SCI论文(www.lunwensci.com)
摘要:全国工商联在进行相关业务数据处理时,需要处理来自不同地域、不同领域的非公企业金融、信用等经济数据,目的是横向统筹单一或多个组织在一个或多个领域相关的指标数据,为后续非公经济发展提供决策依据;此外,需判断全国工商联接入各省市工商联数据资源的情况,以对全国非公经济数据进行分析研判。本文提出一种数据虚拟化应用方法,并基于此方法连接使用跨域数据资源。将工商联接入的多源异构非公经济数据进行逻辑虚拟化,构造数据的逻辑空间,通过分簇算法优化元数据查询,并提出了基于Spark SQL分布式查询的优化方法,实施Catalyst自动缓存策略、使用中间数据结构等方式提高数据查询效率与读取性能,在保证数据准确性的同时提高工商联数据资源的利用率,促进工商联数据资产有效利用。
关键词:数据虚拟化;查询引擎;查询优化
Research on Data Query Optimization Method for Non-public Economy
WANG Wei,YANG Jingqi,TIAN Chengdong
(Information Science Academy of China Electronics Technology Group Corporation,Beijing 100041)
【Abstract】:When processing relevant business data,the All China Federation of Industry and Commerce needs to process economic data such asfinance and credit of non-public enterprises from different regions and fields,with the aim of horizontally coordinating indicator data related to one or more organizations in one or morefields,providing decision-making basis for subsequent non-public economic development;In addition,it is necessary to assess the access of the All China Federation of Industry and Commerce to data resources of various provincial and municipal federations of industry and commerce,in order to analyze and judge the national non-public economic data.This article proposes a data virtualization application method and uses it to connect and utilize cross domain data resources.By logically virtualizing the multi-source heterogeneous non-public economic data accessed by the Federation of Industry and Commerce,constructing a logical space for the data,optimizing metadata queries through clustering algorithms,and proposing an optimization method based on Spark SQL distributed queries,implementing the Catalyst automatic caching strategy,using intermediate data structures,and other methods to improve data query efficiency and read performance,and making sure the accuracy of data at the same time to improve the utilization of data resources,promoting the effective utilization of the Federation of Industry and Commerce's data assets.
【Key words】:data virtualization;query engine;query optimization
0引言
全国工商联具有数据来源多样化、用户角色多、数据量巨大的特点,其数据从内、外部两个层面四个方向主要包括:全国工商联业务工作产生的数据,国家各部委提供的数据、第三方机构提供的数据和地方工商联组织及所属商会提供的数据,数据存储标准不统一。全国工商联的业务分析需要集成、查询和分析具有不同来源、不同结构、不同格式和不同访问方法的数据,采用数据虚拟化技术可以满足工商联数据集成接入与快速访问需求。
在数据虚拟化过程中,用户可自定义需求从不同的物理数据源获取数据,基于元数据关联组织模型,快速建立不同数据源之间的关联关系。针对非公经济数据的复杂性,提供数据虚拟化服务隐藏物理数据层的数据复杂性,并向面向不同数据用户的不同权限和需求,提供干净、融合的虚拟数据集。此外,在这种情况下,用户感觉不到数据迁移等底层物理数据存储重组变化,大大简化了数据访问和使用等操作。
本文提出一种面向非公经济的改进跨域数据虚拟化查询方法,利用数据虚拟化系统对工商联具有不同结构、不同格式和不同访问方法的数据逻辑虚拟化,构造一个数据的虚拟逻辑空间,不同用户组按照各自的访问授权,获得不同来源、不同所属机构的信息数据,完成多源异构数据的统一集成[1]。同时,基于Spark SQL分布式查询引擎,获得工商联跨域非公经济数据资源,实现查询性能的优化。
1数据虚拟化
1.1数据虚拟化
数据虚拟化主要应用于多源异构、多所有者的数据集,通过虚拟化这些多源异构、多所有者的数据资源,将数据的物理属性和逻辑属性完全区分开来,屏蔽数据存储的复杂技术过程等信息,突显数据的逻辑统一管理和使用,并为用户提供便利的访问接口,为数据应用需求提供数据资源整合的数据服务,实现数据即服务的目标。
用户在数据虚拟化应用中有两种数据获取方式,一种是数据已在缓存中即可使用;另一种是数据不在缓存中的情况下,需要通过元数据查找所需数据的详细信息,然后通过JDBC、JSON等接口获取所需数据,最终实现对数据资源的查询或修改。
数据虚拟化技术可支撑业务工作库的创建,支持根据业务需求选择所需的底层数据资源,自定义虚拟数据视图,实时创建业务工作库,隔离底层数据资源,为业务系统提供数据访问服务。在提取过程中,支持根据业务形态进行数据重组。权限是虚拟化处理需要解决的重要问题,在数据虚拟化系统中,数据用户访问虚拟数据的权限、原始数据源的访问授权是两个独立的权限设置,本文默认原始数据源的访问授权是对工商联用户完全开放的,实际上是由数据源所有者决定的访问权限。
结合全国工商联非公经济数据资源库业务逻辑架构和业务线数据流,数据虚拟化运行机制如图1所示。根据业务需求和数据交换需求,配置虚拟数据视图。虚拟数据视图可将不同格式的数据集虚拟成相同格式虚拟数据视图,保留原始数据并简化数据处理工作。在这个过程中,首先使用数据连接器功能接入数据资源,如图2所示。一个数据集能映射到多个不同的虚拟数据视图,而不会实际生成多个数据的物理副本,每个视图可以执行不同的数据转换逻辑,虚拟视图创建如图3所示,当用户应用程序通过虚拟数据对象访问数据时,虚拟数据对象将从物理底层数据库数据集获取数据,并根据嵌入的逻辑对转换数据进行重组和分拆。对于用户应用程序,这些虚拟数据对象看起来是不同的数据对象。这样不仅节省存储空间,还可节省读取时间,提高生产效率。同时,在这种情况下,用户感觉不到数据迁移等底层物理数据存储重组变化,大大简化了数据访问和使用等操作。
生成的数据虚拟视图可支撑工作库的建立,支持将数据虚拟视图固化为互相独立的业务工作库和对外交换库,例如按会员系统的个人会员、企业会员、商会系统的商会信息等形态组成多个主题,这些主题进入到业务应用系统对应的业务工作库中,进而支持系统开展业务工作;或按照外部组织机构的数据交换需要,为其提供相应的交换数据。
1.2虚拟化应用
查询效率是用户通过查询数据库能够得到自己所需数据的效率,也是数据虚拟化系统重要的性能指标。数据虚拟化系统几个常用的查询技术有Query Substitution、SQL Override、SQL Pushdown、ShipJoins、Distributed Joins、Parallel Processing等[2]。但都有一些局限性如Query Substitution用于嵌套虚拟表的查询应用;Ship Joins用于多种的数据源情况,SQL Pushdown对于底层数据为XML Web服务或序列文件[3]的情形不适用。其他一些如Cisco、Composite等企业利用其在该领域的优势地位对每个查询请求制定优化查询策略,从而保证目标数据及时快捷地交付。
本文在基于数据虚拟化技术的基础上,对各级工商联组织、商会、非公有制企业和个体等各类工商联组织机构信息数据进行集成。各种结构不同类型的数据资源分布在工商联各省市组织机构数据库中,数据虚拟化系统存储了元数据信息而非物理数据[4]。
对于工商联元数据描述采用JSON文件,该标准文件包括Name、Level、Source、Storage、Description和Parameter几个部分,每个字段对应含义为:Name代表元数据类型、Level代表可访问权限等级、Source代表元数据来源机构组织、Storage代表工商联数据的数据位置、Description代表元数据的相关信息、Parameter代表元数据其他说明。
在数据集成架构中当数据量达到一定程度时,元数据查询构成树形结构,需要根据相关指令逐级查询。我们判断数据集成方法是否优秀时,应用查询效率应该是一项重要功能指标[5]。当数据量增大时,查询对象的复杂度会大幅增长,导致查询时间也成倍增加。为此我们需要一种更加扁平的数据结构,尽量缩短查询路径提高查询效率。
本文采用的是K-means++算法,利用该算法将JSON文件分簇,从而实现元数据组织分簇。一般情况下K-means算法比较有效,但容易受到初始簇质心的影响,可能陷入局部最优值。为了避免K-means算法这个问题,我们使用K-means++聚类算法,该算法首先随机选取一个点作为第一个聚类中心;然后计算所有样本与第一个中心的距离,选出距离最大的点作为下一个聚类中心;迭代计算所有点到与之最近的聚类中心的距离,选出距离最大的点作为新的聚类中心,以此迭代,直至选出需要的K个点。
2分布式查询引擎
SparkSQL在查询引擎上采用Spark计算平台,Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,可以高性能地进行批量及流式处理。使用逻辑回归算法进行迭代计算,Spark比Hadoop的速度快出很多倍。在Spark SQL的缓存研究上,文献[6]设计采用混合存储模式,充分利用各存储介质的优势,并提出一种针对混合介质的成本效益模型,自动选择价值大的数据进行缓存,提升系统的查询性能。Spark SQL通过HDFS文件系统读取数据时,一般会进行全表扫描,对大规模的数据集来说,全表扫描操作往往是IO瓶颈。Cui等[7]通过一种细粒度的数据缓存机制,实现Spark SQL查询性能优化。在内存使用方面,Wang等[8]采用了GoldFish系统,该系统基于一种大规模并行处理的计算引擎,改变了内存的压缩机制和使用方式,大幅增强了SQL查询性能。
在Spark SQL中,通常使用uncacheTable()与cache Table()来释放或缓存数据。Spark SQL用列式内存存储格式进行表的缓存。然后Spark SQL就可以仅扫描需要使用的列,并且自动优化压缩,来最小化内存使用和垃圾回收开销。数据缓存的另一好处是降低了数据传输的开销,尤其是一些迭代查询和深度学习场景[9]。
Spark2.0中引入了基于代价的优化器(Cost-based Optimizer),简称CBO,通常由于统计信息的缺失以及统计信息的不准确,使其默认依据文件大小来预估表的大小,但是文件往往是压缩的,尤其是列存储格式,比如Parquet和Orc,而Spark是基于行处理,如果数据存在重复,File Size可能和真实的行存储的真实大小存在较大差异。
Catalyst作为Spark SQL的查询优化器,它负责SQL语句的解析、绑定、优化和根据逻辑执行计划生成物理执行计划等过程。SQL语句首先通过Parser模块被解析为一个抽象语法树,此棵树称为Unresolved Logical Plan,Unresolved Logical Plan通过Analyzer模块借助于Catalog中的表信息解析为Logical Plan,此时优化器再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan,优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,需要将此逻辑执行计划转换为物理计划,最后依据最优的物理执行计划,生成Java字节码,将SQL转化为DAG,以RDD形式进行操作。目前Spark SQL的缓存策略需要用户来指定,无法自动识别高价值的数据进行缓存,因此本文设计一种自动数据缓存策略,用来优化SQL查询的性能。
为了充分地合理利用Spark缓存M,在有限的空
上述参数S对应,表示对应数据表是否缓存处理,取值范围为0或者1。
M可以通过SparkSQL配置文件中spark.executor.memory、spark.memory.fraction spark.memory.storageFraction三个参数相乘得到。参数P{p1,p2,…pi},与上述n和s类似,是访问次数满足条件的数据表成本差值集合,其中pi表示数据表Di在不使用缓存与使用缓存之间的成本开销差如公式(1)所示,pi=Costdiff(Di),Costdiff(Di)表示一次SQL查询中,每个数据表在被读入缓存并使用时Costcache(Di)与不使用缓存时由数据源获取的成本Costuncache(Di)差值。由以下分析可以得出,由于读缓存时CPU的成本小于从数据源读取数据的成本,因此核心开销因素为数据表在查询中访问的次数。计算数据缓存策略参数说明如表1所示。
写缓存的成本包括从数据源读取数据的成本和CPU将数据缓存成列式存储的时间成本,如公式(4)所示:
Costwrite(Di)H row(Di)tableSizeDi
cpuwrite row(Di)tableSizeDi(4)
读取缓存的成本主要是列变行的CPU处理时间,如公式(5)所示:
Costread(Di)cpuread row(Di)tableSizeDi(5)
columnReadDi j/columnTotalDi
完成缓存成本评估后,在利用动态优化算法选择高价值可以缓存的数据表,调用Spark SQL中Cache立即将选中的数据表进行缓存。因此在Catalyst查询优化器前设计增加自动缓存功能,其主要包括统计模块、评估模块和优化模块。
(1)统计模块:用于对SQL语句进行解析,并计录SQL中访问各数据表的次数与每次访问所调用的列。输出访问次数大于等于3的数据表的相关信息。
(2)评估模块:评估上述访问统计信息在被预读取数据表并使用缓存时的成本与不使用缓存时由数据源直接获取的成本,进行成本评估。
(3)优化模块:实现缓存优化算法,计算在数据表集合中选择出一个或多个可以大幅降低成本开销的数据表,达到自动缓存高价值目标的目的,最后利用Cache API缓存选中的高价值数据表。
实现优化算法逻辑代码如下所示:
(1)//符合条件数据表的总数n,缓存空间大小M,缓存成本差统计数组p,容量数组s
(2)function getCacheTable(n,M,p,s){
(3)var preResults=[]
(4)var results=[]
(5)//填充边界值
(6)for(var i=0;i<n;i++){
(7)if(i<s[0]){
(8)preResults<i>=0
(9)}else{
(10)preResults<i>=p[0]
(11)}
(12)}
(13)//外层循环是符合条件数据表的总数,内层
循环是spark缓存上限
(14)for(var i=0;i<n;i++){
(15)for(varj=0;j<=M;j++){
(16)if(j<<i>){
(17)results[j]=preResults[j]
(18)}else{
(19)results[j]=Math.max(preResults[j],preResults[j-s<i>]+p<i>)
(20)}
(21)}
(22)preResults=results
(23)}
(24)return results
(25)}
3中间数据结构
由于数据库算子中间数据结构也会影响分布式查询引擎查询过程的效率。中间数据结构如图4可以表示为两部分,行列关系可以对应构建逻辑上的行表。实际上应用键值对(Row/Val)来表示列数据集合的方式比较普遍,其中Row为行号,Val为元组值。
在列数据中间结构中,我们为方便查询索引引入哈希表功能。本次的中间数据结构由以下部分构成:第一部分存储元数据对应相应的数据。第二部分存储实际的列数据,本文中每个元组占用144bits的内存区域,其中高16bits用于标识指示,描述数据的相关信息,中间的32bits存储Row Id,存储实际数据区域用剩余96bits。利用连续的内存区域存储,可大幅提升内存利用率。最后一部分为哈希表,为方便查询引入,可由行号索引到数据区偏移量。哈希表可用于定长和不定长两种数据类型,该结构对定长数据类型,利用物理连续内存即可存储其值,对可变长数据类型则单独启用一块连续的内存Heap进行管理。
中间数据结构对可变长字符串类型处理如图5所示,通过地址偏移量Offset和一块连续的内存管理区,将可变长类型的向量由两个向量来具体对应。由可变长数据类型的数据结构与定长类型的数据结构相比较可以看出,可变长类型中存在额外划出一块内存区域Heap来存储变长向量,数据区存储的是变长数据在该额外内存区域中的Offset偏移量。当查询通过Row Id找到存储区的Offset偏移量时,在内存区域Heap中通过Offset偏移量将字符串取出,最终查到元组值。
按照向量的形式将数据存放在连续的内存地址中,带来好处如下:
(1)连续地址的存储方便序列化,其时间性能友好。
(2)在存储区域上内存分配是连续的区域,对比Row/Val键值对的稀疏存储结构,有效提高了内存利用率。
(3)向量形式存储结构支持CPU加速流水处理,提高效率;同时还可以进一步的压缩优化,降低内存的使用率。
总之,设计中间数据结构实际上兼顾键值对应用方式,实际上是加入了查询优化的设计。
4系统优化验证
针对以上查询优化设计,本次验证的集群操作系统使用的是CentOS7.6,并行软件包括:Spark2.2,硬件参数:CPU核数4,内存容量16GB,硬盘容量2TB,节点数目6。采用TPC-DS作为测试数据集。
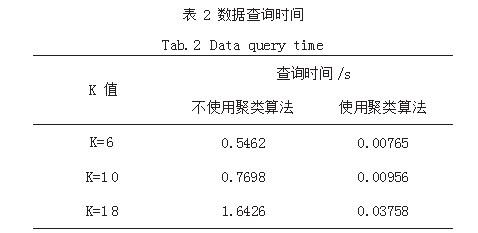
通过对元数据实施聚类分簇算法,兼容了工商联数据多源的特性,是否实施聚类分簇算法对数据集成方法的性能影响,如表2所示,显示了优化算法前后对某地方工商联的数据查询时间。
根据表2的时间结果,通过采用聚类算法,有效优化了数据的查询时间。基于数据虚拟化的集成方法通过利用元数据聚类方式达到了理想的数据访问效果,成功解决了工商联多元数据集成的性能和实用性问题。
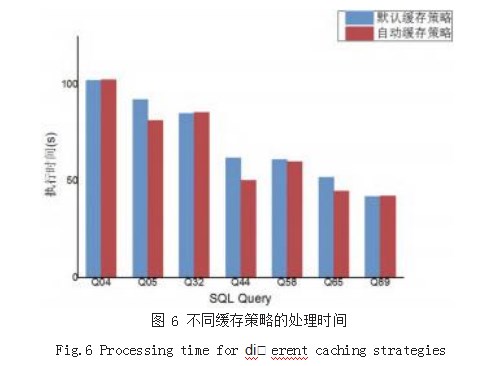
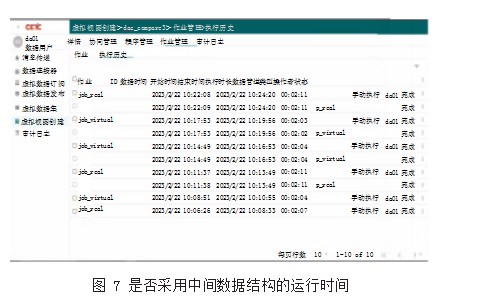
本文填加的自动缓存策略与默认策略性能的对比选用30GB的TPC-DS数据,选取其中7组Q04、Q05、Q32、Q44、Q58、Q65、Q89作为验证查询数据,每条SQL语句在实验环境上执行3次,取平均执行时间对比如图6所示,本文提出的自动缓存策略查询结果基本优于Spark SQL默认缓存策略。再是否使用算子中间数据结构的对比执行时间如图7所示,job_real表示不采用,job_ virtual表示采用中间数据结构。
5结语
本文针对全国工商联非公经济数据资源统一访问需要,基于数据虚拟化及Spark SQL查询引擎优化,提出一种数据查询优化方法,依托数据虚拟化系统,支持全国工商联多源数据的统一访问和使用。提供底层数据的集成展现能力,并通过统一的接口对外服务,减少数据虚拟化带来的系统开销,支持授权的用户或组织以一Fig.7 Runtimewith orwithout an intermediate data structure种安全的方式来集成并共享结构化或半结构化数据,提升数据查询访问性能,在保证数据准确性的同时进一步提高工商联数据资源的利用率并挖掘潜在的数据价值。
参考文献
[1]罗伟雄,时东晓,刘岚,等.数据虚拟化平台的设计与实现[J].计算机应用,2017(A2):225-228.
[2]赵国峰,葛丹凤.数据虚拟化研究综述[J].重庆邮电大学学报,2016,28(04):494-502.
[3]TELETIA N,HALVERSON A D,BLAKELEY J A,et al.Performing Parallel Joins on Distributed Database Data:US,US201113154911[P].2012-12-13.
[4]葛丹凤.多源异构的网络感知信息的元数据组织方法研究[D].重庆:重庆邮电大学,2017.
[5]BACHTARZI C,BACHTARZI F,BENCHIKHA F.A Model-driven Approach for Materialized Views Definition over Heterogeneous Databases[C]//2015 1st International Conference on New Technologies of Information and Communication(NTIC),2015:1-5.
[6]曾丹.基于收益模型的Spark SQL数据重用机制[D].北京:中国科学院大学,2016.
[7]CUI Y,LI G Q,CHENG H,et al.Indexing for Large Scale Data Querying Based on Spark SQL[C]//International Conference on E-Business Engineering.Shanghai:IEEE,2017:103-108.
[8]WANG J,DUAN H C,MIN G Y,et al.Goldfish:In-memory Massive Parallel Processing SQL Engine Based on Columnar Store[C]//IEEE International Conference on Internet of Things.Exeter:IEEE,2017:142-149.
[9]连欣.基于成本的Spark SQL优化[D].重庆:重庆邮电大学,2018.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/63369.html