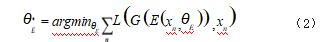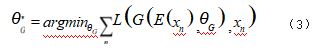SCI论文(www.lunwensci.com)
摘 要 :StyleGAN 提供了有意义的潜空间,将真实图像反演(Inversion)到潜空间,再通过对潜空间的探索实现操纵真 实图像,引起了众多研究者的关注,文章从基于反演方式和反演步骤两个角度分析总结了近年来图像反演算法的研究情况,并 分析反演到不同潜空间的意义。
A Review of Image InversionAlgorithms Based on StyleGAN
LI Yifan, YANG Ping
(School of Media and Design, Hangzhou Dianzi University, Hangzhou Zhejiang 310000)
【Abstract】: StyleGAN provides meaningful latent space, inversion of real image to latent space and exploring latent space to manipulate real images has attracted the attention of many researchers, this paper analyzes and summarizes the research situation of image inversion algorithms in recent years from the perspectives of inversion method and inversion steps, and analyzes the significance of inversionto different latent spaces.
【Key words】:image inversion;latent space;StyleGAN
0 引言
GAN、VAE 等生成模型被提出,通过生成模型,低 维数据得以转换到高维图像数据域,越来越多的 GAN 模型, 例如 StyleGAN[1] 由于其可以生成高质量和多样 性图像的能力,被更加广泛地应用于计算机视觉领域。 GAN 模型学习到的数据的潜在分布(潜空间),具有丰 富的语义信息,操纵这些语义信息可以修改图像的属 性,例如,操纵从人脸图像学习到的语义分布,可以改 变人脸的属性。然而,上述操纵潜空间来修改图像属性 的操作只适用于 GAN 生成的图像。为了能够用此方法 操纵真实图像,图像反演提出,将真实图像反演到(也 可以称为嵌入) GANs 的潜空间中得到真实图像的潜码, 通过 GANs 的生成器, 潜码可以最大程度地重建原图像, 即得到的潜码尽量含有原图的语义信息。将真实图像逆 映射到 GANs 的潜空间后,就可以通过操作潜码的方式, 修改真实图像的属性。
本文将目前的反演方法划分为基于反演方式和基于 反演步骤,从这两个角度来阐述和总结目前基于 GAN的潜空间反演方法以及分析图像反演算法存在的不足, 和未来面对的挑战。
1 图像反演的主要方法
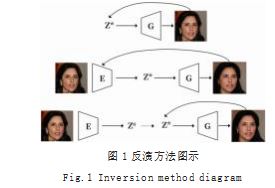
图像反演的方法,可以分为三类 :(1)基于潜码优 化的方法 ;(2)基于训练逆推编码器的方法 ;(3)基于 潜码优化和训练编码器结合的方法。反演方法图示如 图 1 所示。
1.1 基于潜码优化
这类方法,对于输入图像,首先从正态分布中任意采样一个潜码 z,将潜码 z 输入 GANs 的生成器中,得 到图像 G(z)(G 为预训练的生成器), 最小化输入图像 X 和 G(z) 在图像特征空间的距离, 一般为 lpips 感知损 失和像素级别的 L1. L2 损失。基于潜码优化如式(1) 所示 :
z*=argmin L(G(z),x) (1)
此类方法通过反向传播,不断优化得到式(1)的 最优解,定义 z* 即为输入的真实图像在潜空间对应的 潜向量。如图 1 第一行所示,对于迭代优化的方法来 说,选择优化器是至关重要的,因为一个好的优化器有 助于缓解局部最小值问题。主要的优化器有 :基于梯度 的 ADAM 和无梯度的协方差自适应矩阵 CMA,无梯度 优化的方式更加耗费时间。Image2StyleGAN[2] 应用了 ADAM 优化器,并且分析了当初始潜码为任意采样和 平均潜码的不同,并证实了对于不同的数据集,不同的 初始潜码影响最终的反演效果,对于人脸数据集初始潜 码为平均潜码 , 最终得到低得多的损失值。但是,对于 其他类别的图像(例如狗),随机初始化被证明是更好 的选择。对于潜码化的方法来说,缺点是对于每一张输 入图像都需要一个花费时间和内存的迭代过程。
1.2 基于训练逆推编码器
由于基于优化的反演方法在推理过程中,要花费大 量的计算时间,因此基于编码器的方法被提出,在大量 的数据上,训练一个编码器,根据式(2),编码器提取 图像特征,将特征图映射到低维潜空间,生成器将潜码 重新映射回图像空间,得到重建的图像,通过与优化方 法一样的损失,反向传播,不断的优化编码器的参数。 如图 1 第二行所示。最后训练好的编码器可以为输入 图像快速地得到一个潜空间的潜码,用于下游的操纵任务。基于训练逆推编码器如式(2)所示 :
实验证明,虽然相比优化潜码的方法,其有较快的推理速度,但是由于基于编码器的方法是从大量的训练 图像中学习到的信息,但是它一般重建的是训练图像的 平均状态,因此它对于图像的差异化信息(边缘信息) 的重建效果不佳,基于训练编码器得图像反演方法,它 推理结果的重建效果一般较差。基于编码器的方法是近 来研究最多的方法,放在第三章重述。
1.3 基于潜码优化和训练编码器结合的方式
基于结合的方式是,首先通过训练一个单独的编码 器来预测一个给定的潜码,使用得到的 z 作为初始化进 行优化。如图 1 第三行所示。这种方法是解决优化编码 器产生的潜码总是趋于分布的平均状态的一种方式,使得优化后的潜码学习到分布边缘的信息,能够更加还原 输入图像。有的研究者把对生成器参数的优化归为此 类,本篇认为是不准确的,因为对生成器参数优化去拟 合数据的分布过程,潜码没有变化。
2 潜空间性质分析
Z 空间 :Z 空间中的潜码是从正态分布中采样 得到的, Z 空间适用于所有 的无条件 GAN 模型,如 StyleGAN。
W 空间 :W 空间是指从 Z 空间采样的向量经过 StyleGAN 预训练的 8 层全连接网络,映射到的空间, 描述为 w ∈ W, z ∈ Z, w=M(z), W 空间相较于 Z 空间 学习了分布的解纠缠性质,更利于单一属性编辑。
W + 空间 :w * ∈ W +, w * 指从 W 空间采样不同的 18 个 w 潜码组成的 18×512 大小的潜在向量(输入图 片大小为 1024)。它比 512 维的 w 潜码有更丰富的信 息,因此能更好地重建原图。然而这个重建效果是以降 低可编辑性为牺牲的,也就是第三节提到的高保真度和 可编辑性的权衡。
F 空间 :Kyoungkook Kang 等人 [3] 首先提出的 F/ W +,这个空间由作为 StyleGAN 生成器某一层(假设 为 m 层)经过自适应归一化之前特征图的 Latent Map fm 和 {Wm, ...Wn} 组成。描述为, w*=(fm, w+)。由于 w* 是高分辨率的潜在向量,其中的fm 包含图像空间信息, 所以可以更好地重建原图,但是没有低分辨率的潜向量 易于编辑。如表 1 所示为潜空间维度总结。
此表默认输入图像是 1024 大小,以及 F 空间特征 图与生成器第八层特征图大小一致。
3 高质量反演的两个步骤
3.1 基于编码器的图像嵌入
此部分编码器的设计以及潜空间的选择是基于高保 真度、感知性和可编辑性这三个特征。在高保真度和可 编辑性中间有一个权衡,即反演得到的潜在编码如果拥 好的重建效果,那么它就会失去较好的可编辑性能。
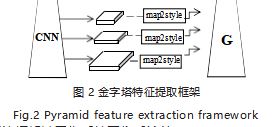
Richardson 等人 [4] 提出一个三层的金字塔特征提 取框架,如图 2 所示,其包含一个 Map2Style 下采样 模块,此模块将提取到的不同大小的特征图,从上到下 直接映射到 W + 空间,此方法更关注的是人脸图像的重 建效果,因此它的损失函数除了感知损失和第二范式, 还引入了 Arcface 人脸识别损失。此方法从粗到细提取特征的框架被用作后续图像反演的 Backbone。
Tov 等人 [5] ,为了在重建和编辑权衡中找到一个合 适的点, 它不同于直接编码潜向量至 W + 空间, 而是从 金字塔特征提取到的最后一层特征编码到 W 空间的潜 在向量 w, 并且从 w 生成一组偏移, 这些偏移初始都是 0. 即潜向量全部来自 W 空间, 之后鼓励编码器生成的 偏移改变,并且约束每一个偏移都不同,使得潜向量学 习到更多信息,保证了潜向量的重建效果。其还对偏移 采用第二范式约束,使其不特别远离 W 空间,保持可 编辑性。此方法确实拥有比较理想的编辑感知效果,被 广泛用于下游的编辑工作中。
当反演得到的潜码离 W 空间越近, 那么其具有越 好的编辑功能,但是是以牺牲重建效果为代价的,因为 当潜码的维度越小,那么包含的信息就越少(Low-rate 和 High-rate 的 权 衡), 因 此 Xu Yao[6] 提出将潜码映 射到 F/W 空间, F 是编码器提取的高维特征张量,其 相较于 1×512 维的 w 潜码能够捕获空间信息,将 F 作 为生成器第 5 层的特征图,向生成器中注入高维特征的 空间结构信息,生成图像具有更高保真度,来自 W 空 间的剩余潜码保证了后续调整特征图的细节。但是由 于其潜空间性质的变化,传统得到编辑图的编辑方法 Iedit=G(w+ ∆ w)( ∆ w 为 W,W + 潜空间属性编辑方向 ), 不能在作用于此空间,为了保证可编辑,其提出了 F 空间 特有的编辑方式 Iedit=G(w+ ∆ w,fm+Gm (w+ ∆ w)-Gm (w))。
Hongyu Liu 等人 [7] ,同 Tov 等人一样也是在重建 和编辑之间找到一个平衡点,在金字塔特征提取结构上 改进,不同于上述工作直接将图像嵌入到 W + 或者 F 空 间,而是参考 Tov 从金字塔层级结构学习一个来自 W 空间的潜码,并且引入对比学习对齐 W 空间和真实图 像空间,再通过交叉注意力从 W 空间转换到 W + , F 空 间, 从 W 空间转换得到的 W + , F 空间的潜在向量和 W 空间紧密相关,拥有其可编辑的特性和高维空间本身高 保真度的特性。
总结 :上述方法,都是分析潜空间的性质,找到一 个平衡编辑和重建的潜向量,虽然 F 空间实现了部分域 外信息域内化,然而由于上述依旧是针对生成器域内的 信息进行编码,并且生成下游的风格自动适应归一化模块,只是对于特征图整体的调整,所以变化后的下游潜 码会改变高维 Latent Map 带来的域外信息。于是在此 基础上,研究者们着重关注在域外信息上,提出反演优 化,使此部分编码器固定。
3.2 反演优化
鉴于上一步遇到的困境,潜在代码只能重建粗信 息,并从原始图像中删除细节,即它们不能忠实地反演 那些不来自训练数据分布的图像(域外信息)。在此基 础上,反演优化的方法被提出, 一般情况下,图像嵌入 得到的潜向量不会再发生变化(保持可编辑性)。
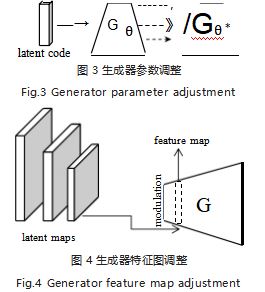
因此,最近的许多工作集中于通过调制额外的高分 辨率信息来细化结果,这些方法主要分为权重调制和特 征调制。权重调制一般是指对生成器网络的参数调整, 如图 3 所示,特征调制是对生成器中间层的特征图加入高分辨率信息,如图 4 所示。
3.2.1 生成器参数调整
例如, PTI[8] ,提出微调生成器的卷积层权重,使 得潜在向量不变的情况下,依旧采用感知损失和 MSE 损失,更新迭代生成器的权重,如式(3)所示,使得 生成器去拟合训练数据集的分布,因此生成器输出的图 像更接近输入图像,此外其还在潜空间中任意采样与编 码器得到的潜码插值得到,将其也送入生成器,对潜 码局部正则化,保证潜码的编辑质量。生成器调优可 以获得较好的反演性能,缺点是优化花费较长的时间。 HyperStyle[9] 也是通过调整 StyleGAN 生成器参数的方 法,不同于 PTI,其通过超网络,为生成器每一卷积层 权重学习了参数偏移,超网络的每层模块参数共享,相 比于直接调整生成器每一层网络的参数,减少了参数 量,节省了内存和时间。
3.2.2 生成器特征图调制
HFGI 等人 [10],将上一步编码器得到的潜码重建原 图丢失的部分称为残差图,其选用 e4e 编码器, 保证 可编辑性。为残差图设计一个自适应失真对齐模块(此 模块也适用于编辑图像产生的残差图)。将残差图,通 过预训练的 encder-decoder 结构 的对齐模块, 将残 差信息与输出图像对齐, 后特征提取为 64×64 大小的 latent map fi, fi 分解为结构特征图 gi 和高频特征图 hi, 通过门控融合的方法自适应的调整生成器中的特征图, 表达式如式(4)所示, Fi' 为经过自适应归一化后的特 征图。此方法恢复低频率潜码损失的信息,实现更高的 保真度,但是实验结果得到的图像,尤其是潜码改变后 的编辑图像,由于残差图背景不会随着潜码的变化而改 变,因此会出现伪影。
Pu Cao 等人 [11] 提出对生成器参数调制和特征调 制结合的方法。采用区域感知分割的方法将图像中域外 信息用遮罩提取出来,具体使用超像素算法,将输入图 像划分为多个区域,感知损失大的区域,即为无法反演 重建出来的域外信息。训练的网络提取特征得到 latent mapf,后与生成器第 l 层的特征图fl 通过下采样的掩 码融合,作为此层的新特征图,后送入自适应归一化模 块,表达式如式(5)所示。除此之外,其对于域内信 息(人脸部分)通过微调生成器参数,使其更接近输入 图像真实人脸。该方法能实现重建原图和保持高质量编 辑的 SOTA 的效果,缺点是步骤繁琐。
f *=m fl+(1-m)f (5)
目前基于 StyleGAN 的图像反演方法主要分为 :(1) 基于潜码优化 ;(2)基于训练逆推编码器 ;(3)基于混 合的方法。由于潜码优化耗时,主要采用基于编码器方 法,但是编码器不能很好地重建原图,于是研究者考虑 潜空间性质,将图像嵌入扩展到高维空间(W +、F 等 空间),并且更多的研究者从反演的下游编辑任务出发, 考虑潜空间可编辑性的权衡。然而实验观察上述反演会 出现人脸靠近平均人脸,边缘信息缺失等情况,因此反 演优化的方法被提出着重解决此问题,这一部分是在第 一步的基础上通过优化生成器参数或者调制生成器特征 图来实现的。值得注意的是感知性和可编辑性是从第一 步中继承而来的。在实际应用中,如果潜在向量不能被 编辑或生成感知质量良好的图像,细化后的结果仍然表 现出相同的效果。因此,获得具有更好的性能的潜在码依旧是目前图像反演方法的挑战。
参考文献
[1] KARRAS T,LAINE S,AILA T,et al.A Style-based Generator Architecture for Generative Adversarial Networks[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),2019:4396-4405.
[2] ABDAL R,QIN Y,WONKA P,et al.Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? [C]//IEEE/CVF International Conference on Computer Vision (ICCV),2019:4431-4440.
[3] KYOUNGKOOK K,SEONGTAE K.GAN Inversion for Out-of-range Images With Geometric Transformations [C]//IEEE/CVF International Conference on Computer Vision(ICCV),2021:13921-13929.
[4] RICHARDSON E,ALALUF Y,PATASHNIK O,et al. Encoding in Style:A StyleGAN Encoder for Image-to-image Translation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),2021:2287-2296. [5] TOV O,ALALUF Y,NITZAN Y,et al.Designing an Encoder for StyleGAN Image Manipulation[J].ACM Transactions on Graphics,2021(40):1-14.
[6] YAO X,NEWSON A,GOUSSEAU Y,et al.A Style-based Gan Encoder for High Fidelity Reconstruction of Images and Videos[C]//European Conference on Computer Vision,2022:581-597.
[7] LIU H,SONG Y,CHEN Q,et al.Delving StyleGAN Inversion for Image Editing:A Foundation Latent Space Viewpoint[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),2023:10072-10082.
[8] ROICH D,MOKADY R,BERMANO A H,et al.Pivotal Tuning for Latent-based Editing of Real Images[J].ACM Transactions on Graphics (TOG),2022.42 (1):1-13.
[9] ALALUF Y,TOV O,MOKADY R,et al.HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing[C]//In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2022.
[10] WANG T,ZHANG Y,FAN Y,at al.High-fidelity GAN Inversion for Image Attribute Editing[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),2022:11369-11378.
[11] CAO P,YANG L,LIU D X,et al.What Decreases Editing Capability?Domain-Specific Hybrid Refinement for Improved GAN Inversion[J].2023.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/67676.html