SCI论文(www.lunwensci.com):
摘 要 :人工智能模型的自动调优技术能够以较低资源成本提供云数据中心的高性能智能服务。然而,人工智能模型和硬 件设备具有异构性,云数据中心执行自动调优操作会产生大量计算时间,占用算力资源,产生能耗成本。针对此问题,本文设 计面向云计算数据中心的人工智能模型自动优化框架。提出人工智能模型候选配置项过滤方法,利用模型构建、特征提取、候 选项探索、配置查询等技术对候选项搜索空间重新采样,将高效候选项替换低效候选项。在算子优化层面,框架分批并行执行 计算组件实现的硬件测量,避免连续探测搜索空间。在模型优化层面,根据多人工智能模型的相对性能加速优先跨集群的计算 组件优化。该框架旨在面向不同人工智能模型,降低人工智能模型推理延迟,减少云计算数据中心能耗,从而提升人工智能模 型自动调优的成本效益。
关键词 :云数据中心 ,人工智能 ,模型优化 ,配置探索
Design of Microservice Application Performance Analysis Framework for Container Cloud
ZHU Taotao, RAO Xianming
(Jiangxi Jinlu Technology Development Co., Ltd., Nanchang Jiangxi 330025)
【Abstract】: The automatic tuning technology of artificial intelligence model can provide high performance intelligent services of cloud data center at lower resource cost. However, artificial intelligence models and hardware devices are heterogeneous, and automatic tuning operations in cloud data centers will generate a lot of computing time, occupy computing resources, and generate energy consumption costs. To solve this problem, this paper designs an artificial intelligence model automatic optimization framework for cloud computing data center.An artificial intelligence model candidate configuration item filtering method is proposed, which uses the techniques of model construction, feature extraction, candidate item exploration and configuration query to resample the candidate search space and replace the inefficient candidate item with the efficient candidate item. At the operator optimization level, the framework performs hardware measurements implemented by compute components in batches in parallel, avoiding continuous probing of the search space.At the level of model optimization, the optimization of computing components across clusters is prioritized according to the relative performance acceleration of multiple AI models. The framework is designed to reduce the reasoning delay of AI models for different AI models and reduce the energy consumption of cloud computing data centers, thereby improving the cost-effectiveness of automatic tuning of AI models.
【Key words】:cloud data center;artificial intelligence;model optimization;configuration exploration
0 引言
人工智能模型用来执行复杂的计算机视觉和自然语 言处理任务,在工业界和学术界变得越来越重要 [1]。云 计算数据中心将创新人工智能模型与不断增长的用户需求相结合,提供人工智能服务的基础设施,包括专门用 于提供人工智能服务的 GPU、FPGA 等专用硬件设备 [2]。 云数据中心创建具有高精度和低延迟推理的人工智能模 型,从而在计算资源和能源消耗方面实现较高的系统吞吐量和成本效率。达到该目标的有效技术手段是优化人 工智能模型的单个计算组件,提供跨越缓存及内存的访 问模式、线程处理和硬件内在函数的目标设备特征 [3]。 执行计算组件优化是一项复杂且耗时的任务,需要实现 面向目标设备的人工智能模型计算组件自动优化。在人 工智能编译器 TVM 的推动下,自动调优通过对大型计 算组件参数空间的迭代探索实现最小化计算组件延迟, 需要对每个目标设备的候选项进行数万次高计算成本的 迭代测量。自动调优过程需要相当多的时间和计算资源 成本才能完成,因此即使是小规模人工智能模型也必须 独立占用目标设备数小时才能提升性能 [4]。提供人工智 能服务的云数据中心需要针对特定人工智能模型配置硬 件设备约束条件,为大规模用户群体提供高性能和经济 高效的定制化自动调优支持。由于自动调优操作需要长 时间独占访问目标设备,且自动调优持续时间和等待时 间较长,人工智能服务吞吐量和可用性较低,从而导致 较高能耗以及云提供商的经济损失。
1 技术背景
人工智能模型在图像识别或语言学习等领域提供类 似认知的能力,由表示为有向无环图的多层深度神经网 络组成,其中节点表示执行卷积、批量归一化等行为的 人工智能算子,边表示算子间的数据依赖关系。人工智 能运算符表示计算组件所执行的矢量操作,包括数据获 取、提交等 CPU 代码和 GPU 内核加速器代码,在目 标设备中作为实例化执行。具有更大数量复杂算子的人 工智能模型通过执行更多浮点操作,表现出更高计算 精度 [5]。人工智能模型的创建、数据量的增长和用户需 求的涌现,使得专门提供人工智能服务的云数据中心 建立。此类云数据中心由配备了图形处理单元 GPU 加 速器设备的计算机服务器集群构成,用于执行人工智 能模型的推理计算组件,其计算速度远远快于传统的 CPU。每天执行数万亿次人工智能推理操作的生产系统 如 Facebook,依托云数据中心所提供的人工智能服务 实现高性能模型推理,以满足服务水平协议并保障服务 质量。云数据中心计算成本包括 CPU、GPU、网络等 算力资源和时间开销,进而共同驱动系统能耗的产生。
人工智能模型优化可以有效减少目标设备的计算组件 延迟, 从而实现云数据中心高性能和经济高效的模型推 理 [6]。模型优化通过计算框架的计算组件或 TVM 人工智 能编译器实现。人工智能编译器能够将高级人工智能模型 定义编译为特定设备的二进制文件,从而更大程度地控制 推理行为。模型优化操作包括算子融合、代数简化、数 据缓冲区重用等高级人工智能模型结构的目标与设备转 换,以及设备缓存、矢量化、计算区域映射等低级计算组件转换。手动执行计算组件优化是耗时的任务,需要为 每个目标设备执行数百个计算组件并降低计算组件延迟。
自动调优是面向目标设备计算组件实现的人工智能模 型自动优化技术,通过自动搜索可能的实现参数空间, 或 者根据给定规则自动生成算子实现,以产生不同版本低 级中间表示。自动调优是计算时间和能耗密集型操作, 即 使小型人工智能模型也需要数十小时才能实现单个目 标设备的延迟改进。自动调优的候选空间搜索、代码约 简和计算组件编译等操作,使得物理资源会经历使用峰 值。此外,具有众多复杂人工智能模型算子的计算组件 实现空间巨大且呈现非线性,自动调优需要在孤立的目 标设备中反复执行数千个候选计算组件以确保准确的延 迟测量。大规模人工智能模型数量的增加,使得自动调 优需要在众多计算平台和目标设备上执行很长一段时 间。而且,人工智能模型和目标设备的任何架构更改, 都需要重复执行自动调整。虽然人工智能模型优化在减 少人工智能服务的模型推理延迟方面是有效的,但自动 调优需要大量的时间、计算资源和能源成本才能完成, 使得云数据中心可用性和吞吐量降低,并产生更高能耗。
2 人工智能模型自动优化框架
2.1 设计思路
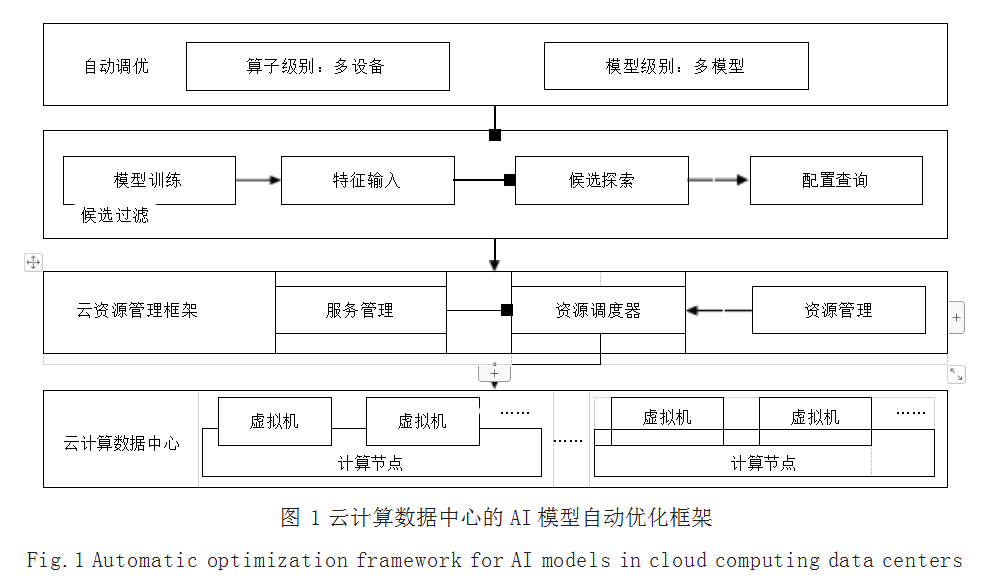
人工智能模型自动优化框架作为组件在云数据中心 运行以优化模型训练过程,并准备在云数据中心部署人 工智能模型,从而提升自动调优的成本效益。这些模型 既可以来自人工智能服务提供商,作为云服务的一部 分,也可以来自用户提交的用于训练或部署的模型实 现。如图 1 所示,框架通过在算子和模型级别的增强, 实现低成本快速的模型自动调优。在算子优化级别,框 架执行基于神经网络的低效候选实现的过滤,根据预测 结果排除性能不佳的低效候选实现,并重新采样性能更 好的高效候选实现,从而加速自动调优过程收敛到足够 高效的算子实现。在模型优化级别,每个算子使用少 量硬件测量和完成人工智能模型周期延迟测量部分优 化,使得基于测量延迟提升提前完成。框架结合以上方 法可以优化跨多个基础设施平台服务器集群的人工智能 模型,对优化过程进行排名并根据相对延迟提升效果暂 停某些效果不佳自动调优过程。框架目标是通过自动调 整每个算子 ci (i=1…N) 来最小化人工智能模型的推理延 迟,其中 N 是人工智能模型算子数量。花费在优化每个 算子 ci 所需要的时间取决于其相对于模型中其他算子 cj 的延迟提升率,以及对整体模型延迟的改进影响,实现 目标是所有算子计算的延迟之和最小化。
2.2 低效候选实现过滤
创建人工智能模型,利用其中间层的输出,根据相似性查询候选项,并在硬件测量之前过滤掉前 n 个低效 候选项,具体包括以下步骤。
2.2.1 模型构建
设计具有 ReLU 激活函数的三层全连接网络 (FC)[7],使 用 Pytorch 实现和训练模型,最小化个体操作延迟的均 方误差。使用收集的数据点作为数据集,以 6 ∶ 2 ∶ 2 的比例将数据集分割为训练、测试、验证三个不同数据 集,在预测算子延迟之后,利用验证集进行超参数调 优。模型学习算子延迟和算子,以及候选和目标设备特 征之间的关系。
2.2.2 特征提取
为了捕获多维特征的非线性关系, FC 网络输入多 维向量,具体包括实现候选配置,其中每个条目是描述 配置低级优化参数的整数 ;目标设备及主机平台特征 ; 算子每秒能够进行的浮点运算次数 ;算子标识符 ;卷积 核大小、填充数量、步幅等算子参数表示等。在过滤过 程中,通过访问配置空间并构建嵌入分类特征提取每个 算子配置的输出数量,其中每个条目是大小为 k 的参数 向量,将连接的特征作为 FC 网络的输入。
2.2.3 候选项探索
自动调优需要降低测量低效候选项的成本,在实现 空间中探索广泛的点来识别高效候选项。使用 ε-greedy 策略,在自动调优过程中,早期对过滤后的候选对象加 以利用,并在每次成本模型更新后逐步降低候选对象过 滤的概率。这样,当自动调优器搜索策略和成本模型稳 定,空间探索就会收敛结束。
2.2.4 配置查询
如果前 n 个相似的候选项是低效候选项,框架会启 发式地裁剪现有候选项。通过使用余弦相似性在算子调优数据库中查询 top-n 相似的配置,在向量空间中识别 相似样本,进而利用 FC 网络的中间层输出来预测候选 延迟。基于启发式探索策略将修剪后的高延迟低效候选 样本替换为新样本,以确保探索过程的有效性。
2.3 自动调优
现有的自动调优器依次优化算子,在优化下一个算 子之前执行全部硬件测量,在所有算子被完全优化之后 完成。人工智能模型的延迟只能在所有算子都被优化之 后才能确定,因此在进行自动调优时,用户并不清楚已 实现的人工智能模型延迟。通过人工设置的阈值提前停 止自动调优的优化过程,但需要在每个算子的基础上执 行的,无法比较相对其他算子的改进。框架的自动调优 过程可以相对较早地发现表现良好的高效候选对象,并 通过算子和模型级别的调整来降低优化成本。
2.3.1 算子级别自动调优
框架将所有可调整算子放入队列中,并批量执行硬 件测量以自动调优。在调优周期结束后,每个算子已经 完成了一批测量,使用目前找到的最佳候选算子配置来 编译和评估人工智能模型。框架根据预测模型延迟改进 和优化成本之间的权衡,暂停或提前停止自动调优。提 前停止或暂停机制需要满足现有模型延迟小于设定阈 值,如果目标未在期望的成本内达到,框架将延迟减少 率与上一批进行比较。设 ΔTt 表示在时刻 t 的算子调整 的时间周期, Δvt 表示在 t 时刻算子调整前后的模型延迟 变化,通过算子调整模型性能改进比率为 :st=Δvt/ΔTt, 算子改进停止判定为 :(st-st-1)/st ≤ “。
当通过算子调整得到的模型延迟改进幅度小于 “ 时, 则暂停该算子的改进。框架通过检查模型延迟在给定时间 和能耗成本的情况下, 是否能够以足够的效率降低模型延迟以最大化优化效率。“ 作为调整阈值的超参数,表示改 进比率是否应大于 “,以避免在每批模型之间的增量性能 变化不显著的情况下过度调优,从而陷入局部最优。
2.3.2 模型级别自动调优
在调优集群内的多个模型时,可以将优化工作集中 在改进潜力最大的模型,并根据用户设置调整阈值或成 本目标。同时,可以在模型级别结合暂停方法,测量每 个批次的模型延迟。模型的相对加速是与机器集群内其 他模型的并发自动调优过程比较得到的。在批量自动调 优中,根据模型最近实现的延迟改善对模型进行排名, 实现多模型自动调优,并暂停表现最差的模型。在单个 模型完成批次间隔内同步跨机器集群的多模型自动调优 过程中,每个模型在进行比较之前针对几个批次进行优化。
3 结语
本文设计了一种面向云数据中心的人工智能模型自 动优化框架,旨在降低云数据中心人工智能服务计算组 件优化所需的执行时间和能耗成本。首先,提出人工智 能模型候选配置项过滤方法,基于历史经验知识的相似 度匹配,利用模型构建、特征提取、候选项探索、配置 查询等技术,通过对候选项搜索空间重新采样,将高效 候选项替换低效候选项,从而更快找到性能较优的计算 组件。进而,在算子优化层面,框架分批并行执行计算 组件实现的硬件测量,避免连续探测搜索空间,减少低 效候选项硬件测量次数,从而降低测量模型推理延迟。 最后,在模型优化层面,根据多人工智能模型的相对性 能加速来优先跨集群的计算组件优化。该框架能够提高 人工智能模型性能,同时降低自动调优能耗成本,为建 立提供人工智能服务的成本高效的云数据中心提供支撑。
参考文献
[1] 李大伟.基于人工智能的计算机应用软件开发技术分析[J]. 软件,2023,44(9):124-126.
[2] HAZELWOOD K,BIRD S,BROOKS D,et al.Applied Machine Learning at Facebook :A Datacenter Infrastructure Perspective[C]//Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture.IEEE,2018:620–629.
[3] CHEN T,MOREAU T,JIANG Z,et al.TVM:An Automated end-to-end Optimizing Compiler for Deep Learning[C]// Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation,2018:578–594.
[4] AHN B H,PILLIGUNDLA P,YAZDANBAKHSH A,et al. Chameleon:Adaptive code Optimization for Expedited Deep Neural Network Compilation[C]//Proceedings of the International Conference on Learning Representations, 2020.
[5] TAN M,LE Q.EfficientNet:Rethinking model Scaling for Convolutional Neural networks[C]//Proceedings of the 36th International Conference on Machine Learning, 2019:6105–6114.
[6] CHEN T,ZHENG L,YAN E,et al.Learning to Optimize Tensor Programs[C]//Advances in Neural Information Processing Systems,2018:3389–3400.
[7] NAIR V,HINTON G E.Rectified Linear units Improve Restricted Boltzmann Machines[C]//Proceedings of the 27th International Conference on InternationalConference on Machine Learning,2010:807–814.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/77202.html