钱秋明, 梁鸭红 . 基于 k-means 聚类方法的曲线按比伸缩置换缺失数据补全法 [J]. 电气自动化, 2021. 43(2): 3.
[7] 刘琚, 杜若画, 吴强, 等 . 一种基于张量分解的医学数据缺失模态的补全算法 [J]. 数据采集与处理, 2021. 36(1): 8.
[8] 闻新 . 应用 MATLAB 实现神经网络[M]. 北京:国防工业出版 社, 2015.
[9] 陈晓琳 . 基于迁移学习的信息流行度跨域预测研究 [D]. 北京: 对外经济贸易大学,2021.
[10] 车万翔,刘挺,秦兵,等 . 基于改进编辑距离的中文相似句子检 索 [J]. 高技术通讯, 2004. 14(7): 5.
[11] 陈宁 , 陈安 , 周龙骧 . 混合类型数据相似度及网格聚类算法 [C]//第十八届全国数据库学术会议论文集(研究报告篇), 2001:161- 164.
[12] 吴佑寿,赵明生 . 激活函数可调的神经元模型及其有监督学 习与应用 [J]. 中国科学:E 辑, 2001. 31(3): 10.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/ligonglunwen/56583.html