SCI论文(www.lunwensci.com)
摘 要 :本文从船舶轨迹数据的特点入手,采用基于密度的聚类算法对船舶轨迹实现聚类,同时调用高德地图 API 与 ECharts 可视化库,对船舶航运信息进行可视化显示, 揭示船舶轨迹特征,最终完成了系统的设计与开发。对于船舶轨迹聚类 特征的探究,有助于揭示海域中船舶航道的分布特征、对港口主管部门实施的通航和环境管理工作奠定基础理论支持,进而为 海上运输和交通规划建设提供更加直观的科学依据。
关键词:AIS,大数据,时空聚类算法,KANN-DBSCAN,ECharts
Design and Development of Ship Shipping Information Visualization System
Based on ECharts
WANG Fangxiong1.2. LI Ying1.2
(1.Liaoning Key Lab of Physical Geography and Geomatics, Liaoning Normal University, Dalian Liaoning 116029;
2.School of Geographical Sciences, Liaoning Normal University, Dalian Liaoning 116029)
【Abstract】: This paper starts with the characteristics of ship trajectory data, adopts density-based clustering algorithm to cluster ship trajectory, and invokes amap API and ECharts visualization library to visually display ship shipping information and reveal ship trajectory characteristics, and finally completes the design and development of the system. The exploration of ship trajectory clustering features is helpful to reveal the distribution characteristics of ship channels in the sea area, lay the basic theoretical support for the navigation and environmental management implemented by the port authorities, and then provide a more intuitive scientific basis for Marine transport and traffic planning and construction.
【Key words】:AIS;big data;spatio-temporal clustering algorithm;KANN-DBSCAN;ECharts
引言
船舶自动识别系统(Automatic Identification System, AIS)是一种实用的海上通信手段,能够实现船与船、 船与岸之间的实时数据交换以及目标信息识别等功能 [1]。 传统的 AIS 数据表达大多是借助单一的 MATLAB 软件 或 Python 语言进行聚类后直接输出结果,可视化表达 效果并不理想。除此之外,传统方法不但对软件平台的 依赖性较高,而且对使用系统的依赖性较强,不便于用 户的日常操作及使用。
近年来,关于船舶轨迹聚类的研究方法集中于基于 统计学的、基于距离的 [2.3] 以及基于密度 [4] 的三种方法, 其中基于密度进行聚类的方法最为流行。DBSCAN 算法 是其中最常用的算法,并广泛应用于船舶 AIS 数据 [5]。
目前国内外对于 AIS 数据轨迹聚类的研究大多集 中在分析主要航道、发现航行危险区域及相关算法的 改进等方面 [6-10],在船舶轨迹聚类与其可视化系统的实 现方面应用较少。在算法方面,大多采用 DBSCAN 算 法,但该算法在参数选择上有很强的主观性,且参数对聚类结果有较大的影响,故本文选择一种便捷的自适应 DBSCAN 聚类算法,减少人为因素对参数选择的影响。 在此基础上,调用高德开放平台提供的 API 与 ECharts 提供的可视化库,实现地图与相关图表的显示,设计并 开发一个可以将船舶航运信息进行可视化表达的系统。
1 数据及预处理
AIS 数据可分为静态数据与动态数据两类。静态数 据包括呼号、船名、船舶尺寸、吃水深度、船舶类型等 ; 动态数据主要包括经度、纬度、船速、航向和时间等。
受传感器在信号传输中产生的误差影响,原始 AIS 数据具有采样不均匀、存在噪声数据、数据缺失等诸多 问题。因此需要进行数据清洗,根据需求筛选出符合要 求的数据,包括处理无效数据与验证有效数据。
为完成系统测试, 考虑到聚类效果及运行速度等方面 的影响, 本研究先从数据库中筛选出了位于渤海附近海域 (经纬度为东经 113° 06'~127° 01'、北纬 35° 02'~44° 09 间) 的 AIS 数据,时间节点设置为 2020 年 3 月 15 日,从 符合条件的数据点中提取了 24h 中的约 60 万条船舶轨 迹数据,清洗掉轨迹缺失数据及其他问题数据,最终将 处理后的数据用于轨迹聚类的系统测试。
2 船舶轨迹提取算法
聚类(Cluster)是一种广泛应用于数据分析的统 计技术。聚类算法以数据间的相似性为依据,对其进行 有目标的分组,把相似的对象划分为同一类,同时该算 法也是数据挖掘中的常用算法之一,有利于人们掌握数 据的全局分布情况。
在实际应用中,需根据研究方向、应用范围、数据 属性等方面来选择适宜的方法。综合考虑了聚类形状、 数据类型、抗干扰性等多方面的因素后,认为在本文中 选择基于密度的聚类算法较为合适。
2.1 DBSCAN 算法
DBSCAN 算法是一种基于密度的空间聚类算法, 该算法最早于 1996 年 由 Martin Easter 等人提 出 [4]。 其实质是判断空间中数据分布的紧密程度,将相邻点划 分至同一个聚类类别。该算法无需指定簇的个数,仅需 设定两个参数 (Eps, MinPts) 并且可以在具有噪声的空 间数据库中发现任意形状的簇。
2.2 KANN-DBSCAN 算法
2.2.1 KANN-DBSCAN 算法概述
由于传统的 DBSCAN 聚类算法中参数的确定,通 常是由专业人士通过相关经验经反复验证而设定的,聚 类效果及准确性均难以保证。因此,通过如何科学的算 法确定参数成为了当下对 DBSCAN 算法进行改进的重要思路之一。
在研究对比了多种 DBSCAN 的自适应算法后,本 文以参数寻优策略为依据,选定了一种将密度阈值 Density 参数加入算法的改进算法 :KANN-DBSCAN(K- Average Nearest Neighbor DBSCAN) 算法。 该方法 率先由李文杰等人 [11] 提出,后罗文华 [12] 等人在该思 想的基础上又对算法进行了扩展,实现了网络入侵类别 检测。该方法将以 Eps 为半径画圆,在该圆内部存在 的 MinPts 数据点个数与圆的面积之比,称为密度阈值Density。利用公式表达如式(1)所示 :
将该参数引入聚类算法后,其值的大小将会直接影 响最终结果,通过对前人的实验进行总结,得出了以下 经验 :在簇数正确的情况下,随着密度阈值的减小,噪 声率会变低,聚类效果趋于正确。
2.2.2 KANN-DBSCAN 算法实现
对于如何选择合适的 Density 参数列表,是 KANN- DBSCAN 算法实现的关键。聚类的精确度和运算量由 列表的取值范围和参数间距决定,故需要在二者之间寻 找平衡点 [9]。因此, 需考察数据本身的空间分布特点, 以生成合适的密度阈值列表。具体实现如下 :
(1)生成 Eps 列表。
基于 K- 平均最近邻算法 (K-Average Nearest Neighbor, KANN) 和数学期望法生成 Eps 列表, KANN 算法是平 均最近邻算法的扩展。具体步骤如下 :
步骤 1 对待研究的数据集 D 进行操作,计算其距离分布矩阵 Dn×n,表达式如式(2)所示 :
其中, n 表示数据集中对象的个数, distance(i,j) 表 示对象 i 与对象j 之间的距离。
步骤 2 遍历距离矩阵 Dn×n 每一行元素,并对其进 行升序排列。D0 定义为对象到自身的距离,即为由第 一列数据所组成的距离向量到自身距离全为 0. Dk 表示 第 K 列数据构成的 KANN 距离向量。
步骤 3 计算距离向量 Dk 中所有元素的平均值,记为Dk ,循环计算所有的 K值,得到 Eps 的参数列表DEps , 表达式如式(3)所示 :
(2)生成 MinPts 列表。
利用数学期望法确定 MinPts 参数列表,具体步骤 如下 :
步骤 1 根据得出的 Eps 参数列表,对所有对象按顺序求出每个 Eps 参数所对应邻域中对象的数量。
步骤 2 对所有 Eps 参数所对应邻域中对象的数量数 学期望,将其作为MinPts 参数,表达式如式(4)所示 :
其中, n 为数据集 D 中对象的总数量, Xi 为第 i 个 对象在该 Eps 参数下邻域内对象总数。
(3)自适应确定最优参数。
在 Eps 列表与 MinPts 列表生成后,进行如下步骤, 以得到最优参数。具体步骤如下 :
步骤 1 将参数输入 DBSCAN 算法,遍历集合 DEps 中的每一个元素并依次使用,将其作为候选 Eps 参数, MinPts 参数是通过公式(8)求得的,基于此进行聚类 分析。由于 K 值的不同,故而会分别生成不同的簇数。 为判断结果的稳定性,本文认为,当连续三次生成的簇 数相同时,即可记此时的簇数 N 为最优簇数。
步骤 2 继续执行步骤 1.当所得簇数不等于 N 时,退出循环。并选用在退出循环时所对应的 K 的最大值作为最优 K 值。此时所对应的Dk 即为最优 Eps 参数,对 应的 MinPts 参数即为最优 MinPts 参数。
3 船舶航运信息可视化系统设计
3.1 系统结构设计
为实现船舶轨迹聚类与航运信息的可视化表达,基 于对以上算法的分析与实现,本研究拟采用前后端分离的 开发模式以保障系统的稳定性与维护的便捷性。前端通 过调用与需求对应的 API(Application Programming Interface,应用程序接口)向后端发送请求,后端负 责提供数据和服务,在收到请求后进行业务逻辑分析, 根据需求返回相应的数据以供前端调用,使用者只需要 通过浏览器便可对其进行相应操作。
本系统的前端网页采用 JavaScript+HTML5+CSS3 设计,实现页面的互操作。利用 ECharts 开源可视化库 与高德地图开放平台提供的JS API 接口等技术实现船舶 航运信息的可视化表达。前端由 HTML 搭建页面框架, 再利用JavaScript 实现对页面的操作并通过 CSS 对页面 进行美化 ;后端数据处理与聚类算法基于 Python 设计, 根据任务的不同, 通过引用 NumPy、Flask、Sklearn 等 Python 库以实现数据清理、操作、建模、可视化等 目标。
系统结构设计可分为以下三个层次, 具体如图 1 所 示。底层是数据层,将清洗后的 AIS 数据存储在数据库 中,除船舶的轨迹信息外还包含了其他属性信息,必要 时会对其进行增添、删除、修改、查询等基本操作 ;业务逻辑层是本系统的中间层,利用 Python 语言调用类 库,通过选定的 KANN-DBSCAN 聚类算法实现船舶轨 迹点的聚类计算,并且以服务的形式调用高德开放平台 提供的 JS API,同时调用 ECharts 可视化库,实现系 统的主体业务 ;业务逻辑层与用户层即客户端相连,用 户层用于实现用户交互, Web 浏览器即为本系统的用 户交互界面,该层次进行 Web 端地图显示以及业务层 的具体实现。
3.2 系统功能设计
船舶航运信息可视化系统设计如图 2 所示,其船舶 轨迹聚类分析系统的功能分为聚类算法模块与 Web 端 功能模块两个功能模块,各模块功能的详细设计如下 :
(1)聚类算法模块。聚类算法模块共分为聚类参数 自适应确定与轨迹点 DBSCAN 聚类两个主要功能,主 要利用 Python 实现。其中参数自适应确定法通过调用 Python 中 Math 类库、NumPy 类库与机器学习第三 方模块 Scikit-learn(Sklearn) 中的 DBSCAN 方法进行 数据分析运算。
(2) Web 端功能模块。Web 端功能模块共分为 地图基本操作、轨迹基本信息显示、轨迹聚类显示与 轨迹测距等主要功能。Web 端主要利用 JavaScript 结 合 HTML+CSS 实现。其中地图基本操作利用高德地图 API 提供的方法,实现底图显示、地图缩放、平移等功 能,轨迹基本信息显示实现点选轨迹点显示对应船舶信 息等功能。聚类结果显示在底图上,其他基本功能可通过点击按钮显示。
4 船舶航运信息可视化系统开发
4.1 系统主界面
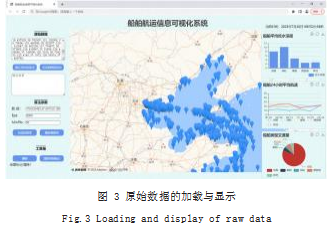
主界面由头部盒子与功能页面主体构成。顶部是标 题栏,用于显示系统的名称 ;左侧是系统工具栏,包括 本系统的基础功能,用户可以选择通过输入参数的方式 进行聚类,也可以通过点击按钮使用自适应的方法进行 聚类。中间地图通过 AMap 接口创建,显示测试数据 附近海域的地图底图以及待聚类的 AIS 船舶轨迹点数 据。页面右侧是 3 个 ECharts 图表,用于统计及显示船 舶相关航运信息。具体如图 3 所示。
4.2 聚类结果显示
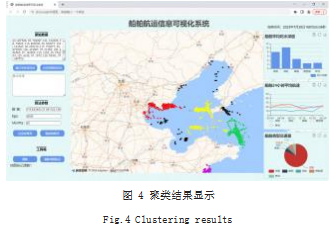
通过调用 DBSCAN 算法,完成船舶点的聚类。在 页面设置 3 个参数的输入框,分别输入经纬度坐标、邻 域半径、最少点数,点击“输参数聚类”按钮,完成聚 类 ;也可直接通过点击“自适应参数”按钮,进行聚类 显示。如图 4 所示, 展示的是 Eps=50000. MinPts=50 时的聚类结果,当鼠标移动到地图上的点上时会显示点 的簇类型。
4.3 其他功能实现
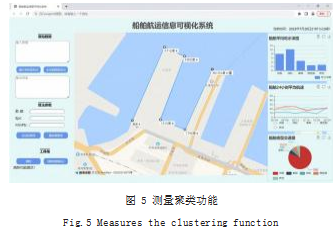
本系统通过调用高德开放平台提供的地图 JS API, 完成了地图的移动、缩放等基础功能。点击左侧工具栏中测距按钮,即可激活距离测量功能,在页面中点选两 点及以上,实现测距功能,双击表示结束测距。通过点 击“清除地图标记”按钮,可实现清除地图上新增的内 容。在点击系统界面中的按钮时,会在页面左下角以文 本的形式向用户进行提示。具体页面展示如图 5 所示。
5 总结
本文在数据挖掘技术与航海相关理论的基础上,确 定了以 DBSCAN 及其改进算法 KANN-DBSCAN 为轨 迹聚类的核心算法,将其应用到水路交通系统的研究 中,实现了船舶轨迹聚类的具体算法步骤,并将聚类结 果应用到了基于 B/S 架构的船舶航运信息可视化系统中。
在船舶轨迹聚类中应用了基于密度的 DBSCAN 聚 类算法。该算法仅需设置两个参数,不需要指定簇的个 数,并且可以发现任意形状的簇,在检测任务中善于发 现离群点。而 KANN-DBSCAN 的优势在于无需手动输 入参数,从而在一定程度上减少了人为选择参数对聚类 结果的影响,保证聚类结果的准确性与科学性,尽可能 地降低用户操作的复杂程度。
通过 Python 语言完成了船舶轨迹的聚类。在系统 开发部分,基于前后端分离的思想,后端数据处理与聚 类算法基于 Python 设计,根据任务的不同,通过引用 NumPy、Flask、Sklearn 等 Python 库以实现数据清 理、操作、建模、可视化等目标,并进行可视化展示。 为验证算法的实现,本文选取了一部分渤海附近海域的 船舶 AIS 真实数据,将轨迹数据导入该系统并进行了测 试。结果显示,通过该系统可以得到良好的船舶 AIS 轨 迹聚类效果,算法中的每一个步骤均正常实现。
参考文献
[1] 刘畅.船舶自动识别系统(AIS)关键技术研究[D].大连:大连 海事大学,2013.
[2] HUTTENLOCHER D P,KLANDERMAN G A,RUCKLIDGE WA.Comparing Images Usingthe Hausdorff Distance[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993.
[3] 魏龙翔,何小海,滕奇志,等.结合Hausdorff距离和最长公共 子序列的轨迹分类[J].电子与信息学报,2013.35(4):784-790. [4] ESTER M,KRIEGEL H P,SANDER J,et al.A Density- Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise[J].AAAI Press,1996.
[5] 徐良坤,任律珍,周世波.船舶AIS轨迹聚类方法研究进展综 述[J].广州航海学院学报,2019.27(2):7-12+47.
[6] LIU B,SOUZA E N D,MATWIN S,et al.Knowledge- based Clustering of Ship Trajectories Using Density- based Approach[C]//IEEE International Conference on Big Data.IEEE,2014.
[7] 罗启福.基于云计算的DBSCAN算法研究[D].武汉:武汉理工 大学,2013.
[8] 李东枫.基于AIS大数据的船舶危险会遇热点区域挖掘研究 [D].广州:华南理工大学,2017.
[9] KIM J H,CHOI J H,YOO K H,et al.AA-DBSCAN:An Approximate Adaptive DBSCAN for Finding Clusters with Varying Densities[J].TheJournal of Supercomputing,2018. [10] 李宗林,罗可.DBSCAN算法中参数的自适应确定[J].计算 机工程与应用,2016.52(03):70-73+80.
[11] 李文杰,闫世强,蒋莹,等. 自适应确定DBSCAN算法参数的 算法研究[J].计算机工程与应用,2019.55(5):1-7+148.
[12] 罗文华,许彩滇.利用改进DBSCAN聚类实现多步式网络入 侵类别检测[J].小型微型计算机系统,2020.41(8):1725-1731.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/65177.html