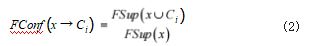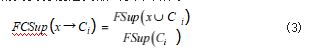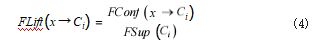SCI论文(www.lunwensci.com)
摘 要: 模糊分类关联规则(Fuzzy Classification Association Rules,FCAR) 是一种特殊的模糊关联规则, 挖掘 FCAR 对于构建基于规则的分类模型至关重要。传统关联规则挖掘算法挖掘 FCAR 时可能会包含较多冗余规则,并且在数据集 类别不平衡时,挖掘到的小类规则的数量会急剧减少甚至降为 0.为解决上述问题,提出了一种基于特征选择和模糊类支持度 - 模糊提升度框架(Fuzzy Category Support-Fuzzy Lift Framework,FCS-FLF) 的 FCAR 挖掘算法 FSFCS Based FCAR- Miner(Feature Selection and Fuzzy Category Support-Fuzzy Lift Framework Based FCAR-Miner),基于模糊隶属度矩 阵迭代挖掘 FCAR。在多个类别不平衡的数据集上的实验结果表明,相比其他算法 FSFCS Based FCAR-Miner 算法能够避免 大量冗余规则的生成,同时也能适应数据类别不平衡的情况,不会出现各类规则数量相差悬殊的情况。
Fuzzy Classification Association Rule Mining Algorithm Based on Feature Selection and Fuzzy Category Support
WANG Ziheng1. LI Peng1.2. CHEN Jing1
(1. School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210023;2. Jiangsu
High Technology Research Key Laboratory for Wireless Sensor Networks, Jiangsu Province, Nanjing Jiangsu 210023)
【Abstract】:Fuzzy Classification Association Rules (FCAR) is a special type of fuzzy association rule that plays a crucial role in constructing rule-based classification models. Traditional association rule mining algorithms may generate a large number of redundant rules when mining FCAR, and when dealing with imbalanced datasets, the number of rules discovered for minority classes can drastically decrease or even become zero. To address these issues, a FCAR mining algorithm called FSFCS based FCAR-Miner (Feature Selection and Fuzzy Category Support- Fuzzy Lift Framework Based FCAR-Miner) is proposed. It utilizes a fuzzy category support-fuzzy lift framework and incorporates feature selection techniques to iteratively mine FCAR based on a fuzzy membership degree matrix. Experimental results on multiple imbalanced datasets demonstrate that compared to other algorithms, FSFCS Based FCAR-Miner can avoid generating a large number of redundant rules and also handle imbalanced data classes without significant discrepancies in the number of rules discovered for each class.
【Key words】:fuzzy classification association rule mining;feature selection;category imbalance data;fuzzy category support
0 引言
关联规则挖掘是数据挖掘领域中一种重要的研究方 法,在金融、医学、网络安全等领域的数据分析和分类工作中有着广泛的应用 [1-3]。但传统的关联规则挖掘方 法在处理连续型属性时容易出现边界尖锐的问题,于是 研究者将模糊集理论和关联规则有机结合提出了模糊关联规则,实现了相邻属性区间的平滑过渡。FCAR 是一 种特殊的模糊关联规则,可以用于构建基于规则的分类 模型,其规则前件是不包含类别标签的项集,规则后件 为一个类别标签。
为解决常规关联规则挖掘算法在挖掘分类关联规则 时易受类别不平衡的影响以及挖掘效率较低的问题,许 多学者进行了大量研究。为了解决基于支持度 - 置信 度的关联规则挖掘算法在少数类上生成规则较少的问 题,黄再祥等人 [4] 提出了一种根据项集与类别的正相 关度来提取规则的方法,有效提高了小类规则的数量。 Shabtay[5] 等人针对从不平衡数据中生成的少数类规则 数量较少的问题,提出了一种称为 Minority-Report Algorithm(MRA)的算法,该算法通过选择与少数 类别相关的项集作为候选项集,避免了少数类规则的丢 失。周忠眉等人 [6] 则提出了一种基于各类的类支持度阈 值独立挖掘的分类关联规则挖掘算法,旨在在类别不平 衡数据集中生成更多高置信度的规则。杨光飞等人 [7] 提 出了一种关键值抽样法,通过增加与少数类相关性强的 数据并减少与多数类相关性弱的数据,以实现数据类分 布的平衡,然后再通过常规方法获取分类关联规则。为 了提高关联规则挖掘算法在挖掘分类关联规则时的效 率,Dang 等人 [8] 提出了一种基于晶格结构和两组对象 标识符之差的分类关联规则挖掘算法,实验结果表明该 算法在挖掘时间和内存使用量方面均优于现有方法。
以上改进虽然从一定程度上缓解了常规算法在挖掘 分类关联规则时少数类规则丢失和效率低下的问题,但 是挖掘结果仍会存在大量的冗余规则,并且规则质量不 能得到保障。本文提出了一种基于特征选择和模糊类支 持度的模糊分类关联规则挖掘算法,可以高效生成高质 量的 FCAR。本文的主要贡献是 :
(1) 使用 CatBoost-BorutaShap 特征选择算法对 待挖掘数据的维度进行削减,在确保重要规则不会丢失 的情况下,避免了大量冗余规则的产生。
(2)提出一种 FCS-FLF 代替常规算法所使用的模 糊支持度 - 模糊置信度框架,较好地解决了数据类别不 平衡对挖掘带来的不利影响,并过滤了低质量规则。
1 背景知识介绍
本节介绍文中使用到的一些基本定义以及相关背景 知识。
1.1 基本定义
定义 1(模糊支持度)项集 x 的模糊支持度定义如公式(1)所示 :
其中 μ(x) 表示项集在数据集中的模糊支持数, |D | 表示训练集总的实例数,模糊支持度用来衡量项集 x 在 数据集中出现的频率。
定义 2(模糊频繁项集)如果一个项集 x 的模糊支 持度不小于最小模糊支持度阈值,那么 x 就称为模糊频 繁项集。
定义 3(模糊置信度)规则 x → Ci 的模糊置信度定 义如公式(2)所示 :
模糊置信度用来表示在包含 x 的记录中类别 Ci 出现 的频繁程度。
定义 4(模糊类支持度)规则 x → Ci 在类 Ci 下的
模糊类支持度定义如公式(3)所示 :
定义 5(模糊提升度)规则 x → Ci 的模糊提升度定义如公式(4)所示 :
1.2 CatBoost 算法介绍
CatBoost(Categorical Boosting) [9] 是搜索引擎 公司 Yandex 开发的一种基于梯度提升树的机器学习算 法,常用于解决分类和回归问题。它的主要优势是能够 对类别特征进行高效处理、无需调参即可获得较高的模 型质量、解决了预测偏移以及梯度偏差的问题,从而减 少过拟合,进而提高模型的泛化能力和准确性,被广泛 应用于分类、回归、排序等场景中。
1.3 BorutaShap 算法介绍
BorutaShap 是一种包装器特征选择方法,它是 Boruta 特征选择算法 [10] 与 Shapley 值 [11] 的结合。事实 证明,这种组合在速度和生成的特征子集的质量方面都 优于原始的排列重要性方法,该算法不仅提供了更好的 特征子集,而且还可以同时提供最准确和一致的全局特 征排名 [12]。BorutaShap 算法在特征选择过程中可以选 择任何基于树的学习器作为基学习器,考虑到 CatBoost 在表格类型数据分类和回归任务中的出色表现,本文中 选取了 CatBoost 作为 BorutaShap 算法的基学习器。
其中 Boruta 算法是一种基于树模型的特征选择算 法,它通过模拟树模型的重要性评估过程,构造出一组 虚拟的随机特征,来评估真实特征的重要性。对于每 个特征, Boruta 算法会构造一个与之对应的阴影特征, 通过比较真实特征和阴影特征在树模型中的重要性,来判断真实特征的重要性。而 Shapley 值分析是一种博 弈论中的概念,用于计算每个特征对于模型预测的贡献 度。在机器学习领域中, Shapley 值可以用于计算每个 特征对于预测结果的重要性,具体计算方法见文献 [11]。
2 CatBoost-BorutaShap 特征选择算法
传统分类关联规则挖掘算法在进行挖掘前不会对原 始数据做特征工程,因此可能会导致部分与类别标签无 直接关系的属性也进入到了规则挖掘的阶段,这样不仅 大大增加了挖掘工作的计算量,更会导致结果中出现大 量的冗余规则,降低挖掘结果的质量。
为了解决这一问题,本算法在数据预处理阶段以 CatBoost 作为基学习器, 使用 BorutaShap 算法对待挖 掘数据进行特征选择, 由此提出了 CatBoost-BorutaShap 特征选择方法,仅保留该方法认为重要的属性进入规则 挖掘阶段。这样做不仅可以有效降低原始数据的维度, 而且可以降低挖掘所需的计算量,更避免了冗余规则的 生成,提高了挖掘结果的质量。
2.1 CatBoost-BorutaShap 算法特点及优势介绍
CatBoost-BorutaShap 算法结合了 CatBoost、Boruta 和 Shapley Value 3 个技术,旨在进行特征选择和解释 特征重要性。下面是 CatBoost-BorutaShap 算法的特点 :
(1) CatBoost 集成学习 :CatBoost 是一种基于梯 度提升决策树(Gradient Boosting Decision Tree) 的 强大机器学习算法。它在处理分类和回归任务时表现出 色, 具有优秀的准确性和鲁棒性。CatBoost 能够自动 处理类别型特征和缺失值,还具备优化的学习率调度和 随机性的处理能力。
(2)Boruta 特征选择 :Boruta 是一种基于随机森 林的特征选择算法。它通过比较每个特征的重要性与随 机生成的阴影特征之间的关系,来确定哪些特征是真正 重要的。Boruta 算法能够解决特征间的相关性和噪声 对特征选择的影响,能够较好地识别出真正与目标变量 相关的特征。
(3) Shapley Value 特征重要性 :Shapley Value 是 一种博弈论概念,用于衡量每个特征对于模型预测的贡献 程度。在 CatBoost-BorutaShap 算法中,Shapley Value 被用来计算每个特征的重要性得分。通过使用 Shapley Value,可以解释模型对于不同特征的预测决策过程, 了解每个特征在模型中的作用。
由于具有上述特点, 因此 CatBoost-BorutaShap 算法天生具有以下优势 :
(1) 自动特征选择 :CatBoost-BorutaShap 算法 能够自动选择最相关的特征,减少了手动特征选择的主观性和工作量。
(2)考虑特征间关系 :Boruta 算法能够处理特征 间的相关性和噪声,准确识别出真正与目标变量相关的 特征。
(3)解释每个特征的特征重要性 :通过 Shapley Value,CatBoost-BorutaShap 算法能够解释每个特征对于 模型的贡献程度, 提供了对模型预测过程的更深入理解。
(4) 更加准确的特征重要性评估 :CatBoost-Boruta Shap 算法使用了 CatBoost 作为基础模型,充分发挥 了 CatBoost 在分类和回归任务上的优越性能。
2.2 CatBoost-BorutaShap 算法流程
CatBoost-BorutaShap 算法总共包含如下 6 个步骤 :
(1)首先创建数据集中所有特征的新副本并将其命 名为 shadow+feature_name, 然后对这些新添加的特 征进行随机排序以消除它们与响应变量的相关性。
(2) 对包含随机阴影特征的扩展数据运行 CatBoost 分类器,然后使用特征重要性指标 Shapley Value 对特 征进行排名。
(3)使用阴影特征中的最大重要性得分创建阈值, 然后将超过此阈值的特征标记为已分配。
(4)对于每个未分配的特征进行双侧 T 检验。
(5)重要性明显低于阈值的特征被视为“不重要”, 并将其从流程中删除,重要性明显高于阈值的特征视为 “重要”。
(6)移除所有阴影特征并重复该过程,直到为每个 特征分配了重要性,或者算法已达到先前设置的最大运 行次数。
3 FSFCS Based FCAR-Miner 算法介绍
3.1 模糊隶属度函数的生成
要进行 FCAR 的挖掘,首先需要将原数据通过模 糊隶属度函数转换成模糊隶属度矩阵。目前模糊隶属度 函数的生成方法主要有两种,基于数据驱动的方法和基 于专家知识的方法。基于专家知识的方法即专家根据先 验知识直接给出相应的模糊隶属度函数,但在实际应用 中,数据集中往往包含了大量的项和事务,这导致专家 也很难快速给出全面且准确的隶属度函数。所以在处理 数据集时,通常使用基于数据驱动的方法产生模糊隶 属度函数。本小节介绍了基于模糊 C 均值聚类(FCM) 算法 [13] 生成的聚类中心来产生对应项的三角形隶属度 函数的方法,以便后续对原始数据进行模糊化。
生成隶属度函数首先要对原数据进行 FCM 聚类得 到每列属性的聚类中心,然后根据特定公式生成隶属度 函数。出于规则可解释性的考虑,不宜将聚类数目设置的太多,因此本文将聚类数设定为了 3.即模糊关联 规则的语言标记数量为 3.分别命名为 Low、Mid 和 High。聚类中心为 3 个时隶属度函数如公式(5)所 示,聚类中心为其余数目的公式可以类似得到。
其中,在聚类中心按升序排列的情况下, a 代表第 一个聚类中心, b 代表第二个聚类中心, c 代表第三个聚 类中心,区间 [0.b] 代表了语言标记 Low,区间 [a,c] 代表 了语言标记 Mid,区间 [b,+ ∞ ] 代表了语言标记 High, x 代表待模糊化数据的值,代表原数据模糊化后的隶属度值。
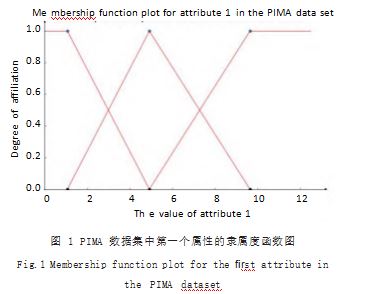
接下来进一步进行举例说明如何从指定数据集中 生成隶属度函数,指定 FCM 算法的聚类数为 3.运行 算法得到指定数据集中第一个属性的三个聚类中心为 1.0685、4.9187 和 9.6441. 那么该属性所对应的隶属 度函数表达式如公式(6)所示 :
该函数的图像如图 1 所示。
3.2 模糊隶属度矩阵生成
在通过 FCM 算法得到原始数据各属性的隶属度函 数后,即可通过隶属度函数将原始数据转换为隶属度矩 阵进行存储。这样做方便后续算法直接通过矩阵列之间 的逐位取最小值运算来获得指定项集的模糊支持度,避 免了对数据库的多次扫描和数据模糊化,可以有效提升 算法的运行效率。
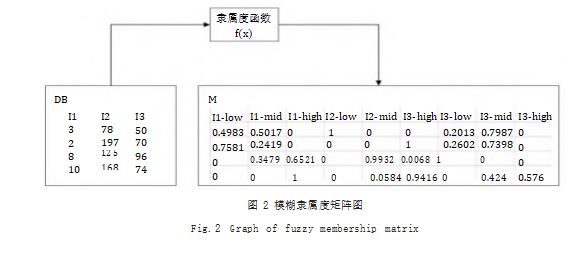
接下来举例说明如何将原数据转换为隶属度矩阵。 设聚类中心数为 3. 事物数据库 DB={T1.T2.T3. … Tn}, 项集 {I1.I2.I3. …Im}, 对于包含 n 条事务, m 项的原始数据,以事务为行,项为列建立一个 n 行 3m 列的隶属度矩阵 M。建立规则如下 :扫描每一条事务, 将事务中每一项的值输入对应的隶属度函数中,得到该 项对于语言标记分别为 Low、Mid 和 High 的隶属度 数值共 3 个,然后依次将这些值写入隶属度矩阵对应的 位置中。详细转换过程如图 2 所示, f 表示原始数据 DB 到隶属度矩阵 M 之间的映射关系。
3.3 FSFCS Based FCAR-Miner 算法
本章结合特征选择和数据挖掘的相关知识,提出 了一种基于特征选择和 FCS-FLF 的 FCAR 挖掘算法 FSFCS Based FCAR-Miner, 该算法基于模糊隶属度 矩阵迭代挖掘规则,可以实现对数据集中隐含的高质量 FCAR 的有效挖掘,帮助使用者提取数据中存在的隐含 知识。
首先举例说明在类别不平衡数据挖掘中常规模糊支 持度 - 模糊置信度框架的局限性。设现有一个包含 3000 条记录的不平衡数据集 Data,其类别标签分别为 0 和 1.类别 0 与类别 1 的数据比例为 1 :9.假设所有标签 为 0 的记录中存在频繁模式 a,其模糊支持度为 0.08. 所有标签为 1 的记录中同样存在频繁模式 a,其模糊 支持度为 0.32.那么不难得出规则 a → 0 的置信度为 0.2. 而规则 a → 1 的置信度为 0.8.由此可以判断规 则 a → 1 的可信度更高。但实际上在所有类别为 0 的记 录中频繁模式 a 出现的占比为 80%,而在所有类别为 1 的记录中频繁模式 a 出现的占比仅约为 35.56%,也就 是说实际上规则 a → 0 的可信度更高,这与先前的判断 完全相反。出现该问题的原因在于 Data 中类别为 1 的 记录的数量远远大于类别为 0 的记录的数量,所以即使 频繁模式 a 在类别 0 中的出现频率很高,但是由于模糊 置信度的定义还是会导致规则 a → 1 的模糊置信度较 高。此外,在 Data 中挖掘 FCAR 时,假设最小模糊支 持度阈值设为 0.1.那么规则 a → 0 将根本不会被挖掘 到,想要挖掘到这条规则就需要降低最小模糊支持度阈 值,但这又会导致挖掘得到的类别 1 的 FCAR 过多。
为了解决以上问题,本文提出了一种 FCS-FLF,通 过使用该框架代替一般关联规则挖掘算法中使用的模 糊支持度 - 模糊置信度框架来避免数据类别不平衡对 FCAR 挖掘带来的不利影响。该框架与原先框架的区别 在于 :
(1)根据最大类的最小模糊类支持度阈值为其余每 个类都设定了一个最小模糊类支持度阈值,每个类别 基于自己的最小模糊类支持度阈值独立挖掘模糊频繁 项集,然后直接由各类的模糊频繁模式和类标签得到 FCAR。其中最大类的最小模糊类支持度阈值人为指定, 其余类的最小模糊类支持度阈值由公式(7)生成,其 中代表最大类的最小模糊类支持度阈值,代表类 i 的最 小模糊类支持度阈值。
(2)使用最小模糊提升度阈值(该值固定为 1)替换最小模糊置信度阈值用来筛选高质量 FCAR。因为从 统计角度来看,模糊提升度衡量的是一个模糊分类规 则前件与类标签的关联程度,所以可以用它来衡量一个 FCAR 的规则质量,具体衡量标准如式(8)所示 :
基于 FCS-FLF 的 FCAR 挖掘算法是 FSFCS Based FCAR-Miner 算法的重要组成部分,它确保了 FSFCS Based FCAR-Miner 挖掘方法可以高效挖掘高质量的 分类关联规则, 而 CatBoost-BorutaShap 特征选择算 法在确保了规则的简洁性的同时提升了基于 FCS-FLF 的 FCAR 挖掘算法的运行效率。两种算法共同组成了 FSFCS Based FCAR-Miner 算法, 算法伪代码如算法 1 所示 :
算法 1 :FSFCS based FCAR-Miner 算法
输入 :待挖掘数据集 Data,最大类的最小模糊类 支持度阈值 θ
输出 :规则集合 FCAR
FS-Data=CatBoost-BorutaShap(Data)// 对原始数 据进行特征选择以构建新的数据子集
Function=getFunction(FS-Data)// 生成对应的三 角形模糊隶属函数
FFS-Matrix=Fuzzy(FS-Data,Function)// 使用模糊 隶属度函数将数据集转换成模糊隶属度矩阵
FM-Set(n)=divide(FFS-Matrix)// 将模糊隶属度矩 阵按照类别分割为 n 个子矩阵,n 为类别数
FOR each FM in FM-Set(n) DO
σ=Calculate-threshold(θ)// 根据公式计算该类的 最小模糊支持度阈值 σ
FFI=miningFrequentItemstes(FM,σ)// 挖掘该类 的模糊频繁项集
CFCAR=GenerateFCAR(FFI)// 根据类别标签直接 生成该类的 FCAR
FCAR=FCAR+CFCAR// 合并不同类别的 FCAR
END FOR
FOR each rule in FCAR DO
FuzzyLift=Calculate-FuzzyLift(rule)// 计算每条规 则的模糊提升度
IF FuzzyLift<=1 THEN
remove(rule,FCAR)// 将规则从 FCAR 中移除
END IF
END FOR
4 实验设计与实验分析
4.1 实验设计
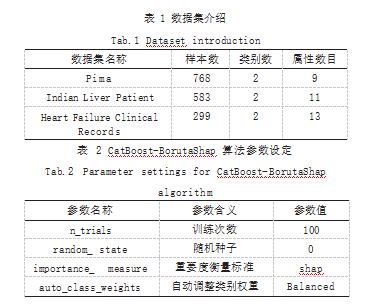
本文选取了 3 个常用医学数据集进行实验,这 3 个数 据集都存在不同程度的类别不平衡的情况,如表 1 所示可 以看出每个数据集包含的样本总数、类别数、属性数目。后 文中将 Indian Liver Patient 数据集简称为 Liver 数据集, 将 Heart Failure Clinical Records 简称为 Heart 数据集。
在本小节实验中 CatBoost-BorutaShap 算法对每 个数据集设置的参数是相同的,其中主要参数设定情况 如表 2 所示。
4.2 实验分析
4.2.1 不同数据集特征选择结果
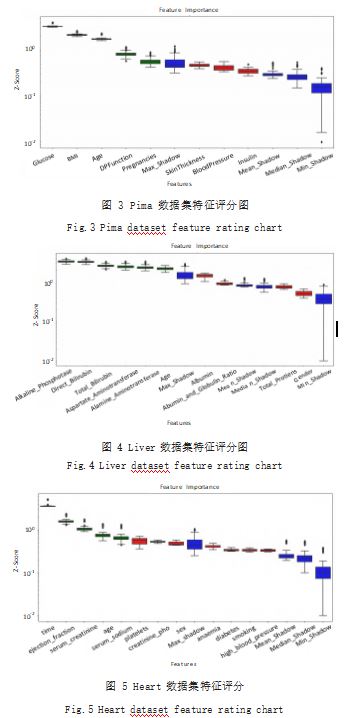
(1) Pima 数据集的特征评分图如图 3 所示,其中纵 坐标 Z-Score 是用于衡量特征重要性的一种标准化指标, 它是通过计算每个特征的原始重要性分数与所有特征的 平均值和标准差之间的差异得到的,横坐标代表了不同 属性的名称。将阴影特征中最大的 Z_Score 记为 Zmax, 算法仅把 Z-Score 数值大于 Zmax 的特征视为重要特征, 并使用这部分特征构成新的数据集。从图 3 中不难看出 算法将 BMI、DiabetesPedigreeFunction、Glucose、 Pregnancies 和 Age 五个特征视为重要特征,其余特 征则视为不重要特征。
(2) Liver 数据集的特征评分图如图 4 所示,看出算法 将Alkaline、Age、Aspartate、Alamine、Direct_Bilirubin 和 Total_Bilirubin 六个特征视为重要特征, 其余特征 则视为不重要特征。
(3) Heart 数据集 的特征评分图如 图 5 所示, 从 图 5 中可 以看 出 CatBoost-BorutaShap 算法将 Serum_ sodium、Time、Age、Serum_creatinine 和 Ejection_fraction 五个特征视为重要特征,其余特征则视为不重 要特征。
4.2.2 模糊分类关联规则挖掘结果对比
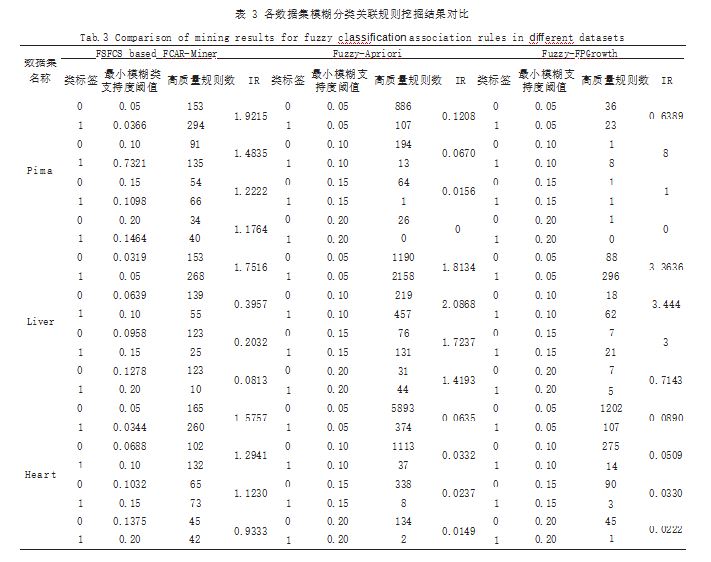
本节选取了经典的模糊关联规则挖掘算法 Fuzzy- Apriori[14] 以及 Fuzzy-FPGrowth[15] 作为本文算法的对 比算法,实验中对原始数据进行模糊化的方法都是相同 的。实验结果如表 3 所示, 其中 IR 为不平衡比例, 代 表了类别为 1 的规则数与类别为 0 的规则数的比值, IR 越接近于 1 则表示挖掘结果受类别不平衡的影响越小。
从表 3 中可以得出以下结论 :
(1) 相比于其他两个算法,本文提出的 FSFCS Based FCAR-Miner 算法在绝大部分情况下 IR 的数值更接近 于 1.即不同类别的 FCAR 数量是相近的,这意味着本 文所提算法可以较好地适应数据类别不平衡的情况。
(2) 本文所提出的 FSFCS Based FCAR-Miner 算 法在因进行特征选择而导致原始数据属性值减少的情况 下,在高支持度下挖掘出的高质量规则总数相比其他算 法并没有减少太多,甚至更多 ;而在较低支持度下两种 对比算法不仅出现了规则数量迅速增加的现象(即规则 爆炸),还因为没有在挖掘前去除冗余属性,导致挖掘 结果包含了大量冗余规则,这对后续的知识发现和规则 应用带来了一定的阻碍,而本文所提算法能够在较低支 持度下保持较少的高质量规则数量,同时不会产生规则 爆炸的现象。
5 结论
FCAR 作为一种特殊的模糊关联规则,在知识发现、模糊关联分类等方面中有着广泛的应用。而大部分 关联规则挖掘算法在挖掘 FCAR 时不能较好地解决类别 不平衡、规则冗余等问题,严重影响了 FCAR 的质量。 为此本文提出了一种基于特征选择和 FCS-FLF 的模糊分 类关联规则挖掘算法 FSFCS Based FCAR-Miner, 实 验结果表明,该算法可以较好地解决上述问题,具有一 定实用价值。
参考文献
[1] 崔妍,包志强.关联规则挖掘综述[J].计算机应用研究,2016. 33(2):330-334.
[2] MICHELA A,PIETRO D,FRANCESCO M,et al.A Novel Associative Classification Model Based on a Fuzzy Frequent Pattern Mining Algorithm[J].Expert Systems With Applications,2015.42(4):2086-2097.
[3] SANZ J,SESMA-SARA M,BUSTINCE H.A Fuzzy Association Rule-based Classifier for ImbalancedClassification Problems[J]. Information Sciences,2021:577.
[4] 黄再祥,周忠眉,何田中,等.改进的多类不平衡数据关联分类 算法[J].模式识别与人工智能,2015.28(10):922-929.
[5] SHABTAY L,FOURNIER V P,YAARI R,et al.A Guided FP-Growth Algorithm for Mining Multitude-targeted item-sets and Class Association Rules in Imbalanced Data[J].Information Sciences,2020.
[6] 周忠眉,李家辉.基于各类支持度阈值独立挖掘的关联改进 算法[J].计算机工程与科学,2019.41(11):2088-2094.
[7] 杨光飞,崔雪娇,张翔.基于抽样和规则的不平衡数据关联分 类方法[J].系统工程理论与实践,2017.37(4):1035-1045.
[8] DANG N,LOAN T T N,BAY V,et al.Efficient Mining of Class Association Rules with the Itemset Constraint[J]. Knowledge-Based Systems,2016.103(1):73-88.
[9] PROKHORENKOVA L,GUSEV G,VOROBEV A,et al. CatBoost:Unbiased Boosting with Categorical Features[J]. 2017.
[10] MIRON B K,WITOLD R R.Feature Selection with the Boruta Package[J].Journal of Statistical Software,2010. 36(11):1-13.
[11] LUNDBERG S M,LEE S I.A Unified Approach to Interpreting Model Predictions[J].Advances in Neural Information Processing Systems,2017:30.
[12] GHOSH I,CHAUDHURI T D.Integrating Navier- Stokes Equation and Neoteric iForest-BorutaShap-Facebook's Prophet Framework for Stock Market Prediction:An Application in Indian Context[J].Expert Systems With Applications,2022:210.
[13] BEZDEK J C,EHRLICH R,FULL W E.FCM;The Fuzzy c-means Clustering Algorithm[J].Computers & Geosciences, 1984.10(2-3):191-203.
[14] VERLINDE H,De COCK M,BOUTE R.Fuzzy Versus Quantitative Association Rules:A Fair Data-driven Comparison[J].IEEE Transactions on Systems,man and Cybernetics,2006.36(3):679-684.
[15] BARIK S,MISHRA D,MISHRA S,et al.Pattern Discovery using Fuzzy FP-growth Algorithm from Gene Expression Data[J].International Journal of Advanced Computer Science & Applications,2010.1(5).
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/65285.html