SCI论文(www.lunwensci.com)
摘 要:近年来,随着高校毕业生人数不断上升,毕业生就业竞争压力与日俱增。本文以计算机软件行业为例,设计并 实现了一种基于大数据技术的行业招聘信息分析系统。利用 Scrapy 爬虫框架采集网络招聘数据,在 Hadoop 平台上,使用 MapReduce 对空值、重复值、异常值等异常数据进行数据预处理后,储存于 HDFS 分布式文件系统。之后选取行业、职位、 地域等多个维度对行业招聘需求进行分析,挖掘出针对高职院校人才招聘的精准需求,并使用 Java Web 进行数据可视化展示。 实践表明,计算机软件行业在职位、地域上存在较大差别,该系统能够为大学生在职业生涯规划上提供更有效的决策。
关键词: 网络招聘,高职就业,Scrapy 爬虫,Hadoop 分布式集群,数据分析,数据可视化
Job Demand Analysis Based on Hadoop Platform:Consider the Computer Software Industry
TIAN Qi, YANG Jiajun, QIN Tian
(College of Intelligent Engineering, Hubei Polytechnic, Shiyan Hubei 442000)
【Abstract】: In recent years, with the increasing number of college graduates, the pressure of graduate employment competition is increasing day by day. Taking computer software industry as an example, this paper designs and implements an industry recruitment information analysis system based on big data technology. The Scrapy crawler framework is used to collect network recruitment data. On the Hadoop platform, abnormal data such as null values, duplicate values and outliers are pre-processed by MapReduce and stored in the HDFS distributed file system. After that, the recruitment demand of the industry is analyzed from multiple dimensions such as industry, position and region, and the precise demand for talent recruitment in higher vocational colleges is mined, and the data is displayed visually using Java Web. The practice shows that there are great differences in positions and regions in computer software industry, and this system can provide more effective decision-making for college students in career planning.
【Key words】:online recruitment;vocational employment;Scrapy crawler;Hadoop distributed cluster;data analysis; data visualization
1 Hadoop 技术的应用
1.1 数据处理过程
首先通过 Hadoop 生态圈相关的技术构建大数据分 析平台,数据采集阶段构建 Scrapy-Redis 分布式爬虫任 务并使用 Scrapyd 对执行过程进行管理,每天采集知名 招聘网站的招聘信息。数据预处理阶段由 Azkaban 进行 MapReduce 任务调度管理, MapReduce 读取 HDFS 中的数据进行预处理。再通过 Hive 脚本任务调度管理执行 HQL 对数据进行分析,构建多维度的数据仓库进 行多角度的分析,挖掘潜在有价值的数据并将结果存 储到 Hive 数据仓库中。最后,构建 Java Web 应用系 统使用 ECharts 数据可视化技术将分析结果进行展示, 更加直观地理解数据的意义,如图 1 所示。
1.2 相关技术应用
招聘信息数据源是互联网公开的招聘网站信息,通 过 Web 相关技术对信息进行采集。数据采集阶段使用Python 数据爬虫常用技术 Scrapy 框架,使用 Scrapyd 部署分布式爬虫任务,进行发布、定时、日志记录等 操作。同时,爬取的招聘信息数据先存储在 Redis 缓 存数据中,应对数据采集过程可能中断的情况实现“断 点续爬”,再通过 Windows 定时任务执行 Python 程 序将数据持久化存储到 MySQL 数据中。最后,使用 Sqoop 数据迁移软件,将数据库中的招聘信息数据迁移 至 Hadoop 平台的 HDFS 分布式文件系统中。数据清洗 阶段,编写 MapReuce 程序读取 HDFS 中并进行预处 理。对数据进行重新审查和校验的过程,删除重复信息、 纠正存在的错误,并提供数据一致性 [1]。数据存储阶 段,通过行业、职位、地域等多个维度构建 Hive 数据仓 库,并将数据清洗后的数据导入。数据分析阶段,使用 Hive SQL 对数据进行多维度的分析。数据可视化阶段, 使用 HTML5、CSS3、JavaScript 搭建前端页面, 后端 JavaWeb 常用技术 Spring、SpringMVC、MyBatis 框架, 结合 ECharts 开源图表技术对数据进行展示。
2 数据采集方案
计算机软件行业的招聘信息每日新增或更新的数据量 约为 150 万条,所以数据采集需要保证高效率与可靠性。 数据采集使用 Scrapy 数据采集框架, Scrapyd 拥有版本 控制,如果爬虫出现了不可逆的错误,可以通过接口恢 复到之前的任意版本。在分布式爬虫中,将爬取任务分 配给多台计算机同时处理,相当于将多个单机联系起来 形成一个整体来完成任务,这样可提高爬虫的可用性及 稳定性。使用 Redis 缓存数据库用作消息队列将多个爬 虫任务联系起来,可以过滤掉网页中重复的数据,当出现 单点故障时也可以重新从故障点继续执行, 提高了数据 采集的可靠性。使用 Scrapy 框架中间件集成 Scrapyd 与 Redis, 将 Scrapy 框架项 目打包上传到 Scrapyd。 对上传的爬虫 Job 设置 20 个定时任务,在每天 0 点 开始执行爬取前一天 24 小时的招聘信息数据,通过Scrapyd Web 可以有效管理爬虫任务,直观地监控爬 虫运行过程。在执行爬虫任务前先提前执行 Window 系统的定时任务执行 Python 脚本,将待爬取的 URL 列表导入 Redis 缓存数据库,这样就实现了 20 个爬虫 任务同时执行的数据一致性与可靠性。在爬取数据缓存 到 Redis 数据库的同时, 执行 Python 脚本将 Redis 数 据库中的数据导入到 MySQL 数据库进行持久化存储。
3 数据预处理
在数据采集阶段最终数据从 Redis 缓存数据库导入到本 地Windows 系统中的 MySQL 数据库, 由于 Hadoop 平台 部署在虚拟机中的 Linux 系统,需要将爬取的数据通过 Shell 脚本执行定时任务,调用 Sqoop 数据迁移工具导入 到 HDFS(分布式文件系统)。同时,通过爬虫爬取的网 页源数据中会存在空值、重复值、异常值等异常数据的情 况,在构建数据仓库并导入数据前,编写 MapReduce 程 序对源数据进行数据清洗后再导入数据仓库。
3.1 Sqoop 数据迁移
使用 Sqoop 数据迁移工具将数据从本地 MySQL 数 据库导入到 HDFS,数据集为在数据采集阶段采集的网 页文本数据并存储在 MySQL 数据库中的结构化数据。本 文使用的计算机配置为 64G 内存、24 核 48 线程的主机, Hadoop 配置了 3 个节点 Node01、Node02、Node03. 分 别分配的资源为 18G 内存、处理器内核总数 16.同时开 启 20 个 MapReduce 任务执行导入操作,导入字段包括 发布时间、职位代码、职位名称(公司)、职位名称((标 准)、行业代码、行业名称(公司)、行业名称(标准)、 工作省份、工作城市、工作地区、学历要求、薪资范围、 公司性质、福利待遇、工作经验、详情 ID、详情链接、 公司规模、公司名称、招聘人数、工作地址、职位描述, 其中详情 ID 字段作为后续数据清洗阶段数据去重的依据。
3.2 MapReduce 数据清洗
3.2.1 字段处理
数据集为存储在 HDFS 中的招聘信息结构化数据, 但数据集中的数据存在缺失值、重复值、异常值的情 况,需要通过 MapReduce 程序进行数据清洗。首先以 “\001”为分隔符将数据字段进行分割,依次读取并对 需要处理的字段进行清洗,具体数据清洗规则包括 :
(1)一条数据的字段数量少于 20 的数据为缺项数 据,直接删除。
(2) 发布时间值为空(Node)的数据直接删除,其 他数据格式从 YYYY-MM-DD 改为 YYYYMMDD。
(3)学历要求做限定值域的处理,值域为 { 初中及 以下,高中,中技,中专,大专,本科,硕士,博士 },对于学历为“高中”“中技”“中专”统一改为“高中 / 中技 / 中专”,其他情况改为“无学历要求”。
(4)薪资范围包括年薪、月薪、天薪、时薪,统一 按一个月工作日 22 天、一天 8 小时转化为月薪。
3.2.2 数据去重
在数据采集阶段采集了 30 天的招聘信息共 4400 万 条数据,这其中存在大量的重复数据。因为数据采集是 每日 0 点执行,按采集招聘信息的发布时间为前一日的 日期进行采集,但是根据招聘网站的发布规则,对于已 发布后重新编辑的数据会更新发布时间为当日日期。这 一条数据在分析时就可能会和之前采集的数据重复,其 中判断数据是否重复的字段是“详情 ID”,所以在做数 据去重时根据“详情 ID”进行分组并取分组中的最后 一条数据,这样保证了招聘信息的唯一性的同时,如果 存在更新的情况就确保了招聘信息的时效性。
4 数据仓库搭建
数据仓库是一个面向主题的、集成的、随时间变化 的,但信息本身相对稳定的数据集合,它用于支持企 业或组织的决策分析处理 [2],具有面向主题、随时间变 化、相对稳定的特点。Hive 是建立在 Hadoop 文件系 统上的数据仓库,它提供了一系列工具,能够对存储 在 HDFS 中的数据进行数据提取、转换和加载(ETL), 这是一种可以存储、查询和分析存储在 Hadoop 中的 大规模数据的工具 [3]。数据模型(Data Model) 是数 据特征的抽象,在数据仓库建设中,一般围绕星型模型 和雪花模型来设计数据模型。本文采用雪花数据模型, 雪花模型是当有一个或多个维表没有直接连到事实表 上,而是通过其他维表连到事实表上,其图解像多个雪 花连在一起,故称雪花模型。
5 数据分析
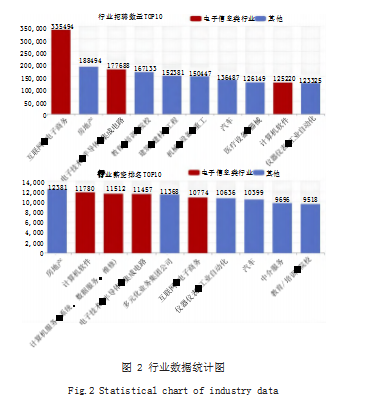
经过数据采集、数据预处理、数据存储、数据分析 阶段,将采集到的原始数据进行清洗并分析得到了招聘 信息的分析结果。构建 Java Web 系统集成 ECharts 开 源图表技术,将分析的结果直观地进行展示。如图 2 所 示,在招聘网站中的 65 个行业分类中,招聘数量前 10 的行业有互联网 / 电子商务、电子技术 / 半导体 / 集成 电路、计算机软件三个行业属于电子信息大类,也印证 了高校的电子信息类专业招生火爆的景象。除了常见的 软件开发岗位外,从售前、需求调研、需求分析、程序 设计、编码、测试、部署、运维整个软件生命周期中, 还包括售前工程师、运维工程师、测试工程师、技术支 持等大量工作岗位。计算机应用技术作为高职计算机专 业中的老牌专业,对应计算机软件行业不同的岗位的课 程体系较为完善,应使学生就业的方向多样化。在薪资待遇方面,电子信息类行业靠前,计算机软件行业更是 高居第二。就业机会多的同时收入也很可观,从事计算 机软件行业仍是不错的选择。
6 结语
本文以计算机软件行业为例,通过大数据分析行业 招聘数据,挖掘出针对高职院校人才招聘的精准需求。 可应用在日常的教学、人才培养方案的制订、学生实训 中提供决策帮助,深度探索高职教育与企业招聘需求之 间的关联。同时,搭建的 Hadoop 岗位需求分析系统 也可用于其他行业、专业,具有一定的适用性。在今后 的研究中,会对招聘数据中具体岗位详情的关键词进行 分析,可以更加详细地掌握招聘岗位对具体技能、素质 的要求。并通过大数据 Spark 平台的机器学习定义学生 标签,通过调查问卷、教学系统等数据源对学生进行画 像分析,再结合 Python 人工智能的推荐算法将行业招 聘分析的数据与学生标签进行匹配,从而达到更加精准 的岗位推荐,提高应届毕业生的就业率。
参考文献
[1] 李海波,张睿,张志明,等.基于大数据技术的大学生就业技能 需求分析系统[J].工业控制计算机,2022.35(10):127-130.
[2] 张琳琳,王顺江,郭星池,等.电力调度大数据应用平台系统技 术研究[J].电力大数据,2021.24(1):48-54.
[3] 李静,陆菊康,汤艳艳,等.基于数据仓库的销售分析系统的设 计与实现[J].计算机工程,2003.29(7):173-175.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/65264.html