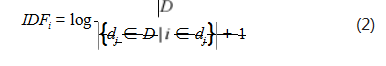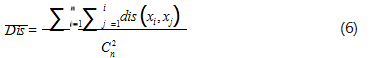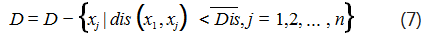SCI论文(www.lunwensci.com)
摘 要:数据挖掘技术是利用计算机强大的计算能力来代替部分人工分析的一项技术。传统的数据分析是人们利用自己的 大脑对数据进行分析、思考和解读,但人脑所能承载的计算量是有限的。目前,计算机强大的计算能力代替了人脑,它们不仅 可以处理一些不需要自主思考的增删改查类工作,有时还可以担任一些需要自我学习能力的任务,比如对网页数据进行高质量 分析与挖掘。为了进一步探究网页数据分析与挖掘,本文提出了一种基于优化样本距离计算方法,从而改进了 K-means 算法 的聚类中心计算方法。具体来说,本文获取常见电商页面“当当网”公开的以“手机”为关键词的近 12000 条数据,使用文本 挖掘技术对其进行数据挖掘,对数据的文本信息进行清洗、中文分词以及关键词权重计算等全面预处理,最终使用聚类中心优 化的 K-means 算法,挖掘看似毫无关联的数据集中的隐藏信息为电商用户提供市场导向。
关键词: 电商页面,数据挖掘,数据预处理,中文文本聚类
Analysis and Mining of E-commerce Page Data Based on Improved K-means
YE Hao1. MIAO Yiheng2. ZHANG Hongjun3.4
(1. School of Modern Posts, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003;
2. School of Communications and Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003; 3. China Communications Services Co., Ltd., Beijing 100005;
4. School of Internet of Things, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210003)
【Abstract】: Data mining technology is a technique that utilizes the powerful computing power of computers to replace some manual analysis. Traditional data analysis involves people using their own brains to analyze, think and interpret data, but the amount of computation that the human brain can carry is limited . At present, the powerful computing power of computers has replaced the human brain. They can not only handle tasks such as adding, deleting, modifying, and searching that do not require independent thinking, but also sometimes perform tasks that require self-learning ability, such as high-quality analysis and mining of web data. In order to further explore web data analysis and mining, this article proposes a clustering center calculation method based on optimized sample distance, thereby improving the K-means algorithm. Specifically, this article obtained nearly 12000 pieces of data publicly available on the common e-commerce page "Dangdang.com" with the keyword "mobile phone". Text mining technology was used to mine the data, which underwent comprehensive preprocessing such as text information cleaning, Chinese word segmentation, and keyword weight calculation . Finally, the K-means algorithm optimized by the clustering center was used, mining hidden information in seemingly unrelated datasets to provide market orientation for e-commerce users.
【Key words】: e-commerce page;data mining;data preprocessing;Chinese text clustering
1 引言
1.1 研究背景及意义
现在社会已经进入了数据时代,大多数企业信奉的 都是 “数据主义”[1]。随着电子商务的发展和网上消费 活动的增加,电子商务平台每天产生数据是非常巨大 的。但是如何挖掘这些隐藏在海量数据下有价值的数据 还需要不断优化的聚类算法对数据进行进一步处理 [2]。 作为当今信息最主要的载体,体量可观的网络资源值得 我们探究其更好的利用办法。在众多方法中,发挥关键 作用的聚类算法无疑是绕不开的话题。现在大数据处理 方面,已经有传统的基于物品的协同过滤算法可以对爬 取的数据进行分析从而得出比较准确的数据,有些行业 先行者更是提出了基于标签的物品推荐算法 [3]。当然, 该领域的发展也未曾到顶。如果将现有基于标签的物品 聚类算法与基于用户需求的物品聚类算法结合,并不断 优化算法的运行效率与准确性,我们将会得到既可以服 务于电商,又可以服务于电商用户的新兴算法。
本文通过对电商网页信息数据进行关键词权值计 算,优化基于用户与产品的聚类算法。希望对电子商务 平台提供一些关于营销策略的指导,将有助于指导电 子商务公司做出正确的营销决策,在运营中节约相关成 本,从而提高其在电子商务市场中的相对竞争力,推动 电商行业的健康发展。
1.2 研究内容及特点
本文要做的是关于文本和数值型数据的探究性分 析,需要明确数据挖掘的一般流程,如图 1 所示。首先 应该获取所需要的数据集,然后对获取的数据进行基本 的处理,接着利用特征工程找到有价值的信息,最后利 用合适的算法对数据进行相应的分析。下面详细介绍本 文在以上四个步骤中的详细内容 [4]。
数据获取阶段,本文主要以爬取的某一词语为关键 字的“当当网”的电商页面信息为主。通过使用 Python 提供的一个可以处理高并发的 Scrapy 框架来快速的爬 取网站相应页面的内容,本文使用的关键词为“XX 手 机”,并计划引用公开数据集近 12000 条数据,每条数 据包括商品名称、链接地址、价格、销量以及评论数, 并使用关系型数据库 MySQL 将这些数据进行存储以便 后期的调用。接着通过使用多种数据清洗和探索技术来 对数据库中的数据进行基本的处理,并通过可视化工具 直观立体的展示数据之间的浅层关系。对于爬取到的文 本型数据,本文利用相应的数据清洗的方法对数据进行 清洗,然后利用特征工程找出文本信息中可以利用的相 关特征,本文主要利用 Jieba 分词工具和 TF-IDF 算法使得文本信息转化为空间向量模型,然后探索各特征之 间的关系 [5]。最后对于商品的 Title 与价格,采取“无 监督学习”中的经典聚类方法 K-means 算法对中文文 本进行聚类,分析并挖掘出其中隐藏的相关价值。
2 网页数据预处理
2.1 描述性分析
本文所涉及的电商网页数据可以分为两部分:商品 本身的属性和所属店铺的信息,我们首先对其进行简单 的描述性分析。
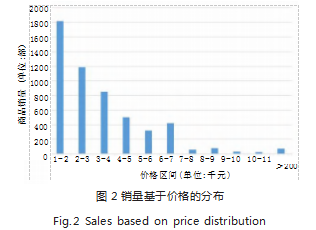
如图 2 所示, 我们将商品价格分成几个大的价格区 间,然后统计各个价格区间的总的商品销量,可以直 观看出,消费者选择购买的手机类商品价格适中,其 中 2000-3000 元之间的商品销量占绝大部分,当手机价 格超过 6000 元之后, 销量明显下降。可以看出价格越 高,销量越低,手机类商品的价格与销量成反比。当然 0-2000 元之所以销量多,很可能是因为当当网算法问 题,把大量手机配件也囊括在内了。
2.2 数据的清洗
2.2.1 数据清洗概述
在数据挖掘前期过程中有一个及其重要的步骤,即 数据清洗 [6]。由于爬取到的信息有大量的垃圾内容及噪 声,因此我们需要对数据进行“清洗”,即遵照既定规则,在不破坏数据代表性的前提下,去除残缺数据等不 洁净的数据。
数据清洗的步骤 [6.7]:
(1) 缺失值处理(通过 Describe 与 Len 函数可以 直接发现,在某种情况下也可以通过为 0 的数据发现)。
处理方法有:删除、插补、不处理,其中插补的方 法主要有:均值插补、中位数插补、众数插补等。
(2) 异常值处理(一般通过散点图来发现, 位于主 体分布较远的点一般视为异常点)。
处理方法:视异常值为缺失值、删除、修补或者不 处理等。
2.2.2 中位数插值法
使用 Pandas 和 NumPy 包, 读取待处理数据,Python 导入数据代码如表 1 所示。
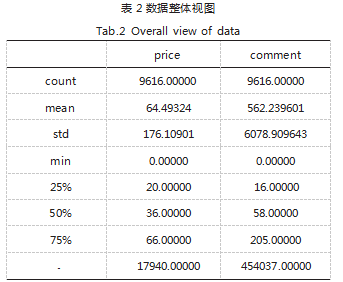
从表 2 可以看出价格和评论数的总体信息, 其中有 平均值、方差、最大值、最小值、1/4 分位数、50% 分 位数等信息。以下我们采用 50% 这一中位数进行数据 清洗。至于为什么不选择平均数进行数据清洗,原因主 要是因为我们所爬取的数据量非常小,总计 12000 多条 数据,这时很可能受一些异常值的影响,导致数据的平均 数不精确。因此我们选择采用中位数来进行数据清洗。
使用 matplotlib.pyplot 模块来画散点图, 其中以 价格为横轴,评论数为纵轴,结果如图 3 所示。我们可以看到价格总体主要在 2000-5500 之间,评论数总体 主要在 0-1500 之间,其余地方有异常点,我们可以将 这些异常点进行相应的处理,使得它们归于总体数据区 间,不影响数据分析的精确性。从数据的整体视图中我们发现价格的最小值有 0. 根据现实情形可以看出这一数据为异常值,由此,采用 中位数插值法来清洗一下数据,将评论数大于 300 以及 商品价格大于 3500 的商品归一化到 50% 这一中位数的 位置,即将评论数大于 10000 的商品评论数手动设置为 评论数的 50% 中位数 58.将价格大于 200 的商品价格 手动设置为 36.实现代码如表 3 所示。
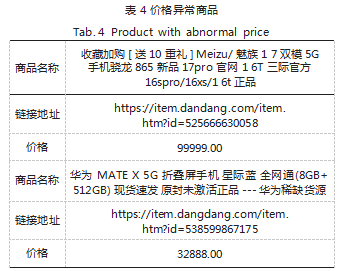
我们对于超出总体数据范围的数据进行中位数插值 法进行清洗,并输出那些被清洗掉的数据,如表 4 所 示,可以发现这些异常点并非爬虫爬取错误,而是这些 商品本身就是这个价格。
同时我们也打印出评论数异常的商品,如表 5 所 示。经检查发现也并非爬虫爬取的错误信息,而是商品 本身的评论总数就是那么低(高)。
经过中位数插值法处理后,将异常值归一到中位数 位置,画出的散点图如图 4 所示。
2.3 中文分词处理
2.3.1 Jieba 中文分词
中文文本与英文文本在处理时的步骤不太一样,由 于英文文本都是由一个一个的英文单词组成,所以英文 文本不需要进行分词处理就可以将文本转化成词频矩 阵,但是对于中文文本来说,由于中文一句话是连在一 起的,所以在转化成词频矩阵之前需要对中文文本进行分词处理。本文选用的是针对中文分词 Jieba 库 [8]。
所谓结巴分词,其实是一种基于动态规划的偏重于 前缀词典的复合词词典分词方法。其工作流程大致如 下:首先,设置一个统计词典,记录常见词在语段中不 同成分的词频; 其次,由统计词典得到一个前缀词典; 然后,实现分词的重要环节 ——切分,此环节也需要前 缀词典的支持;从而,将具象的数据转化为抽象的有向 无环图;最后,利用常见的动态规划算法,计算该有向 无环图的最大概率路径。最终切分形式,自然呼之欲出。
由于爬取的文本信息为店铺所展示的商品信息,其 中包括大量噪声,包括特殊符号“【”,“】”等,其中 还要一些广告语,包括“全面屏”“256GB”等,经过 Jieba 分词器分词,剔除毫无意义的词语以及符号之后, 文本被分成若干个关键字,如表 6 所示。由于自定义了 停用词和字典,可以看出分词的效果较好。
2.3.2 自定义停用词和字典分词结果
在使用 Jieba 工具分词之后,并不是所有的词对于 文本聚类都有用, Jieba 分词器提供了导入停用词的功 能。本文在网络上寻找了一些停用词表,经实际测试, 结果并不理想。因为数据是手机类的文本信息,一些 Jieba 分词器自带的停用词之外的会大量出现,并且毫 无意义,例如“爆款”“新款”等。此外,因为电商平 台自身算法原因,可能有大量目标产品的配件会误入数 据集,比如“手机壳”。于是我们构造了一个适合手机 类文本数据的停用词表,命名为 stop_words.txt,将一 些容易出现并且对于分类好用处的词进行过滤。
导入自定义停用词表的代码如下:
def stopwordslist(filepath):
stopwords = [line .strip() for line in open (filepath, "r").readlines()]
return stopwords
def seg_sentence(sentence):
jieba.load_userdict("dict.txt")
sentence_seged = jieba .cut(sentence .strip(),
cut_all=False)
stopwords = stopwordslist("stop_words.txt") outstr = ""
for word in sentence_seged:
if word not in stopwords:
if word != "\t"
outstr += word
outstr += ""
return outstr
Jieba 分词器默认的字典对于手机类文本数据的处 理也不太精确,例如将“苹果 iPhone”划分为“苹果” 和“iPhone”,将原本为手机的词语划分开将会影响聚 类的效果,由此需要自定义字典,命名为 dict.txt,如 图 5 所示。
导入自定义字典的代码如下:
jieba.load_userdict("dict.txt")
2.4 关键词权重计算
2.4.1 TE-IDF 算法公式
在完成了数据的清洗后,数据集仍然需要根据实验 或者用户的需要分出主次影响因子,即各个词语的权 重。若要满足信息检索对文档中词语的分级,单一地依 靠词频构造算法也是不足的。这就需要一种结合词频和 逆文档频率的高效算法,如 TF-IDF[8]。该算法主要思 想是将目标与会的词频和逆文档率向量化,用他们的向 量积来衡量该词汇在文档中的权重。该算法的详细介绍 在参考文献 [9-10] 中有详细介绍,读者也可自行参考阅 读。以下将介绍 TF-IDF 算法的计算公式。
(1)TF(词频的计算)如式(1)所示:
其中, i 为关键词例,是关键词 i 在文档j 中出现的 频数, n(k,j) 为文档j 中设计关键词总数。
(2) IDF (逆文档频率的计算)如式(2)所示 :
其中, |D| 为语料库中文件总数,{dj ∈ D | i ∈ dj } 表示包含词语 i 的文档数目。如果该词语不在语料库中,则会 导致分母为零,因此一般情况下使用{dj ∈ D | i ∈ dj }+ 1.
(3) TF-IDF(词频 - 逆文档频率的计算)如式(3) 所示 [11]:
2.4.2 权值计算结果
由 2.3 节可知,我们在完成数据的除杂后,相应的 聚类算法会通过计算出的文本相似度进行聚类分析。关 于文本的标签特征向量的提取,本文采用了 TF-IDF 中 的思想,将每个文本转化为词频矩阵,计算它们之间 的余弦相似度 [12-14]。对于该步骤, Python 提供了第 三方库可以方便快速的计算词频矩阵,其中就使用到 CountVectorizer() 函 数 和 TfidfTransformer() 函 数。 CountVectorizer() 用于统计并输出反应各词汇词频的 词 频 矩 阵, 而 TfidfTransformer() 则 是 TF-IDF 算 法 主要功能的实现函数,兼具对词频和逆文档频率(即其 他训练集的词频)的考量,从而得到更具置信度的权重 矩阵。由此显然易得,训练文本的多寡影响着两个函数 之间的相对性能差距。
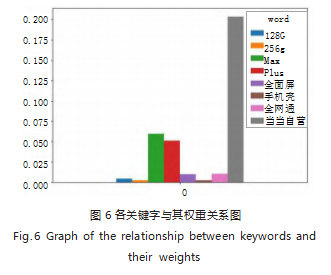
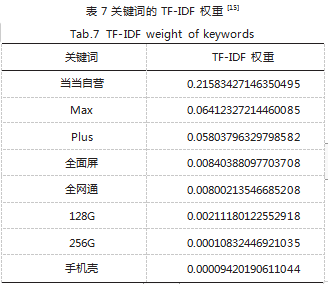
使用 Jieba 分词器可以打印权输出值最大的前 50 个关键词,以下给出前 8 个关键词(如图 6 所示)以 及其 TF-IDF 权值,结果如表 7 所示。从表中可以看出 该 10 个关键词在手机类商品的权重很大,可以很好地 显示各个文本所侧重展示的信息。其中“当当自营”的 权重最大,即手机类商品中当当自营的店铺商品占了很 大的比例,可见当当网自营店铺在吸引消费者方面有所 造诣,可能是由于其快捷的物流、高质量的商品决定 的。其中,“Max”“Plus”为形容手机机型的词语,之 所以它们的权重如此之高,是因为在所爬取的手机类商 品文本信息中,很大一部分商品信息中都包含有这一类 机型的形容词,这些大屏手机商品自然也是受消费者喜 爱的,所以它们的权重高也不足为奇。“全面屏”“全 网通”也是形容手机外观、性能的词语,但是占比不 高,可能是因为现在大部分手机都可以做到这两点。 “128G”“256G”占比较小,一方面是因为大部分店铺的 商品 Title 里很少写明商品内存,因为手机内存一般都是 下单页面的选项,很少有售卖单种内存容量手机的店铺; 另一方面,他们是唯二进入前八的形容手机内存容量的 关键词,也反映了当代消费者对大容量手机的偏爱。
3 网页数据聚类应用
通过数据探索的描述性分析之后,我们已经看到了 当当网手机类商品信息表面的一部分价值 [15] ,但我们所爬取的数据里有很大一部分是文本信息,下面我们通 过聚类方法对文本信息进行挖掘分析。
3.1 文本聚类分析
3.1.1 K-means 聚类方法
算法流程如图 7 所示, 在聚类问题中,我们的训练 样本为 x(1),x(2), … ,x(m) ,其中每个 x(i) ∈ Rn ,由于为非监督 性学习的聚类问题,所以该类问题并没有标签值 y[16-21]。
K-means 算法的具体描述如下:
其中, k 是我们事先指定好的聚类数, C(i) 为实例 i 与 k 个类中距离最近的那个类,即 C(i) 的值为 1 ~ k 的 某个数。质心 μj 代表这个簇中的所有点的均值。在该算 法的第一步中,随机选取 k 个对象作为初始聚类的中心 点。在以后的每次迭代中,本文对 K-means 算法聚类 中心的选择提出一定的约束,确保聚类中心位于数据密 集区域 [22-26]。
算法根据每个实例到各个聚类中心的距离将每个实 例重新划分到与自身距离最近的聚类中。当遍历完所有 实例后,代表完成一次迭代,重新计算新的聚类中心。 然后以新的聚类中心为基准重新遍历所有实例,重复以 上步骤,直到在某次迭代前后聚类中心没有发生变化或 者变化差值小于给定的一个阈值时,可以认为该算法已 经收敛。
K-means 算法的代价函数如式(4)所示:
从上面可以看出, K-means 算法有优点,同时也具 有许多缺点。优点是该算法速度快,计算简单,只需要 计算空间点之间的距离即可,不需要计算许多过于复杂 的公式。缺点是最终结果和初始点的选择十分相关,容 易陷入局部最优解。那么应该如何避免陷入局部最优解 呢?答案是尝试多次随机初始化,以下为具体做法 [27]:
for i=1 to 100:
随机初始化 k 来进行 K-means 算法;
;
最后在这 100 种分类数据方法中选取代价函数最小 的一个。
3.1.2 聚类中心选择优化
为了进一步避免聚类陷入局部最优解的新方法,本 文使用了一种优化的样本距离计算方法,避免将局部密 集中心选为聚类中心 [28]。
具体步骤如下:令 D 为数据集,
S1:确定 k 个聚类中心
(1)求出各个样本间距离平均值 Dis, 如式(6)所示:
其中, dis(xi,xj) 为样本 xi 与样本 xj 之间的欧式距离, n 为样本总个数。
(2)在数据集中找到一个符合 dis(xi,xc)< Dis 的数 据样本 xc ,其中 1
(3)已经确定为聚类中心的数据样本将不再参与聚类中心的选择,如式(7)所示:
(4) 重复(2) 和(3) 步骤, 找到第 k 个聚类中心 即停止。
S2:继续执行前文所述的 K-means 算法步骤进行 聚类分析。
3.2 聚类结果与分析
在上文中的数据清洗阶段我们已经利用中位数插值 法将商品价格归一化到 2000-10000 元钱之间,将评论 数归一化到 100 ~ 1100 条数据之间。下面对清洗过后 的数据进行 K-means 聚类,并画出相应的图形进行显示。
首先导入相应的包,如表 8 所示。
接着读取相应的文件,并且利用切片功能取出价格 和评论数这两列数据,如表 9 所示。
然后利用 K-means 方法对数据进行聚类,如表 10 所示。
最后使用 Fit 方法计算给定数据(这里为 X_train) 的方差,并利用 Matplotlib 返回一个实例化对象。
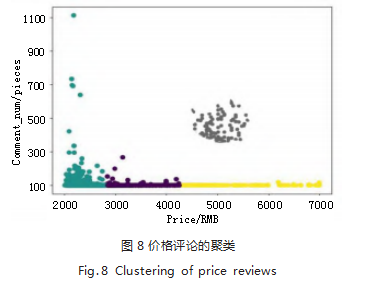
做出的图如图 8 所示。从中可以看出该算法根据评 论数将所有商品分为了 4 类,并且由于评论数与销量成正相关,总体上可以区分出销量的分布。评论数在 300- 500 的之间的商品数量较多, 100-300 商品其次,而评 论数在 900 以上的商品在本次爬取的数据中占比最少。 查找相关资料,得知当当网的评论数如果评论日期太 早,店铺的页面会将此条评论数删除,即此次爬取的评 论数并非店铺自开店以来的全部评论数,而是近期一个 月或者三个月的评论数,这样就不难解释图片中的情 形,因为如果手机这种耐用品想要在短短一个季度里 获得将近 1000 条评论数是非常困难的, 所以评论数在 700 以上的商品数相对来说比较少是符合常理的。
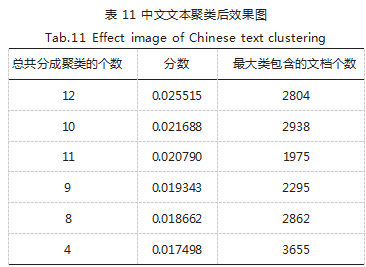
上述分析我们得到了各个关键词的权重,下面就可 以根据它们各自的权重来进行文本聚类。由于 K-means 聚类属于无监督性学习,即没有训练数据,没有标签, 我们一开始无法确定需要聚成的簇的个数为多少合适, 因此我们遍历 K 的值,使其从 2-12 依次执行聚类分析, 打印输出每一次聚类总共分成的聚类个数、各次聚类的 分数以及每次聚类中最大簇类所包含的文档的个数,如 表 11 所示。
4 结语
在众多的无监督聚类算法中, K-means 属于较为 简单的一类。但是对于聚类结果的质量评估,尤其是针 对相对无监督的算法,业内一直没有明确的结论。本文 查看大量参考文献,发现大多数实验或者工程都是基于 作者事先已经大致知道的合适的聚类个数,并且都有相 应的测试集来进行对比。所以在聚类算法的选择上,本 文还有更好的选择,例如高斯混合模型(GMM),但是 相比于 K-means 来说, GMM 算法每进行一次循环所 需要的计算量比较大,同时 GMM 的求解算法基于 EM 算法,因为该算法与 K-means 算法一样,初始值的选 取都是随机的,因此该算法有可能会解得局部的最优 解,而非全局最优解 [29]。由此可以看出,K-means 算 法和 GMM 算法都有一个超参数 k,该超参数的选取对 于算法的效果有着一定的影响 [30]。由此, 我们在未来 的研究中也可以考虑层次聚类。
本文进行的是探究性分析,没有设定准确的聚类数 目,也没有测试集可以进行对比,所以上文进行的探究 性分析或许存在不足之处,可进行指正。在后续的研究 中,会在自然语言处理方面做更加深入的研究,可以爬 取电商主页下面用户的评论内容,基于这些文本做情感 分析 [31] ,并且结合推荐系统向消费者提出建设性建议。 对于本文并未抓取的图片型数据,在后续研究中将重点 研究基于标签的推荐算法,更加直观地分析不同关键字 对消费者的影响,应该可以挖掘出较多有价值的信息。
参考文献
[1] 张静波 .大数据时代的数据素养教育[J].科学,2013.65(4): 29-32.
[2] 丁欣宇 . 电子商务网站设计中信息安全防御[J]. 中国新通信, 2022.24(2):135-136.
[3] DEEPA N,PHAM Q V,NGUYEN D C,et al.A Survey on Blockchain for Big Data:approaches,Opportunities, and Future Directions[J].Future Generation Computer Systems, 2022.
[4] 李雨欣,张桓森 .拼团购物电商平台发展现状与对策 —— 以 拼多多为例[J].商场现代化,2022(1):24-26.
[5] ZHANG C,STEPHENS M L,LAMBERT M F,et al . Acoustic Signal Classification by Support Vector Machine for Pipe Crack Early Warning in Smart Water Networks[J].Journal of Water Resources Planning and Management,2022.148(7):04022035.
[6] SHAH M,KOTHARI A,PATEL S .A Comprehensive Survey on Energy Consumption Analysis for NoSQL[J].Scalable Computing:Practice and Experience,2022.23 (1):35-50.
[7] NEUTATZ F,CHEN B,ALKHATIB Y,et al.Data Cleaning and AutoML:Would an optimizer choose to clean?[J]. Datenbank-Spektrum,2022:1-10.
[8] 吕博庆.基于爬虫与数据挖掘的电商页面信息分析[D].甘肃: 兰州大学,2018.
[9] 赵延平,王芳,夏杨.基于支持向量机的短文本分类方法[J].计 算机与现代化,2022(2):92-96.
[10] UDDIN M P,MAMUN M A,AFJAL M I,et al . I n fo r m a t i o n -Theoretic Feature Selection with Segmentation-Based Folded Principal Component Analysis(PCA) for Hyperspectral Image Classification[J]. International Journal of Remote Sensing,2021.42(1):286- 321.
[11] ZHONG Q Y,QIAN Q,FU Y F,et al.Survey of Particle Swarm Optimization Algorithm for Association Rule Mining[J].Journal of Frontiers of Computer Science & Technology,2021.15(5):777.
[12] BARBERÁ P,BOYDSTUN A E,LINN S,et al.Automated Text Classification of News Aarticles:A Practical Guide[J]. Political Analysis,2021.29(1):19-42.
[13] WIRZ S,SEIDENSTICKER S,SHTRICHMAN R.Patient-Controlled Analgesia (PCA): Intravenous Administration (IV-PCA) Versus Oral Administration (Oral-PCA) by Using a Novel Device (PCoA® Acute) for Hospitalized Patients with Acute Postoperative Pain—A Comparative Retrospective Study[J].Pain Research and Management, 2021:1-11.
[14] 邹春杰,赵学健,朱涛,等 .基于微服务架构的农产品溯源系 统优化[J].计算机技术与发展,2022.32(1):147-153.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/63067.html