SCI论文(www.lunwensci.com)
摘 要 :针对数字化应用实践中需要在不同的物理域和信息域中进行数据的访问交换以及共享计算等需求,本文分析了在 数据平台、数据集成系统以及信息交换系统中存在的问题。在基于联邦学习的基础上,提出一种跨域数据计算共享系统,能够 同时共享数据和计算资源,并支持在线计算。在架构设计上设计了基础资源层、共享资源层及应用层,突出共享资源层中针对 共享数据资源及共享计算资源的设计逻辑。模块设计中重点解决跨域数据集搜索问题以及算力共享激励问题,首先通过容器虚 拟化屏蔽计算资源的异构性,设置下载控制量实现一定程度的隐私保护 ;然后使用基于数据连接的跨域数据集搜索,使得搜索 能够从数据集简介层面上深入到数据集表,提升跨域数据集搜索的准确度,为了扩充和平稳系统算力,分别设置了用户奖励与 惩罚策略, 通过资源异构性屏蔽、搜索策略改进以及激励策略的综合使用, 提升了跨域数据计算共享系统的易用性、稳定性 ; 最后通过本文方法与两种数据共享系统的方法进行了验证对比,证明本方法对跨域数据计算共享效率的提升。
Method of Cross-domain Data and Computing Resources Sharing System
TIAN Chengdong, JIANG Wei
(Information Science Academy,China Electronics Technology Corporation, Beijing 100041)
【Abstract】:For the needs of accessing and exchanging data and sharing computation in different physical and information domains in digital application practice, this paper analyzes the problems in data platforms, data integration systems and information exchange systems. Based on federal learning, a cross-domain data computing sharing system is proposed, which can share data and computing resources simultaneously and support online computing. The architecture is designed with a basic resource layer, a shared resource layer and an application layer, highlighting the design logic of the shared resource layer for shared data resources and shared computing resources. The system firstly shields the heterogeneity of computing resources through container virtualization and sets the download control amount to achieve a certain degree of privacy protection; Then uses the cross-domain dataset search based on data connection, which enables the search to go deep into the dataset table from the dataset profile level and improves the accuracy of cross-domain dataset search; In order to expand and smoothing the system arithmetic, user reward and penalty strategies are set up respectively. Through the combination of resource heterogeneity shielding, search strategy improvement and incentive strategy, the ease of use and stability of the cross-domain data computation sharing system are improved. Finally, a validation comparison between the method of this paper and two data sharing systems is conducted to demonstrate the improvement of the efficiency of this method for cross-domain data computation sharing.
【Key words】:federated learning;computing resources sharing;cross-domain data sharing;shared architecture; incentive mechanism
0 引言
伴随着数字化的发展,各类信息都以数字形式存储 在不同的业务系统中,形成了海量数据。由于各业务系 统的归属不同,在物理域与信息域上不同的数据源之间 交互及访问无论是效率上还是使用上都存在一定的壁 垒,逐步形成了数据孤岛,这种现象已经成为制约数据 应用发展的阻碍 [1]。
从技术上看,数据共享是解决各类不同业务系统中 数据交互使用的重要手段。数据共享可以分为共享数 据、共享信息和共享学习三种主要类型。共享数据是指 数据所有者将源数据共享给数据需求者,此时数据所有 者的控制权减弱,数据接收者可能会恶意散播数据、恶 意挖掘隐私信息 ;共享信息是指数据所有者将数据转换 为需求者可理解的形式,然后发送给数据需求者 ;共享 学习是指数据通过计算和提取知识后,发送给数据需求 者,这种方法能够在一定程度上保障数据所有者对数据 的控制权。
本文在分析现有数据共享平台的基础上,基于联邦 学习的思想,设计一种跨域数据计算共享系统,能够同 时共享数据及计算资源,并支持基于共享算力及数据的 在线计算。
1 相关背景
为了解决跨域数据共享问题,我国大力推进数据共 享。2021 年 3 月发布的《国民经济和社会发展第十四 个五年规划和 2035 年远景目标纲要》明确提出“加强 公共数据开放共享”[2]。目前,很多垂直领域都建立了 大数据平台用于数据共享,大数据平台通常都是某一个 垂直细分领域的数据共享系统,多数由此领域权威机构 运行。权威机构具有设备、资源优势,可以得到权威数 据,通过数据共享,可以带动本领域发展。数据平台上 的数据质量高,数据类型不多,大多为规则数据 [3]。
数据集成将企业多个部门,或者相同行业的多个企 业的数据有机集中,把多种来源、格式的数据进行逻辑上 共享。联邦式数据库和中间件是数据集成的主要技术 [4]。 数据集成中间件的主要功能是对异构数据进行转换与包 装, 提供统一高层访问服务,实现各种异构数据源的共 享 [5]。中国信息交换模型 CIEM(China Information Exchange Model)[6] 包括数据模型标准和信息交换服 务。数据模型标准解决国内政务信息交换中数据语义异 构问题,信息交换服务为部门提供数据共享的平台,实 现跨层级、跨地域、跨系统、跨部门、跨业务的数据调 度能力。
为了解决数据共享过程中的隐私泄露问题,谷歌在多方安全计算的基础上,提出联邦学习的概念。联邦学 习旨在保持数据本地化基础上,使用大量远程设备进行 模型训练。Li T 等人对联邦学习的概念、关键问题以 及未来方向进行了全面综述,指出联邦学习中的关键问 题,包括大量的通信消耗、系统异构性、统计异构性、 隐私保护以及激励机制 [7]。2019 年,蚂蚁金服提出了 相似概念—“共享智能”,并构建了共享机器学习系 统。共享机器学习系统面向金融行业,重点解决大数据 孤岛,通过实现多方数据所有者对数据的控制权 [8.9]。
综上,数据平台与数据集成主要针对某一个垂直领 域,信息交换系统主要针对不同机构和组织之间进行通 信的场景,二者均不涉及到数据的计算。联邦学习通过 共享数据计算结果,能够在一定程度上保护数据所有者 的隐私以及对数据的控制权,然而联邦学习的研究和开 发还在初级阶段,其中的关键问题还有待解决,据此, 基于联邦学习的思想,本文提出一种跨域数据计算共享 系统,并对系统中的数据管理、算力管理等关键模块进 行了设计。该方法的主要创新点有 :(1) 利用联邦学习 的思想,同时放松了联邦学习对于数据本地化的限制, 允许数据子集在计算过程中迁移到其他计算资源。(2) 重点解决了系统数据管理、算力管理中的解决跨域数据 集搜索、计算资源共享激励问题,提升跨域数据资源的 使用效率。(3) 通过使用容器虚拟化的方式屏蔽系统异 构型,通过设置下载控制量完成一定程度的隐私保护。
2 跨域数据计算共享系统架构
跨域数据计算共享系统具备共享数据及算力能力, 并支持在线计算。数据计算共享系统基于联邦学习的思 想,具有与联邦学习相似的特点,包括系统异构性、隐 私保护、通信消耗、统计异构性以及激励机制 [10]。此 外,由于涉及到跨域数据管理问题,所以跨域数据集查 找也是系统的关键问题 [11]。
数据计算共享系统通过使用容器虚拟化的方式屏蔽 系统异构性 ;通过设置下载控制量完成一定程度的隐私 保护 ;系统将通信消耗转由用户解决,用户在进行子任 务划分的时候应尽量减少通信消耗,并使得子任务的复 杂度均匀 ;统计异构性则通过将同一个计算任务的子任 务尽量安排在同构的计算资源上运行来解决。数据计算 共享系统与联邦学习系统最大的不同是,放松了“数据 本地化”限制,允许数据子集在计算过程中迁移到其他 计算资源上,并采用计算数据分块和匿名的方式解决该 问题。
2.1 系统架构
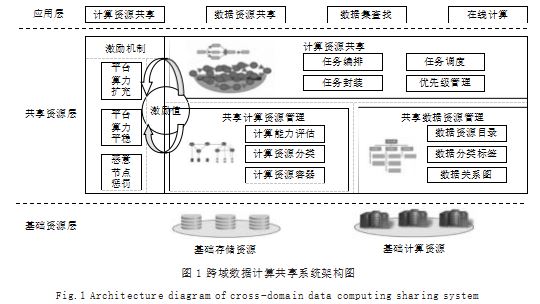
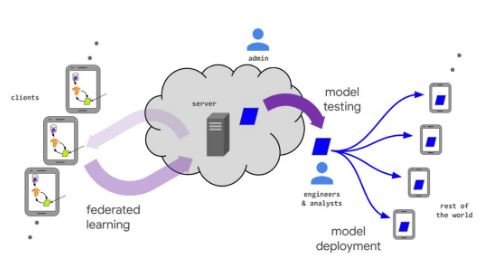
跨域数据计算共享系统架构如图 1 所示, 包括基础资源层、共享资源层以及应用层,其中共享资源层是核心。
基础资源层包括基础存储资源和基础计算资源。基 础存储资源用于用户共享数据的存储 ;基础计算资源用 于保障平台进行在线计算的最小能力,即在缺乏共享计 算资源的情况下,保障系统能够继续对高级别用户提供 在线计算服务的能力。
共享资源层管理用户共享的数据资源和计算资源, 同时管理计算任务以及激励机制。共享数据资源管理包 括建立数据资源目录、数据标签管理和数据关系管理 等 ;共享计算资源管理包括计算能力评估、计算资源分 类、计算资源容器等。计算任务管理包括任务编排、任 务封装、任务调度、任务优先级管理 ;激励机制包括平 台算力扩充激励、算力平稳激励以及恶意节点惩罚。
应用层包括数据资源共享、计算资源共享、数据集 查找以及在线计算。
2.2 数据资源共享
用户在平台共享 XML 格式数据,对于非 XML 格 式数据,系统提供工具包用于数据格式转换。用户在上 传数据前需要填写数据集简介,在上传数据后,平台使 用数据分类标签功能自动识别数据集的领域标签,并将 用户的 XML 数据转化为表形式,存储到基础存储资源 当中。用户核对数据集的领域标签,对转换有误的位置 进行修改,用户可以为发布数据设置共享范围,数据共 享活动图如图 2 所示。
2.3 计算资源共享
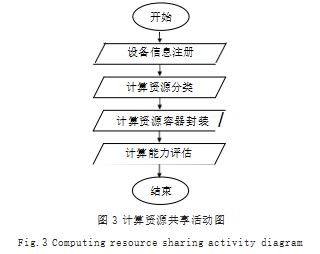
用户将计算设备注册在平台上,先填写计算设备基 本信息,平台会首先进行计算资源分类、计算资源容器 封装,然后进行计算能力评估,如图 3 所示。
计算资源分类根据计算设备的硬件配置对计算资源进行分类。计算资源容器封装根据分类结果形成对应计 算容器,通过多种计算容器对在线计算任务屏蔽底层硬 件设备的异构性。计算能力评估对计算设备进行评估,评 估方式为运行基本程序,包括计算能力评估以及网络带 宽能力评估,为在线计算过程中的任务分配提供信息。
2.4 数据集查询功能
用户在使用数据前,可以使用数据集查询功能查询 所需的数据集。平台共享数据可能来自多个领域,也可 能出现数据集描述与数据集结构不匹配的情况,然而对 所有领域的数据集描述进行规范化管理需要耗费大量的 人力。针对此问题,将传统的基于数据集描述文本匹配 的查找改为基于数据连接的搜索,通过语义构建领域层 与数据实体层连接图,再通过路径搜索的方式找到所需的数据集,提高数据集搜索的准确性,使得搜索能够从 数据集简介层面深入到数据集表。具体在 3.1 节进行展 开说明。
2.5 在线计算
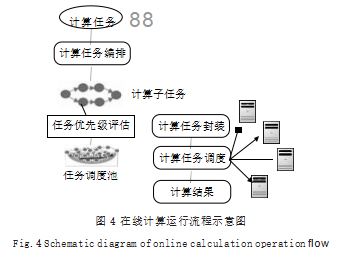
在线计算调用计算任务管理功能,并消耗用户的激 励值。用户在定位到所需数据所在的数据集后,可以进 行在线计算。用户首先使用任务编排功能将在线计算划 分,形成子任务,用户在进行子任务划分的时候应尽量 减少通信消耗,并使得子任务的复杂度均匀 ;优先级 管理根据任务发布者激励值累积情况为子任务设置优先 级 ;任务调度对任务调度池中的任务根据目前计算资源 储备、任务先序关系、任务优先级别对任务进行调度, 调度前进行任务封装(将任务放入到计算资源容器中), 然后将计算资源容器发布给共享计算资源,如图 4 所 示。每当一个计算完成时,平台将计算结果返回给用 户,用户可以实时看到计算运行过程,以及每个步骤的 计算结果。
2.6 数据下载量控制
为了保护数据发布者对数据的控制权,数据上传者 可以控制基于该数据集的下载量,如果下载量等于数据 集的大小,则数据下载者可以下载全部数据 ;大数据集 的下载量只允许用户以采样的方式查看原始数据。下载 量同样对基于该数据集的运算结果起作用,即用户运算 结果下载时,也要受到下载控制量的制约。当运算涉及 到多个数据集时,下载控制量的最小值起作用。通过控 制下载量可以保护数据所有者对数据的控制权,从侧面 实现隐私保护。
数据计算共享系统与联邦学习系统最大的不同是, 放松了“数据本地化”限制,允许数据子集在计算过程 中迁移到其他计算资源上。系统从两方面解决数据迁 移可能引起的隐私泄露问题 :一方面,使用数据分块方法,限制每个计算子任务使用数据量的大小,由于每个计算子任务只涉及到部分数据,因此迁移过程中不会造成源数据一次性泄露 ;另一方面,采用计算资源匿名方式,限制用户使用自身资源运行自身发布的计算任务, 当平台共享计算资源足够多时,用户无法通过共谋拼凑 得到源数据。
3 关键模块设计
本部分解决数据管理、算力管理中的两个关键问 题 :跨域数据集搜索问题以及算力共享激励问题。
3.1 基于数据连接的跨域数据集搜索
基于数据连接的跨域数据集搜索通过语义构建数据 连接图,再通过路径搜索找到所需的数据集,使得搜索 能够从数据集简介层面上深入到数据集表,提高数据集 搜索的准确性。
数据连接分为两层 :第一层是领域层,第二层是实 体层。领域层根据数据集描述文本信息自动给数据集匹 配领域标签,通过标签关联数据集 ;实体层根据数据集 中的表信息,将表格聚类,并将描述统一类别的表格划 分为一个类,为后续的查找和计算做准备。
3.1.1 领域层数据集标签自动生成
在平台建立初期, 用户需要选择领域标签。在平台 运行一段时间后,前期用户填写的数据集描述和设置的 标签即可成为标签匹配模型的训练数据集,用于模型训 练。数据集标签分类模型以 Bert-base 为基础,同时考 虑到 Bert-base 模型较大,在预测阶段运行耗时较多问 题,增加了一组用于逐步结果更新的分类器如图 5 所示。
模型具体训练过程如下 :
Step1 :用数据集的描述文本对 Bert-base 模型进 行预训练 ;
Step2 :用数据集中的描述文本和标签对 Bert-base 进行精调 ;
Step3 :使用 Bert-base 的嵌入层和 12 个 Attention 层输出作为特征,将领域标签作为目标,使用线性分类 器分别训练,得到 13 个分类器。
数据集标签分类模型预测过程如下 :
Step1 :用户在上传数据前提交关于数据集的描述 说明,系统将描述说明输入到 Bert-base 中。
Step2 :获取模型嵌入层输出以及 12 个 Attention 层输出,使用对应的分类器进行预测,并使用新产生的 结果覆盖旧结果,逐步更新分类结果,如图 6 所示。
用户在看到预测结果后,可以选择自动匹配的标签 作为数据集标签,也可以自行选择其他标签。用户的自 行选择结果,会归到数据集中,用于标签匹配模型的进 一步训练。
3.1.2 实体层数据连接
数据实体连接采用基于同义词的方法。将同一类,但 是描述不同的表格连接在一起,例如“图书分类”和“书 籍类别”实际上是同一类实体。数据实体连接过程如下 :
Step1 :关系图构建,将词库中的词抽象为节点, 同义词以及上下位词关系抽象为边,形成词关系图。
Step2 :数据集实体连接,将数据集中表名分词, 如果分词结果包含关系图中的某个节点, 则在节点和表 之间建立连接。
3.1.3 数据集搜索
用户可以提交查询请求的自然语句,平台将查询语 句分词,然后分别进行领域层、实体层查询,通过连接 路径定位数据集,具体过程如下 :
Step1: 领域层查找。如果分词结果能够匹配到领域 标签,则记录标签 ;否则,使用数据集标签分类模型的 分类器 0(如图 5 所示),得到领域标签集合。
Step2: 实体层查找。分词结果匹配词关系图中的节点,得到实体层节点集合。如果没有找到对应节点,则 返回领域标签集合对应的数据集结束 ;否则继续。
Step3: 路径查找。寻找连接领域标签集合和实体层 节点集合的路径集合,要求每条路径只经过一个数据集。
Step4: 返回所有路径的数据集作为结果。
3.2 计算资源共享激励
计算资源共享激励的目标包括扩充算力、平稳算力、 惩罚恶意破坏、惩罚时延。其中扩充算力希望吸引更多的 用户共享计算资源 ;平稳算力希望已经共享计算资源的用 户尽量保持共享状态 ;惩罚恶意破坏防止恶意用户通过非 法手段套取激励值或者破坏平台功能 ;惩罚时延希望用户 能够共享更多的稳定计算资源。具体激励规则如下 :
(1)扩充算力 :用户每执行一次任务, 平台会给用 户增加激励值,激励值与任务的复杂度成正比。
(2)平稳算力 :平台周期性计算用户共享计算设备 的任务量,当用户的计算任务量降低时,平台会减少用 户的激励值,降低量与减少量成正比。
(3)惩罚恶意破坏 :平台通过随机测试的方式发现 恶意破坏用户。用户可能会在领取任务后,返回一些随 机值,从平台哄骗激励值,为了防止此类用户行为,平 台会自动生成一些已知结果的测试任务。测试任务与普 通任务混合在一起,使得用户无法发觉,当用户返回 的计算结果与已知结果不一致时,则判定用户为恶意用 户。当用户两次被判定为恶意用户时,平台会将用户拉 入黑名单,禁止用户在平台的任何行为。
(4)惩罚时延 :用户的计算设备可能本身处于一个 不稳定状态,例如,网络带宽不稳定、同时运行其他任 务导致共享的计算能力不稳定等,影响平台整体计算任 务的运行 ;当用户返回相同复杂度任务的时延波动较大时,系统会降低奖励系数,使得提供稳定计算服务的用 户得到更多的奖励,从而吸引更多用户将计算能力稳定 的资源共享到平台。
4 数据验证及分析
本文实验数据集使用 Project Gutenberg 模型数据 集和 PhilPapers 数据集作为两个跨域数据集,部署在 不同的域服务器上。Project Gutenberg 是一个图书信 息的数据集,该数据集包含超过 57.000 种免费电子书, 包含图书下载或在线阅读信息 ;PhilPapers 数据集包 括来自加拿大西安大略大学的开放哲学出版物。
在实验对比中使用 Exchangis 和 Atlas 与本文方法 进行比较。Exchangis 是腾讯软件开发开源的数据交换 平台,用于数据在不同计算存储中快速传递。Atlas 是 Apache 基金会开发的元数据管理和数据治理平台,是 一个可伸缩且功能丰富、开源的数据管理系统。
测试采用将两个数据集分别部署在位于北京移动和 上海联通等不同区域的 10 台服务器上,测试地点位于 北京,服务器分别安装 Exchangis、Atlas 和本文的共 享系统。数据共享效能采用关键信息跨域数据集搜索 的方式进行对比验证, 分别取 Project Gutenberg 和 PhilPapers 的各 500 个图书资源进行共享操作,记录 资源生成时间、任务调度时间和搜索用时。验证结果如 表 1 所示。
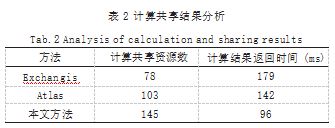
计算共享效能采用用户共享资源池的共享资源数及 计算结果返回给用户后的时间花费等指标进行验证,将 10 台服务器虚拟出 100 个用户,每个用户可用的系统 资源相同,其共享资源数设定为 50.用户可动态调整 可共享的计算资源数,放到计算共享资源池中。验证结 果如表 2 所示。
通过以上实验数据的对比,可以看出本文方法在数 据跨域搜索和计算共享方面用较低成本实现快速找到合 适的共享资源来进行分配,减少了任务调度的时间,提 高了数据资源共享效率。
在联邦学习思想的基础上,本文提出了一种数据计 算共享系统,系统包括基础资源层、共享资源层以及应 用层,其中共享资源层是核心。共享数据计算系统是联 邦学习的简化版本,放松了联邦学习对于数据本地化的 限制,通过使用容器虚拟化的方式屏蔽系统异构型,通 过设置下载控制量完成一定程度的隐私保护。于此同 时,面向多域共享中的数据管理、计算资源管理,分别 解决跨域数据集搜索、算力共享激励问题,提升了跨域 数据资源的使用效率。
参考文献
[1] 温秀秀.一种数据集搜索方法、装置、存储介质及终端:中 国,CN202111056911.2[P].2021-12-10.
[2] 中华人民共和国国务院.国务院关于印发促进大数据发展行 动纲要的通知[J].中华人民共和国国务院公报,2015(26):26-35. [3] 黄彬城,陈思,高放,等.星际争霸视角的未来作战自主决策技 术[J].科技导报,2021.39(5):117-125.
[4] 陈跃国,王京春.数据集成综述[J].计算机科学,2004.37(5): 48-51.
[5] 刘基阳.面向多源异构数据的数据集成中间件的设计与开发 [D].成都:电子科技大学,2018.
[6] 崔子腾,戴永恒,吴韧韬,等.信息交换方法、装置及计算机存 储介质:中国,CN201911066400.1[P].2021-05-11.
[7] LI T,SAHU A K,TALWALKAR A,et al.Federated Learning:Challenges,Methods,and Future Directions[J]. IEEE Signal Processing Magazine,2020.37(3):50-60
[8] 胡小宇.蚂蚁金服互联网金融生态圈构建方式案例分析[D]. 保定:河北金融学院,2019.
[9] 王亚珅.面向数据共享交换的联邦学习技术发展综述[J].无 人系统技术,2019.2(6):58-62.
[10] 陈嘉熳.基于区块链的跨域数据共享技术研究[D].成都:电 子科技大学,2021.
[11]马英.一种基于隐私计算的数据共享模型研究[J].信息安全 研究,2022.8(2):122-128.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/68772.html