SCI论文(www.lunwensci.com)
摘 要:在计算机使用设备的硬件技术发展过程当中,功能日渐增强,存储数据种类数量不断增加,其数据能够快速准确 的展现出图形,以便于用户使用结合 Lucene 搜索引擎算法突出使用设备数据显示,因此可以提出面向使用设备的 Lucene 算 法借鉴,用于数据搜索引擎应用。
Algorithm Research for Lucene Search Engine
ZHU Yanfang, ZHAO Lei, WANG Qi
(Jinan Water Service Center, Jinan Shandong 250000)
【Abstract】: In the process of hardware technology development of equipment used by computers, the functions are increasingly enhanced, the number of stored data types is increasing, and its data can quickly and accurately display graphics, so that users can use the Lucene search engine algorithm to highlight the use of equipment data display. Therefore, we can propose a device oriented Lucene algorithm for reference for data search engine applications.
【Key words】:Lucene algorithm;search engines;use equipment
随着互联网海量数据发展过程的进步,目录式搜索 引擎以及谷歌、百度的第二代计算机搜索引擎在技术上 得以快速发展,并取得巨大成功。可见,网络搜索引擎 作为网络资源应用的主要手段,逐步引向于终端设备的 引用。随着计算机储存数据数量的增加,桌面搜索引擎 发展迅速, 同样 Google Desktop MSN 搜索、雅虎桌 面搜索相继出现,可见搜索引擎在 PC 机方面应用逐步 扩展。对于用户而言,能够通过搜索引擎快速精准的找 到所需信息,而对于开发者而言,搜索引擎除了可以在 计算机 PC 端搜索之外,软件使用更加便捷灵活。
1 Lucene 算法分析
1.1 概述
Lucene 算法主要借助于 Java 语言开发全文检索算 法作为 A Pach 基金会下的开源子项目,以点 JAR 包的 形式为开发者使用。满足全文搜索需求基于其他语言实 现的 Lucien 算法,主要是形成了 C++ 语言的 Clucene 基于检索算法, Lucene 算法主要是建立储存倒排索引,针对特定检索对象实现快速检索 [1]。就复杂程度而言, 路线算法是增加空间开销换取时间,快捷路线,算法架 构设计良好、性能稳定,明确工作流程,检索格式目标 化,分词解析、用户查询建立索引检索,结果实现以及 存储操作各部分流程明确。
1.2 Lucene 算法索引文件结构、格式及索引过程
Lucene 不是指文件或一个网页搜索引擎, Web 站点 建议使用复杂的 Java 程序去搜索网页, 专注于索引和搜 索并且提供复杂搜索的详尽信息, 用户可以通过再操作区 域搜索需要的信息,获取隐藏索引,并结合 Lucene 功能 复杂的 API 在应用接口使用 Redex, 通过结构基本指 数实现反向索引,其中的索引基本结构反向索引作为研 究对象建立了一个数据结构文档抽取索引项。
每个索引下的关注点都留下一个文档序列,索引为 每个文档都含有一个关键词。可见反向索引并不是文档 包含哪些单词, Lucene 搜索指数是由一系列的成分组 成的,所有这些构成部分都是完整的分指数,从而促使搜索会将一个类似于数据库中的电子表格一样的目录创 建成数据库中的详细列表,按照文档列表中的位元序列 排列 [2]。以此构建成域,以作为项的序列,成为数据表 当中的元素数据值,序列项的数值构成字符串,在这些 不同的区域中,当一个文本串表示某项时,使用一个文 本串代表项,其中第一个字符串就是域名,第二个是域 名的字串。
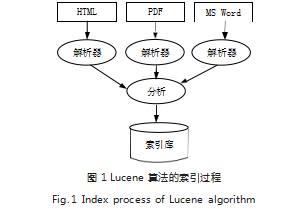
Lucene 内的域名信息由词典、连接文件和方位文 件组成。索引是由 3 个不同的段落组成的,这里的数据 被转换成文本分析,并在词组分析过程中保存形成数据 库。首先,被数据转化为纯文本信息,并可以借助于解 析器转化提取形成 HTML、PDF 文件格式,或者转化 为 DOC 的文件以扩大用户使用文件和资料的格式类型 (如图 1 所示)。分析文本作为文章的分析师,同时通过 Lucene 的资料计算的数据和分析性文字的进程选中单 元格档,然后进行分割转化,结果会在分析完成后存储 在数据库中以作为索引展示出来, Lucene 算法可以将 其中输入的数据,利用反向索引存储下来,以便于用户 搜索时快速展现出来,并储存其数据结构。
1.3 Lucene 算法体系架构
Lucene 算法整体架构(如图 2 所示)包含有查询 语言、查询结果索引、文件被索引、文件对外接口索 引、核心基础结构封装等,每个模块与 Lucene 源代码 的 Java 包对应各模块对应的名功能如下。
(1) org. Apache Lucene Analysis 模块。搜寻备份 文件的英语文本,如文字、标点、空格和分词,甚至连演 算法都无法用中文进行排序。因此,org. Apache Lucene Analysis 模块扩展时,为了实现对中文的分词,根据 搜索结果建立一个索引的插件,在检索模块输入查找信 息关键词,以便于索引模块根据分词结果形成插件以构 建索引。
(2) org. Apache Lucene Index 模块。多数与 org。Apache Lucene Analysis 模块的搜索结果形成倒排索 引,采用更好的解法指数的逆向索引有关。Lucene 终 端模组具有特殊的功能,即组合输出结果以创建字典文 件。记录关键词位于哪个文档当中,明确各文档的总 数,关键词所在文档的总数。列出可存储的关键词数量 和全部输出,形成了抽象数据结构图,记录各个字符串 所引体当中所在位置。Lucene 在建立索引文件,通过 优化方案体现在数据压缩存储方面。
(3)org. Apache Lucene QueryParser 模块。短 语解析过程当中用到了 Organic Lose Analyses, 这里 有一个短语分词模块,可用来区分短语。这些短语都是 由关键字组成的,每个短语都可以访问关键短语,以及 调用 Lucene Apache Dyche 插件来接收结果并通过多 个关键短语来计算结果。
(4)org. Apache Lucene Search 模 块。 在 检 索 关键词便利索引文件,查找与之相匹配的文档列表,通 过计算算法 Lucene 的二分法搜索目标, 寻找匹配的顺 序,获取搜索结果。
(5)org. Apache Lucene Store 模块。主要是文 件检索 (Root),然后再存储文件。
(6) org. Apache Lucene Document 模块。Lucene 算法这一模块是数据结构,还推荐使用基于数据结构的 索引,以便在实际应用中拥有更多内存格式的文件,建 立索引前要按格式目标化, 以确保支持 Lucene 使用的 阈值,实现 Document 对象数据格式转化特定文件实 现引擎转换得以完成 [3]。
2 向量空间模型
一个向量空间模型描述文件的翻译从向量形式在一 个文档和用户查询映射空间就有了根据这些变量之间的 相似度值的文件,确保用户搜索信息在模型测量内容的 性质和文件相似度,然后以同样的方式返回结果。但 是,由于搜索引擎的倾向,搜索引擎计算给定的向量。 同样,度量向量模型被认为是有意义的。结合引擎搜索计算文档查询结果相关结果予以排序,讨论向量空间模 型,有助于厘清问题,给搜索模块留下清晰的定义。
定义 1:Document 文档是指文献片段当中的标 题、摘要、正文,一篇文章的格式包含有 DOC、PDF、 HTML 标记为 D。
定义 2:Index Term 索引项文档,含有可代表文档 性质的基本语言单位,包含有字词,也就是检索词,关 键词记为 T。
定义 3: 索引会通过 Term Weight 轻松获取目录 项,对其进行排序,对应的文档作为虚拟文档的带宽连 接的值。计算方法用应用 t f-i df 公式。
定义 4: 向量空间模型 VSM,主要是向量空间模型 表示文档特征项,有 N 个不同的索引项,可以利用计 算文档与每个索引项的权重进行对比,查询文档向量与 查询向量夹角作为二者之间的相似程度。得出的结果为 [0.1],计算值越大,查询需要的条件越多,生成的结果 就越大,所表现出的相关性就越大,生成的搜索结果的 总数也就越大,最后排序结果按照相似程度高到低的顺 序排列。
3 Lucene 的评分机制和搜索过程
搜索引擎的核心概念是根据标准来评估搜索结果的 搜索机制。例如,由于搜索系统所提供的相关性,应引 入计算结果的公式,得出计算结果的数值,最后得出储 存结果,以便反馈给用户,由于所列的相对范围列有相 关的表格,组织会建立计算结果的机制,然后把所列 出的资料加以归类,再将问题的调查结果清楚反馈给用 户。因此,搜索引擎最终的核心是利用计算方式对文档 当中的信息查询进行计算,形成相关性予以排序。
因此,由 Lucene 内建的算法将计算文档中得到的 点,并以此作为 VSM 模型的中心思想,适时计算出搜 索结果予以排序,这主要是建立在索引确定的文档得分 用户输入关键词,通过 Lucene 计算查询关键词,其中 将得分最高的文档排在最前面。事实上运算得到的结果 与查询关键词具有相关性,得分简单的理解为关键词语 文中的文档出现频率较少,为此形成对应的公式进行计 算。Lucene 评分公式包含的影响得分的因素,主要包含 有索引项 T 在文档 D 当中所出现的频率 [4] ,以及索引项 T 在倒排文档当中所存在的频率,并结合加权因子在索 引过程当中予以设置,明确因子包含查询内容的个数。
标准的查询主要是平方值,然后返回当前索引中的 词组目的是找到哪些地方出现过这一关键词,以此来衡 量质量指标主要是明确关键词所在的文档的准确率。查 全率主要是衡量系统当中出现的关键词的能力,查准率主要是衡量系统过滤非相关文档的能力,搜索效率越高 的 Lucene 计算方法及反向索引的优势明显, 搜索时删 除字符串选一个合适的条目指向文件的频率、读文件的 精确指向频率文件,所要求的信息的关键词热门类别是 有序的存储 Hits 当中, Hits 类是存放有序搜索结果的 单容器,搜索引擎的搜索结果通过 Hits 对象放在页面 上。根据性能, Hits 选择了一个特定的搜索引擎,即从 搜索引擎中搜索文档。结果,随着寻找新增搜索问题的 开始,数据得到了改善 [5]。
Lucene 计算法使用向量场模型计算所有文档向量 和查询向量的相似性,然后按字母顺序排列搜索结果。 还有更高的文档,同等价值的文件,更好地符合用户查 询的需要。
4 引擎性能与可行性方案
4.1 搜索引擎性能
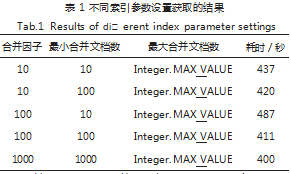
用户搜索文件所占内存较少, Lucene 计算无法充 分根据指标设置满足查询条件需要,需要以协助满足 当一个援助使用的非文件的索引编制, 将 Lucene 计算 的成果通过一些援助增加了卡片写文件到磁盘的算法, Lucene 计算缓慢等内容的搜索结果反馈给用户, 瓶颈 有以下两种:(1)索引文件写入文档的过程速度慢;(2) 进入小磁盘的部分均已计算合并为大段部分。Lucene 时所表现出的 3 个参数,如合并因子、最大合并文档 数量、最小合并文档数,文件数量最大应当在指定的最 小数量根据参数的不同提高索引性能,改善参数设置以 验证关键字、设置参数优化性能关系中明确划定实验界 线。使用 Windows 系统,实验数据如果是 1G 的文本 文件数量有 5000 个,其最终的实验结果如表 1 所示。
4.2.1 移 PC 端自身特点
(1)储存能力。PC 端计算机储存储存空间有限,一般储存空间达到了 128G,为此需要保障搜索引文件 的紧凑性,充分利用存储空间,结合操作速度实现搜索 引擎的优化。
(2)运算速度。相对于计算机 PC 设备而言,设备 处理能力有待完善。苹果计算机采用三星电子生产的 S3C6400 型处理器, 智能计算机领域高端机预算能力相 对较低,所以建立电脑的更新过程是要对 CPU 功能处 理能力的提升,结合计算提升 PC 端电脑的自身处理能 力,尽管运算较为复杂,但需要借助于符合逻辑的算法 予以搜索,结合储存空间大小平衡、空间复杂性和时间 复杂性 [6]。
(3)电池续航能力。笔记本电池技术之后与其他软 件的技术发展,使用设备发展遇到瓶颈,限制其他业务 的开展,尤其是笔记本电池续航能力会结合计算机使用情 况发生变化,因此搜索引擎的索引、建立、更新以及便 利过程要符合 I/O 操作和 CPU 运算, 考虑计算机电池 续航能力,不断改进运算方法,做到搜索引擎的优化。
(4) PC 端屏幕尺寸分辨率。笔记本电脑小巧的便 于携带,屏幕不会很大,分辨率大小不等,因此搜索结 果一定要做到简单、直观、便捷,浏览展现选项情况。
(5) 文件格式。主要包含有信息、记事本、音频、 视频、通讯录等,主流操作系统有安卓系统、Windows 系统等。不同计算机操作系统文件结构存在差异性,因 此计算机型号存在硬件差异,文件格式存在不一致性, 后续 Lucene 算法、计算流程应该简化。
4.2.2 使用设备 Lucene 算法的搜索引擎功能
由此可见,使用设备搜索引擎功能要针对计算机自 身特点进行分析,首先要明确搜索引擎文件类型。计算 机支持的信息包含有邮件、彩信、短信以及联系人、音 频、视频、图片、Word 、PDF 等文件,支持应用程序数 据搜索,在授权的情况下,以便于应用程序输入关键词。
扩展性要支持搜索对象的扩展,确定计算机内部支 持搜索的范围,即用户条目匹配和添加默认条目的模糊 查询,形成关键词列表,自动列出找到一份可供选择的 用户列表,以使用户输入的效率提高,然后用搜索结果 支持用户搜索的重新排序,并对搜寻结果以不同的音频 文件格式、地址簿和应用程式出现。
允许用户操作搜寻结果,直接唤起应用程序,所 以更新要满足被检索文件删除增加时更新索引文件,以 便于用户获取新增加的检索。文件检索响应时间不多于 3s。搜索覆盖率应结合互联网要求,总页数在 1/3.针 对计算机屏幕而言,数据资源有限,要保证用户在关键 词基本应用时搜索终端,满足关键词所需要的所有资源。
4.2.3 PC 端 Lucene 算法体系架构建立
考虑 Lucene 算法良好的体系架构,以反映出索引 的建立和搜索流程和使用设备特征以及搜索功能需求,明确搜索引擎体系架构包含有适配器模块、查询解析模 块、核心模块、结果展现模块、用户界面等。结合关键 词词库以及用户自定义词库、文件索引、数据库等,明 确各模块的功能原理。
调整文件格式以适应输出格式的插件,更改文件格 式,更改文件格式在获得不同文件类型之前,根据文件 目标格式提供统一对外连接的目标格式,采用 Lucene and Document 数据结构提供视频结构,从而选择标 签和核心模块调用数据。
核心模块:对目标格式进行分词,建立索引,搜索 索引文件。
查询解析模块:解读逻辑,插入关键词和输入信息 数据关键词,单击搜索,在搜索单位搜索运算符进行运 算,获取搜索结果。
结果展现模块:用于符合条件结果的加以区分,并 展现给用户,将搜索结果按照 Windows 系统的选项卡 进行分类展示。用户界面与用户互动,接收用户数据和 信息,并向其显示搜索结果。
文件索引数据库:需要保存索引的关键短语, 可以 通过索引快速而准确地获得所要求的测试数据信息。
关键词词库:通过分词使用关键词列表筛选统计, 完成词汇频率排序,并结合存储空间的大小,按照频率 高低排序调整词库大小,以便做到检索准确。
5 结语
Lucene 算法作为可扩展、高性能的信息检索库,通 过 Java 实现开源项目,以提高应用程序的索引和搜索 能力。其应用于使用设备,提高了互联网大数据搜索引 擎速度。
参考文献
[1] 李一鑫 .搜索引擎中遗传模拟退火算法的应用略论[J].技术 与市场,2022.29(3):68-70.
[2] 陈情情,何孙东 .基于Google算法的搜索引擎优化策略研究 及应用[J].信息与电脑(理论版),2021.33(22):59-62.
[3] 乔天玲 .基于改进HITS算法的垂直搜索引擎的设计与实现 [D].沈阳:沈阳建筑大学,2021.
[4] 王茜 .搜索引擎自动完成算法的地域歧视考察[J].青年记者, 2021(10):38-39.
[5] 张贤亮,张尤赛.基于TF-IDF算法的分层搜索引擎设计[J].计 算机与数字工程,2021.49(3):456-461.
[6] 叶云波.基于元搜索引擎的排序算法研究[D].天津:天津理工 大学,2021.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/62409.html