SCI论文(www.lunwensci.com)
摘 要 :本文提出了一种结合特征向量和 Unicode 区块的语言自动识别方法。相较于传统基于统计的方法,该方法更加 直观、计算量较小,并能处理更广泛的语种。
关键词 :自动语种识别,Unicode区块,特征向量
Language
Li Jiayi
(North University of China, Taiyuan Shanxi 030051)
【Abstract】:This article proposes a language automatic recognition method that combines feature vectors and Unicode blocks. Compared to traditional statistical methods, this method is more intuitive, requires less computation, and can handle a wider range of languages.
【Key words】:automatic language recognition;Unicode block;feature vecto
引言
随着全球化不断加深, 我们正进入一个跨文化、多 语言的信息时代。在这样的背景下,自动语言识别不仅 成为了学术研究的焦点,也是许多商业应用、社交平台 和政府机构的核心需求。语言识别的速度和准确性直接 关系到信息的可获取性、可访问性以及多语言用户的体 验质量。通过对现有技术的创新结合,本文旨在为自动 语言识别领域带来新的视角和解决方案,有望推动该领 域的进一步研究和应用发展。
1 基于 Unicode 编码的语言识别
在本算法中,第一步是将字符按其 Unicode 编码 进行分类。Unicode 编码系统是一种将世界上几乎所有 字符按一定规则分配的唯一数字编号的方法。这种编码 方法是按语言和地区分类的,即特定的 Unicode 码位 范围代表特定的语言或字符集。因此,可以根据字符的 Unicode 编码确定其可能属于哪种语言。
Unicode 区块映射函数的构造如下 :
对于单个字符 c,定义了一个函数 U(c), 如式(1)所示 :
U(c)={B,ifStart_B ≤ x ≤ End_B} (1)
其中, Start_B 和End_B 是语言或字符集 B 的 Unicode 码位范围, x 是输入字符 c 的 Unicode 编码。通过这个 函数,可以将字符 c 映射到可能的语言或字符集 B。
例如,对于汉字,其在 Unicode 中的编码范围是 从 0x4E00 到 0x9FFF,那么对于任何一个字符,如果 它的 Unicode 码位在这个范围内, U(c) 函数就会返回 ‘Chinese’。
有了字符到语言的映射之后,就可以统计一段文本 中不同语言字符的频率。对于输入的一段文本 T, 首先 将其分解为一组字符 {c1.c2....,cn},然后,通过上面定义 的 U(c) 函数,可以得到这组字符的 Unicode 区块名称 的集合 {U(c1),U(c2),...,U(cn)}。
定义函数 N,其作用是计算一段文本中某种语言的 字符的频率,这个函数可以表示为如式(2)所示 :
N(T,B)=Σ(I(U(ci)=B)),i=1 ton (2)
这里的 I 是指示函数, 如果 U(ci)=B, 那么 I(U(ci)= B)=1. 否则 I(U(ci)=B)=0.这样, N(T,B) 就表示了文本 T 中属于语言 B 的字符的数量。
对于一段文本,认为其所属语言是其字符中出现最 多的语言。因此,需要找到使得 N(T,B) 最大的 B,这个 B 就是这段文本的语言。定义函数 M,它的作用就是找 到这个 B,如式(3)所示 :
M(T)=argmaxBN(T,B) (3)
这里的 argmax 表示找到使得后面的表达式最大的 参数,因此, M(T) 就是文本 T 所属的语言。
2 基于特征向量的语言识别
在上述 Unicode 区块语言识别中,可以很好地识 别出汉字、日文、韩文、阿拉伯文等语言。然而,对于 一些使用拉丁字母的语言,例如英文、德文、法文等, 仅通过 Unicode 区块来判断显然是不够的,因为它们 的 Unicode 区块都是相同的。因此,需要采用另一种 方法来识别这些语言,此处采用的方法是基于向量化的 语言识别,这种方法的基本思想是将一段文本转化为一 个向量,然后通过计算这个向量与预先定义的各种语言 模型向量的相似度来确定这段文本的语言。
首先,需要将一段文本转化为一个向量。将文本转 化为特征向量的过程是通过统计文本中每个拉丁字母的 频率来实现的,主要包含以下几点 :
(1)预处理 :将文本转化为小写,确保统计的 一 致性 ;
(2)统计频率 :对每个拉丁字母在文本中的出现次 数进行计数 ;
(3) 创建向量 :通过收集 26 个拉丁字母的计数, 构建一个长度为 26 的向量,表达式如式(4)所示 :
V(T)=[N(T, 'a'),N(T, 'b'),...,N(T, 'z')] (4)
其 中, N(T, 'a') 表 示 文 本 T 中 字 符 'a' 的 数 量, N(T, 'b') 表示文本 T 中字符 'b' 的数量,以此类推。
定义函数 L,它根据输入的语言返回一个语言模型, 如式(5)所示 :
L(B)=[N(B, 'a'),N(B, 'b'),...,N(B, 'z')] (5)
其中, N(B,'a') 表示语言B 中字符 'a' 的频率, N(B,'b') 表示语言 B 中字符 'b' 的频率,以此类推。
对于文本 T 和语言 B,定义它们的相似度为 S,表 达式如式(6)所示 :
S(T,B)=sqrt(Σ(V(T)[i]-L(B)[i])^2) (6)
其中, i 表示 26 个拉丁字母中的一个, V(T)[i] 和 L(B)[i] 分别表示文本 T 和语言 B 中字母 i 的频率。当文 本 T 与语言 B 越相似, 它们的字母频率分布就越接近, 因此 S(T,B) 的值就越小。
为了判断一段文本 T 可能属于哪种语言,将 T 与所 有已知的语言模型进行比较,然后选择相似度最大(即
S(T,B) 最小)的语言作为判断结果,如式(7)所示 :
B*=argmin(S(T,B)) (7)
其中, B* 表示判断结果, B 表示所有可能的语言, argmin 表示找出使得函数值最小的参数。
3 实验结果与结论
3.1 融合语种识别算法
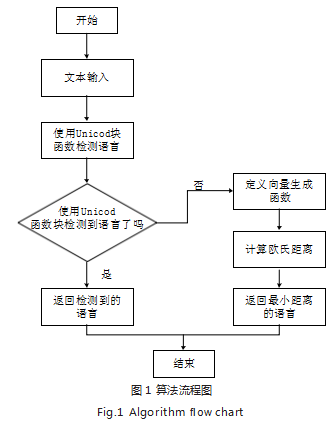
该算法首先将输入文本转化为特征向量,构建一个 长度为 26 的向量。同时,利用 Unicode 区块映射函 数,将文本中的字符与其所属的 Unicode 区块进行对 应,以便区分不同语种的字符。此算法先判断文本中是 否包含不同 Unicode 区块的字符,若是,则认为文本 可能为多种语种的混合文本,直接返回出现频率最高的 Unicode 区块对应的语种作为最终判断结果,而对于 只包含相同 Unicode 区块的字符文本,算法则通过计 算文本的特征向量与预先定义的语言模型之间的欧氏距 离,来判定文本的语种。
基于 Unicode 区块和特征向量融合的语种识别算 法流程图如图 1 所示。
3.2 实验结果
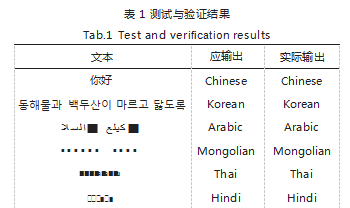
使用不同语种的文本来测试本文设计的语言识别方 法。具体的测试用例如表 1 所示。
3.3 实验结果分析
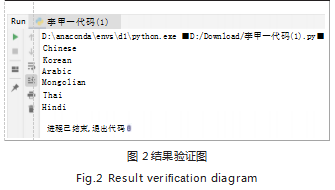
如图 2 所示为结果验证图,根据实验结果表明,本文方法在不同语言的识别上表现出色,具有以下优势 :
(1)准确性 :对于使用不同 Unicode 区块的语言, 我们的方法可以准确地识别出它们的语言。通过对文本 进行 Unicode 区块映射和特征向量生成,可以有效地 捕捉每种语言的独特特征,从而实现精确的语种识别。
(2)范围性 :本文方法在处理不同类型的语言时表 现出色。不论是使用汉字、日文、韩文等不同 Unicode区块的语言,还是使用相同 Unicode 区块的拉丁字母 语言,如英文、法文、德文等,都能通过特征向量的比 较,精确地识别出它们的语言。
(3)文本聚类能力 :通过比较不同语言的特征向 量,发现同一种语言的文本,它们的特征向量有很高的 相似度,而不同语言的文本,它们的特征向量差距明 显。这表明本文方法能够有效地将同一种语言的文本聚 类在一起,而将不同语言的文本区分开来。
4 结语
虽然本文方法已经表现出很高的准确性和实用性, 但仍有进一步的改进空间。未来的研究可以考虑优化特 征向量生成过程,探索更有效的特征表示方法,或者引 入更先进的机器学习技术来进一步提高算法的性能。同 时,随着语种识别任务在实际应用中的不断增多和复杂 化,我们可以拓展算法适用的语种范围,甚至可以将其 扩展到多语种混合文本的识别中。
参考文献
[1] CAVNAR W B,TRENKLE J M.N-Gram-Based Text Catgorization[J].2001(5):161-175.
[2] 蔡超.自动语种识别的研究与应用[D].成都:电子科技大学, 2016.
[3] 武光利.基于GMM的少数民族语自动语种识别系统设计[J]. 自动化与仪器仪表,2013(6):61-62.
[4] 刘杰.自动语种识别系统设计与实现[D].哈尔滨:哈尔滨工业 大学,2011.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/76925.html