



SCI论文(www.lunwensci.com)
摘要:目前,物联网数据呈现规模大、来源多、结构不一、冗余度高等问题,导致数据读写、存储和管理困难。通过分析在物联网多源异构数据的存储和管理上,本文总结出三个关键问题:数据完整性问题、负载倾斜问题和数据压缩问题,并提炼出对存储侧的性能要求。针对以上问题,对检索(ElasticSearch)、存储(HBase)、数据压缩等技术进行了分析,并提出设计方案。在设计方案中,提出数据存储前需要进行分类,丢弃不可用数据、压缩冗余数据、将常规数据进行冷热分区;在数据存储时设计Rowkey、优化索引;在数据存储后进行异常存储检测。通过正面物联网多源异构大数据存储和管理技术面临的窘境,提出设计建议,为今后的智慧交通、智慧小区、智慧城市等场景落地提供有力的借鉴。
关键词:冷热数据分区;存储异常检测;数据压缩;Hase-ElasticSearch
IoT Multi-source Heterogeneous Big Data Storage and Management Design
【Abstract】:At present,Internet of Things data presents problems such as large scale,multiple sources,different structure and high redundancy,which leads to difficulties in data reading and writing,storage and management.Through analysis,in the storage and management of multi-source heterogeneous data in the Internet of Things,this paper summarizes three key problems:Data integrity,load tilt and data compression,and extracts the performance requirements on the storage side.In view of the above problems,ElasticSearch,HBase,data compression and other technologies are analyzed,and a design scheme is proposed.In the design scheme,it is proposed that the data should be classified before storage,discard the unavailable data,compress the redundant data,and divide the conventional data into cold and hot zones;Designing Rowkey and optimizing index in data storage;Abnormal storage detection is performed after data storage.Through the dilemma faced by the multi-source heterogeneous big data storage and management technology of the Internet of Things,the design suggestions are put forward to provide a powerful reference for the future intelligent transportation,smart community,smart city and other scenes.
【Key words】:hot and cold data partition;storage anomaly detection;data compression;Hase-ElasticSearch
0引言
近些年来,随着信息化水平的不断提升,物联网技术高速发展,已广泛应用到了诸如智慧交通、智慧工业、智慧小区、智能城市等场景中。无论是何种场景的应用,都离不开传感器的应用。目前,我国已经出现上千种传感器,如压力传感器、光传感器、温度传感器、湿度传感器等。利用传感器与IoT技术,实时收集现实世界中物理对象的数据,进行实时监控和智能决策等,对构建智慧社区和智慧城市至关重要。但是,这些物联设备的厂商品牌、类型、通信协议、接口都各不相同,且随着5G和云边协同的发展,海量设备信息及设备产生的直接数据、衍生数据都呈爆炸式增长。由于数据来源多样、体积庞大、冗余性极强,使得存储的成本变高,而且耗费的时间也极长,给数据的读取和存储带来了极大的挑战。现有的数据存储和管理技术多样,但技术之间仍有壁垒,难以满足物联网大数据的存储管理需求,人与物、物与物的智能联动缺乏有效的交互。在这种情况下,高效存储海量多源异构数据对提升物联网数据交互管理的时效性,以及促进信息利用率的提高具有积极意义。
1 IoT多源异构大数据存储与管理面临的挑战与要求
物联网技术数据信息来自自然界的各种异构信息传感设备,主要的关键特征就是海量性、实时性、时序性和结构化性、有限周期性[1]。当前IoT多源异构大数据存储与管理面临数据信息管理难度高、没有规范的技术标准和管理体系、安全等问题[2]。除此之外,在存储上还存在数据完整性问题、负载倾斜问题、数据压缩问题。
(1)数据完整性问题。按照应用和数据特点可以将物联网数据分为三类:时序数据、消息数据和元数据。其中时序数据对于IoT应用程序来说很重要,如果物联网中产生的时序数据出现顺序不一致或者数据不准确的情况,则会影响数据的建模、分析和决策,导致产生不同的结果。在数据存储时也要考虑到产生数据的完整与否。
(2)负载倾斜问题。时序数据处理具有大数据都有的数据高并发、数据总量大的特点外,还有一个重要的特征就是时间序列化[3]。物联网产生的数据通常都具备时间序列特征,且物联网系统对时序数据具有较高的数据访问需求,要求达到高并发的写入吞吐、高效的时序数据查询分析。现有的物联网多源异构融合存取系统访问效率低下的一个原因就是负载不均衡,因此,在进行数据存储设计时需要考虑到负载倾斜问题。
(3)数据压缩问题。物联网中除了传感器的数据外,还存在大量的视频监控数据需要进行实时存储。在大数据时代下,每一秒产生的监控数据都是非常大的,如果直接将监控数据存入数据库中,容易导致数据存储不及时,出现数据堆积的情况,而且会占用大量的存储空间,因此可以考虑数据压缩的办法。但是在采集数据过程中,数据有可能出现抖动,导致数据顺序、间隔出现问题,进而影响数据压缩质量,造成压缩结果不可靠的情况。
数据存储和管理中,需要存储和管理各种类型的数据,包括文档、音频、视频、图像等,数据完整性问题、负载倾斜问题、数据压缩比问题很大程度上影响了数据的存储规模、检索性能,进而影响了智能分析与决策。因此,以上问题可以总结为对存储侧的几个性能需求:
(1)存储规模:支持海量设备信息、设备产生信息、衍生数据等数据的存储,数据量达到千万级甚至亿级。
(2)实时更新与计算:支持高并发、低延迟的数据更新;能够探测数据更新,并能够对更新后的数据进行实时计算,更新数据。
(3)任意字段组合检索:支持根据一个或多个字段值组合条件来检索设备元数据。
(4)高并发检索:在海量设备检索的结果集较大的场景下,需要支持并发检索以提升检索性能。
2 IoT多源异构大数据存储与管理的具体技术
物联网多元异构数据存储与管理时通常会基于分布式文件系统、分布式数据库、云数据库、NoSQL数据库[4]。本文将对涉及的分布式与集群技术概念、ElasticSearch技术和HBase技术结合、数据压缩技术展开分析,并基于这几个技术设计数据存储与管理方案。
2.1分布式与集群技术
由于单台服务器的性能无法满足高并发要求,因此提出将多台服务器集中在一起共同实现同一个功能模块,这个就是集群。集群处理不仅缓解了并发压力,还可以解决单点故障转移问题,具有高可用性和可伸缩性,且每台服务器并不是缺一不可。传统的项目系统由于其庞大的规模和开发维护的困难,引入了分布式系统,通过集中多台服务器来实现不同的功能模块或业务需求。分布式系统除了解决单机处理能力差的问题外,还能让系统更加稳定可用,与集群相反,分布式系统的每台服务器都缺一不可。分布式和集群技术由于双方的技术差异性,能互相弥补缺陷,因此,在解决多元异构大数据存储的时候,通常会同时出现。
2.2 ElasticSearch技术和HBase技术
海量性、多源异构性是物联网数据中的两大特点,普通数据库的检索一般不走索引,使用模糊查询时会返回大量的数据,且会出现耗时长、返回结果相关度不高的情况。因此在进行数据存储设计时,一定要考虑到检索的问题,将索引设计与存储设计结合在一起,并且在节省存储空间、提高存储性能时也要避免索引性能的降低。
ElasticSearch是一个分布式的检索引擎,可支持近乎实时的检索,同时支持存储和数据分析。ElasticSearch将数据分为多个分片(数据的最小单元块),均衡地存储在集群中的各个节点,一份完整的数据通常是由多个分片组成。其核心的分词处理、构建倒排索引是基于Lucene完成的,这也让ES对于模糊搜索非常擅长且搜索速度很快,返回的结果也会根据相关度和评分排序返回。因此,ElasticSearch在海量异构数据的复杂查询和全文检索上具有很大的优势,但是在数据一致性上、成本及存储上相对不足。
数据库主要分为两种类型,分别是关系型数据库和非关系型数据库。两者的区别就在于关系型数据库的典型数据结构是表,而非关系型数据库是文档、键值对或图形等。常见的关系数据库有MySQL、Oracle等,非关系型数据库有Redis、HBase、Neo4j等。针对物联网数据的特性,可以采用NoSQL数据库进行存储;而HBase是一种分布式存储的NoSQL数据库,具有强读写一致、自动分片、Hadoop/HDFS集成、高并发、低成本等优势,适合海量异构数据的低成本存储。但与ElasticSearch相反,HBase在海量数据的复杂查询、数据分析上相对一般。
HBase可实现低成本存储和高并发吞吐,而Elastic Search可实现高效检索,两者在数据结构、分布式、可扩展性上类似。因此,可将两者结合应用在物联网多源异构数据的存储与管理上,通过取长补短,相互弥补,可以同时实现对海量数据的高性能存储和检索。
2.3数据压缩技术
通俗来说,数据压缩就是用更短的字符代替重复出现的比较长的字符串,用以减少数据在存储、传输和处理时所需要的空间和时间。尤其是在物联网大数据中,大数据量的传输和存储都离不开压缩处理。数据压缩算法分为有损压缩和无损压缩,有损压缩是对数据本身的改变,减少了部分信息,在解压时无法还原搭配原来一样的文件,存在一定的损耗;无损压缩是对文件本身的压缩,使用算法实现对有关数据重复信息的表示,文件可以完全恢复而不影响文件本身。
在冗余数据处理中,针对文档资料或应用程序时可以采用无损压缩方式,保护数据的完整性。常见的无损压缩算法有霍夫曼编码(Huffman Coding)、LZ压缩算法、LZW压缩算法和Deflate压缩算法等。这一类算法的底层基本都是LZ77算法和霍夫曼编码。针对图像、视频和音频等数据则采用有损压缩方式,提高数据访问速度,节省存储空间。常见的有损压缩算法有JPEG压缩算法等,这一类算法的底层则是离散余弦变换(DCT),卡-洛变换(Karhunen–Loève Transform,KLT)等。
3设计方案
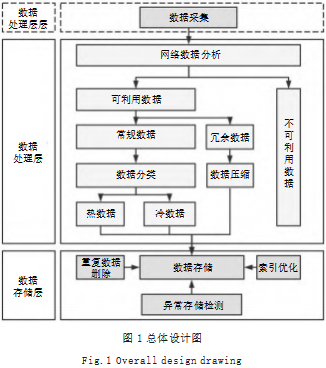
3.1总体设计图
如图1所示为总体设计图。由上往下为数据采集层、数据处理层、数据存储层。当接收到数据采集层的数据后,需要先对数据进行预处理,通过这样的方法,可以实现数据的高效存储。
(1)数据采集层:数据采集层可根据数据结构(结构化数据、半结构化数据、非结构化数据)的不同设计三个接口,将三种类型的数据在数据采集时便做好分类,便于将结构化数据、部分半结构化数据(如CSV文件数据)存储到数据库中,将部分半结构化数据(如PDF文件数据)、非结构化数据进行本地存储。
(2)数据处理层:第一阶段,将对网络传输过来的数据进行分析,分为可利用数据和不可利用数据,筛掉无用数据,节省存储空间;第二阶段,将可利用数据分为常规数据和冗余数据,并对冗余数据进行数据压缩操作,进一步节省存储空间;第三阶段,通过数据分类算法(Logistic回归模型)将常规数据分为冷数据和热数据,并分区存储,以节省存储空间,提高存储搜索效率。
(3)数据存储层:对ElasticSearch进行索引优化时,将需要检索的字段抽取出来形成单独的一条索引数据,并将设计好的Rowkey放进去(在数据处理层第三阶段时对常规数据进行了冷热分区,此时已经设计好了HBase的Rowkey),将原始数据根据Rowkey写入至HBase,检索数据根据Rowkey写入至ElasticSearch。在数据存储完成后,需要对原始数据进行异常存储检测。
3.2冷热数据分区
冷数据是用户访问频率较低且不受过载影响的数据,热数据则与之相反。虽然两类数据都分别存放在多个节点上,但通过对两类数据的冷热分类,可以尽可能地减少冷数据在内存中的占比,甚至减少备份,以保证用户对于冷热数据的访问请求达到负载均衡。冷热数据分区的步骤如下:
(1)数据预处理:统一将所有数据放在冷数据区进行存储,为每一条数据设置一个全局ID,此ID即为该数据的唯一标识,其中前三个字节分别表示热索引、热数据、冷数据,其余字节为对应分区下具体数据的标识字段。
(2)Rowkey设计:数据预处理后的ID加入数据写入时的时间戳TimeStamp(时序数据需要),经过MD5和Salt哈希散列后生成一串由32位字符组成的字符串,这32位字符串即为最终的行键值。Rowkey设计如表1所示。

(3)数据冷热分类:根据数据库中对数据的访问次数选取一批冷数据和热数据作为数据集,基于逻辑回归算法进行模型的构建和训练,使模型可根据读入(输入)的数据特征,反馈(输出)这条数据是属于冷数据还是热数据,一次实现数据的冷热分类[5]。
(4)数据冷热分区:上文提到,在未进行数据分区时,所有数据都是存放在冷数据区的,因此当数据完成冷热分类后,需要将热数据在Rowkey所在数据分类后,根据分类结果(热数据为1,冷数据为0),修改上文所设计Rowkey中的前三位字节(分别表示热索引、热数据、冷数据),然后再分别写入不同节点的冷热数据区。
(5)数据写入:在数据写入过程中同时向多个Region分区中写入数据,提高数据的写入效率。
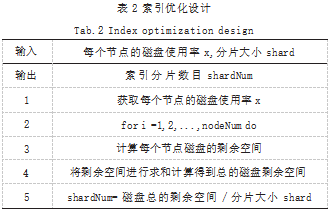
3.3索引优化
ElasticSearch的索引分片有主分片和副本分片两种,并且在集群中都是分散存储在不同的节点上。在进行数据的写入操作时,系统默认的是主副分片,同时执行数据的写入任务,但是这样会降低同一时间内数据的写入量,从而降低索引中数据的写入效率。因此,本文在设计优化上对磁盘空间中85%以内的剩余空间进行计算,然后设置每个分片的大小,通过将磁盘剩余空间除以每个分片的大小得到集群系统中索引分片数目的设置,从而对索引分片数量进行合理的分配,实现索引分片数目的动态设置,完成索引库的创建和数据的高效写入。索引优化设计如表2所示。
3.4数据压缩
前文“2.3数据压缩技术”提到数据压缩方法的底层实现算法有LZZZ算法,这个算法的基本实现核心就是前向缓冲区、滑动窗口和短语字典。通过前向缓冲区,一部分数据可以预先载入到缓冲区中;接着,数据将移动到滑动窗口,从而标记出能够与字典中短语匹配的最长短语,实现数据压缩。而最小二乘法则是一种基于数据估计的压缩算法,通过计算系统参数,使估计值与实际值的平方差最小,进而得到压缩数据的误差[6]。这些算法的运用不仅能够提高数据压缩的效率,也能够为数据传输和存储带来更多的便利性和节约性。
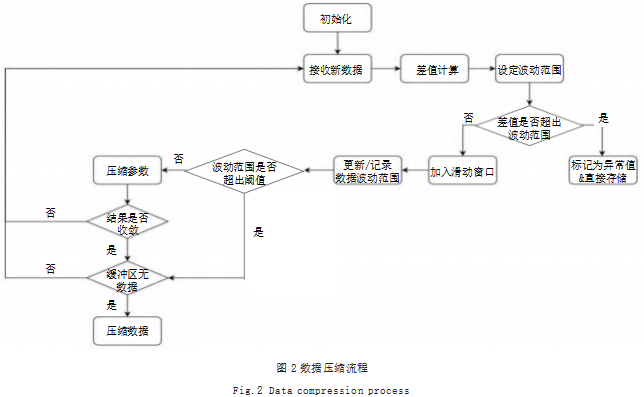
因此,本文设计采用以上原理实现对数据的压缩,如图2所示。
数据压缩流程如下:
(1)设定滑动窗口为M字节,缓冲区为N字节,初始化最小二乘法相关参数;
(2)接收新数据;
(3)计算T时刻与前后三个时刻数据的差值s1,s2,s3,s4,s5,s6;
(4)计算实际值与理论值的残差平均值,设定数据波动范围;
(5)若差值s1-s6均超出波动范围,则将其标记为异常数据直接存储,反之加入滑动窗口中;
(6)更新并记录数据波动范围;
(7)若数据波动范围超过设定阈值,转入步骤(11),反之继续;
(8)压缩参数;
(9)若压缩的参数未收敛,转到步骤(2),反之继续;
(10)若缓冲区仍有新数据则转到步骤(2),反之继续;
(11)压缩数据。
3.5异常存储检测
可采用基于最小二乘支持向量机算法的存储异常监测,是一种高效、精确的数据存储安全诊断方法,可以帮助企业实现全面性和准确性的提升,从而保障时序数据的完整性,为数据安全保驾护航[7]。异常存储检测如图3所示,检测方法如下:
(1)数据处理:对原始数据进行均值零处理和归一化处理(训练样本可由测量数据中加入随机白噪声构成);
(2)相空间重构:将一维时间序列转化成二维矩阵形式,获取更全面的数据信息和数据之间的潜在关联方式;
(3)模型构建:基于最小二乘支持向量机算法,建立时序数据预测模型,将预测误差控制到最小;
(4)模型预测:进一步预测获取的测量数据,获取预测值;
(5)获取误差值:把预测值与实际值进行对比,获取误差值;
(6)计算回归函数值:计算时序数据的线性回归函数;
(7)数据对比:时序数据的线性回归函数值与门限值进行对比,如果线性回归函数值大于门限值,则出现异常需要预警,检测结束;反之重复步骤(5)~步骤(7)。

4结语
信息化时代,数据存储与管理技术对推动物联网技术发展和场景落地都具有积极意义,如何解决物联网多源异构大数据在数据完整性、负载倾斜和数据压缩方面的问题是当务之急。针对以上问题,本文基于HBase-ElasticSearch设计了数据存储与管理方案,针对数据分类、数据冷热分区、Rowkey设计、索引优化、数据压缩和异常检测提出了建议,以便技术人员研究,充分发挥技术优势,提高数据信息的利用率,满足数据的高效存储和低延迟检索,使得数据能够应用到更多领域。
参考文献
[1]赵培植.物联网大数据存储与管理技术研究[J].中国新通信,2021,23(07):9-11.
[2]段莎莉.物联网大数据存储与管理技术研究[J].信息系统工程,2020(11):45-46.
[3]刘博伟,黄瑞章.基于HBase的金融时序数据存储系统[J].中国科技论文,2016,11(20):2387-2392.
[4]付乾.物联网大数据存储与管理技术[J].电子技术与软件工程,2020(23):155-156.
[5]杨力,陈建廷,向阳.基于HBase的工业时序大数据分布式存储性能优化策略[J].计算机应用,2023,43(03):759-766.
[6]王永臻.基于最小二乘法的船舶电力监控系统数据压缩策略[J].上海船舶运输科学研究所学报,2022,45(01):28-33+38.
[7]刘倍雄,张毅,陈孟祥.工业大数据时序数据存储安全预警研究[J].机械设计与制造工程,2019,48(05):62-66.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!

可解释性是一个非常重要的标准。机器学习模型... 详细>>

如何设计有效的环境治理政策, 是学术界和政策... 详细>>
