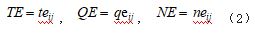SCI论文(www.lunwensci.com)
摘 要 :为深入研究某大型港口岸桥设备作业量与电耗量之间的关系,有效预测未来一段时间内岸桥的作业量、电耗量数 据,基于某大型港口大数据平台技术架构,打通岸桥设备作业数据、电耗数据之间的数据壁垒,建立作业、电耗数据加工整合 模型,确定岸桥设备作业量与电耗量对应关系,同时,基于 Arima 时序模型,对未来 7 日内岸桥的作业量、电耗量数据做 出预测。结果表明,作业量、电耗量对应关系与人工上报数据误差小于 1%,在数据平稳的前提下,预测数据与真实数据误差 小于 8%。
Power Consumption Datas Analysis Based on Big Data Technology for Large Port Bridge Cranes
NIE Chao1. XU Weijuan2. HAO Weijian1. CHANG Jian1
(1.Qingdao Port International Co., Ltd., Qingdao Shandong 266599;
2.Qingdao Pilot Station, Qingdao Shandong 266599)
【Abstract】:In order to conduct in-depth research on the relationship between the operating volume and power consumption of a large port's shore bridge equipment, effectively predict the operation volume and power consumption data of the shore bridge in the future, based on the technical architecture of a large port big data platform, break through the data barriers between the operation data and power consumption data of shore bridge equipment, establish an integrated model for processing homework and electricity consumption data, determine the corresponding relationship between the operating volume of shore bridge equipment and electricity consumption, at the same time, based on the Arima time series model, predict the operation volume and power consumption data of the shore bridge in the next 7 days. The results indicate that, the error between the corresponding relationship between workload and electricity consumption and the manually reported data is less than 1%, on the premise of stable data, the error between predicted data and actual data is less than 8%.
【Key words】:shore bridge;data barriers;relationship;Arima time series model;forecasted
0 引言
以往,某大型港口对岸桥设备电耗一直没有细化研 究,岸桥设备电耗与作业量数据也一直存在数据壁垒, 难以对二者之间的关系进行量化 ;同时,作业量、电耗 量虽然沉淀了大量数据,但缺少基于现有数据对未来数 据的预测。以上问题对于业务层和决策层也是难点,对 电耗信息的获取、决策的制定都产生了阻碍。通过某大 型港口大数据平台技术架构,对岸桥设备作业量、电耗 量数据进行整合、加工,建立数据模型,对岸桥作业量、电耗量、单位作业量对应电耗量进行量化,打通二 者间的数据壁垒,同时,应用 Arima 时序模型,基于 已有数据,对未来 7 日的岸桥作业量、电耗量数据做出 预测,为业务层、决策层对岸桥电耗信息的管控、决策 的制定,都起到重要的推动作用。
1 某大型港口大数据平台技术架构
某大型港口大数据平台经过数次版本迭代,已经形 成了一套运行稳定、高效的技术架构 [1]。底层大数据平 台采用 HDFS 分布式系统 [2], 数据存储包含 Hive 数据仓库、Hbase 列式数据存储,离线处理包含 MapReduce 计 算模型和 Spark 计算引擎,实时计算则采用 Presto 和 Flink 计算引擎。中间数据中台层承担数据采集、数据 打通、数据计算、数据存储、数据建模、数据治理等功 能,基于存储数据构建了多个分析模型和标签模型,搭 建了标签平台、自助分析平台和统一数据服务。前端数 据应用层则是基于 FineReport、FineBI 工具,开发多 个数据可视化驾驶舱和数据多业务维度自主分析功能, 为业务层和决策层提供数据应用。某大型港口大数据架 构图如图 1 所示。
2 岸桥设备数据加工模型
某大型港口岸桥设备主要分布在 3 家前湾码头公 司,分别配有 41 台、34 台、16 台岸桥设备,主要从事 集装箱装卸业务。岸桥数据加工模型是基于已经打通各 项数据间的壁垒基础上,分析岸桥单位作业量(TEU) 产生的耗电量。
2.1 各公司数据壁垒打通
以往,岸桥设备作业量数据分别采集和存储在各码 头公司的生产数据库中,岸桥设备电耗量数据分别采集 和存储在供电公司数据库中,各公司作业量数据之间、 作业量与电耗量数据间均存在壁垒,导致难以对某大型 港口全部岸桥设备数据进行统一分析和横向对比。通过 集团大数据平台,将各码头公司岸桥作业量、电耗量数 据统一采集到集团数据集市,打通各公司数据间的数据 壁垒,形成全部岸桥数据的有效分析,数据壁垒打通如 图 2 所示。
2.2 作业量数据加工模型
某大型港口对岸桥作业量数据的分析通常以月度为 单位。3 家码头公司某月岸桥总作业量以 T、Q、N 表示, 各公司第 i 天、第j 台岸桥作业量(TEU) 以 tij、qij、nij 表示,则 3 家码头公司某月岸桥总作业量分别表示为如 式(1)所示 :
其中 i 为某月天数, j 为公司岸桥台数。
2.3 电耗量数据加工模型
某大型港口对岸桥电耗量数据的分析通常以月度为 单位。3 家码头公司某月岸桥总电耗量以 TE、QE、NE 表示,各公司第 i 天、 第j 台岸桥电耗量以 teij、qeij、 neij 表示,则 3 家码头公司某月岸桥总电耗量分别表示为如式(2)所示 :
其中 i 为某月天数, j 为公司岸桥台数。
2.4 作业量、电耗量数据整合模型
2.5 误差分析
以2.4构建的全港岸桥设备月度的单耗模型为例,对比 2023 年 3 月 1 日至 3 月 15 日模型产生数据与各 公司人工报送数据,其数据和误差如表 2 所示。
结果表明,模型产生的单耗数据与人工上报的单耗 数据误差均保持在 1% 以下,故认为构建模型可用。
3 Arima模型数据预测
Arima 模型是最常用的时间序列模型之一, 主要用 于平稳非白噪声序列数据的预测 [3.4]。以 2023 年 1 月 1 日至 2023 年 4 月 12 日某大型港口全部岸桥每日总作 业量、总电耗量数据为例,预测 2023 年 4 月 13 日至 2023 年 4 月 19 日每日岸桥数据。
3.1 作业量数据预测
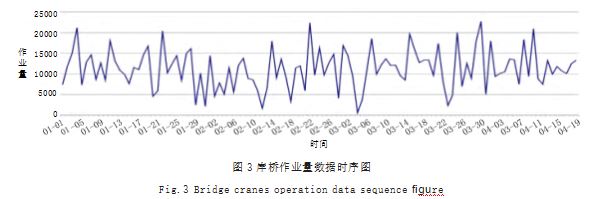
(1)绘制时序图。首先对岸桥每日作业量数据绘制时序图,初步观察作业量数据的分布情况。2023 年 1 月 1 日至 4 月 11 日作业量数据如图 3 所示。
(2)数据集 ADF 检验。对数据集做 ADF 检验,确 定数据集是否平稳,检验结果如图 4 所示。
结果表明, ADF 检验值 -10.96 明显小于 ADF 不同 程度拒绝原假设的统计值 1% 对应的 -3.49、5% 对应 的 -2.89、10% 对应的 -2.58.因此,可以认为数据集是 平稳的。
(3)数据集白噪声检验。若数据集是白噪声序列, 则序列是完全随机的,已统计的岸桥作业量数据对未来 数据不会产生任何影响,即不存在分析的必要性 ;反之, 则可以进行深入分析。白噪声检验结果如图 5 所示。
结果表明,延迟为 6 阶和 12 阶时, LB 和 BP 的统 计值均小于显著水平 0.05.因此,可以拒绝序列为白噪 声的原假设,确定序列为非白噪声,即可以进行下一步 的分析。
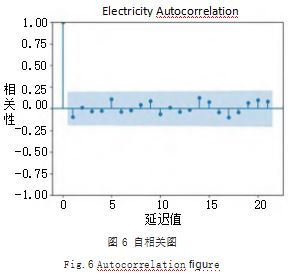
(4) 绘制自相关(ACF) 和偏自相关(PACF) 图。 根据岸桥作业量数据绘制 ACF 图,如图 6 所示。
根据岸桥作业量数据绘制 PACF 图,如图 7 所示。
(5)选择合适的模型拟合数据。根据 ACF 和 PACF图的变化趋势选择合适的拟合模型,模型选择的依据如 表 3 所示。
即 :1)自相关图为拖尾,偏自相关图为截尾,则选 用 AR 模型 ;2)自相关图为截尾,偏自相关图为拖尾, 则选用 PACF 模型 ;3)自相关图和偏自相关图均为拖尾, 则选择 ARMA 模型。
根据(4)中绘制的 ACF 和 PACF 图可以看出, ACF 和 PACF 图均为 1 阶拖尾,需选择 ARMA 模型,且p=1. q=1.数据集未做差分处理,因此 d=0.可得预测模型 为 ARIMA(1.0.1)。
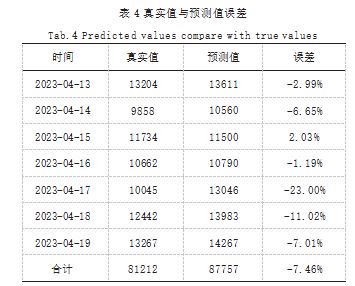
(6)预测未来 7 日的作业量数据。Arima 模型适用于 未来短期时间内的预测,因此,在使用时只对未来 7 日的 数据做出预测,真实值、预测值、误差数据如表 4 所示。
结果表明,除 4 月 17 日产生误差相对较大外,其 他单日数据以及合计数据都与真实数据较为接近,故可 以认为有效预测了未来 7 日岸桥作业量数据。
3.2 电耗量数据预测
(1)绘制时序图。首先对岸桥每日电耗量数据绘制 时序图,初步观察电耗量数据的分布情况。电耗数据分 布情况如图 8 所示。
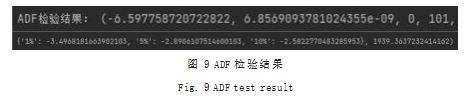
(2)数据集 ADF 检验。对数据集做 ADF 检验,确 定数据集是否平稳,检验结果如图 9 所示。
结果表明, ADF 检验值 -6.59 明显小于 ADF 不同 程度拒绝原假设的统计值 1% 对应的 -3.49、5% 对应 的 -2.89、10% 对应的 -2.58.因此,可以认为数据集是 平稳的。
(3)数据集白噪声检验。若数据集是白噪声序列, 则序列是完全随机的,已统计的岸桥电耗量数据对未来 数据不会产生任何影响,即不存在分析的必要性 ;反之,
结果表明,延迟为 6 阶和 12 阶时, LB 和 BP 的统 计值均小于显著水平 0.05.因此,可以拒绝序列为白噪 声的原假设,确定序列为非白噪声,即可以进行下一步 的分析。
(4) 绘制自相关(ACF) 和偏自相关(PACF) 图。 根据岸桥电耗量数据绘制 ACF 图如图 11 所示。
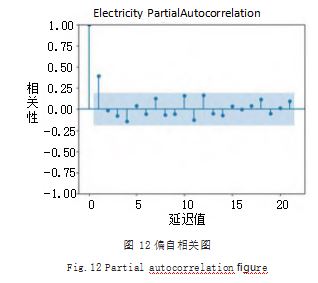
根据岸桥电耗量数据绘制 PACF 图,如图 12 所示。
(5)选择合适的模型拟合数据。按照 3.1 中的规则 选择合适的模型拟合数据。根据(4)中绘制的 ACF 和 PACF 图可以看出, ACF 和 PACF 图均为 2 阶拖尾, 需选择 ARMA 模型,且p=2. q=2.数据集未做差分处理, 因此 d=0.可得预测模型为 ARIMA(2.0.2)。
(6)预测未来 7 日的电耗量数据。Arima 模型适用 于未来短期时间内的预测,因此,在使用时只对未来 7 日的数据做出预测,真实值、预测值、误差数据如表 5 所示。
结果表明,除 4 月 17 日产生误差相对较大外,其 他单日数据以及合计数据都与真实数据较为接近,故可 以认为有效预测了未来 7 日岸桥电耗量数据。
3.3 误差分析
根据 2.4 作业量、电耗量数据整合模型计算未来 7 日内岸桥的单耗数据。则未来 7 日某大型港口每日全部结果表明,由于 4 月 17 日的作业量和电耗量数据 均存在较大误差,导致单耗的计算结果存在较大出入。 除 4 月 17 日外, 其余单日岸桥单耗值与真实值误差均 在合理范围内,合计值的误差也控制在了 10% 以内, 故可以认为计算结果具备较高参考价值。
4.结语
基于某大型港口大数据平台技术架构,打通了各公 司岸桥作业量数据之间、作业量数据与电耗量数据之间 的数据壁垒,构建了作业量、电耗量数据整合模型,对 岸桥作业单耗形成了有效分析。同时,基于 Arima 算 法,在验证可行性基础上,对未来 7 日数据做出预测, 预测结果具备较高的参考价值。需注意, Arima 算法适 用于预测未来较短时间内的数据,超过一定时间范围, 预测结果会产生很大误差。
参考文献
[1] 聂超,王一平,常建,等.基于大数据技术的青岛港集装箱中转 业务全流程分析系统[J].集装箱化,2023.34(3):15-19.
[2] 杨治学,王静静.基于Hadoop大数据集群的搭建[J].信息与 电脑(理论版),2022.34(20):130-133.
[3] 钱嫣然,何慧之,仇海英,等.基于ARIMA模型的区域用电量 预测方法[J].信息技术,2023.47(1):180-185.
[4] 周彬彬,黄嘉昕,耿冉冉,等.基于灰色-ARIMA耦合模型的中 国发电量短期预测[J].科技和产业,2022.22(12):382-387.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/67769.html