SCI论文(www.lunwensci.com)
摘要:机读目录数据是广泛应用于图书情报领域的一种半结构化数据。由于缺乏专用的数据转换工具,机读目录数据预处理往往繁琐且耗时。机读目录数据管道是一套自动化流程,用于将机读目录记录转换为便于数据分析师、数据科学家、应用程序等下游用户使用的JSON数据。从简单的数据报告到复杂的数据科学项目,这种灵活务实的解决方案能够不同程度地简化和优化数据准备工作。
关键词:机读目录;数据管道;JSON
Design and Implementation of Machine-readable Cataloging Data Pipeline
ZHANG Wei
(National Library of China,Beijing 100081)
【Abstract】:MARC(MAchine-readable Cataloging)data is a type of semi-structured data widely used in thefield of library and information science.MARC data preprocessing is often tedious and time-consuming because of a lack of dedicated data transformation tools.MARC data pipeline is a series of automated processes that can transform MARC records into JSON data useful for downstream consumers,such as data analysts,data scientists,applications.From simple data reporting to complex data science projects,thisflexible and pragmatic solution can simplify and optimize data preparation to varying degrees.
【Key words】:MARC;data pipeline;JSON
0引言
随着文献资源数字化进程的推进,不断产生、积累和关联的机读目录数据在文献资源共享中发挥了重要作用。与此同时,根据不同研究目的或业务需要对机读目录数据进行开发和利用也逐渐成为图书情报机构的一项日常工作。然而,对这种应用于特定领域的半结构化数据,很多流行的技术工具未提供支持,导致数据预处理中大量不尽相同、重复性高的操作往往只能由人工完成,它们的实现步骤繁琐且依赖编目和编程知识的掌握。为此,本文提出一种机读目录数据管道方案,旨在以技术手段代替人工作业,提升数据预处理效率,以期为机读目录数据处理和分析工作提供新思路。
1基本概念
1.1机读目录与记录结构
机读目录(MARC),即机器可读目录(MAchine-Readable Cataloging)是遵循国际标准ISO 2709及相应国家标准的数据格式。一条MARC记录以记录头标开始,后接目次区,再接字段区,以记录分隔符结尾。
记录头标和目次区中的所有数据以及字段指示符、子字段标识符、字段分隔符和记录分隔符都采自ISO/IEC 646的字符表,每个字符一个8位字节[1]。
记录头标,标识记录的某些特征,由24个字符组成。第0-4位字符存储整条记录的长度。第12-16位字符存储数据基地址,即字段区首字符相对于记录开始的位置。
目次区,存储字段位置的索引,由若干目次项组成,以字段分隔符结尾。每个目次项由字段标识符、字段长度、起始字符位置组成,共12个字符。字段标识符,即相应字段的名称,由3个字符组成。字段长度,即当前字段标识符在字段区的对应字段所占用的8位字节数,由4个字符组成。起始字符位置,即当前字段标识符对应的字段相对于字段区开始的位置,由5个字符组成。
字段区,存储字段相关内容,由若干字段组成。控制字段(00开头的字段)由字段内容和字段分隔符组成,没有字段指示符和子字段。数据字段(非00开头的字段)由字段指示符、子字段标识符、子字段内容、字段分隔符组成。字段指示符在每个数据字段的开头,即第一个子字段分隔符的前面,为字段提供附加信息,由2个字符组成。子字段标识符位于子字段的开头,标识字段中不同的子字段,由子字段分隔符和子字段代码2个字符组成,前者是ISO/IEC 646或ISO/IEC 6429的IS1,后者一般为字母或数字。字段分隔符位于目次区、字段区中每个字段的结尾,区分相邻字段,是ISO/IEC 646或ISO/IEC 6429的IS2。
记录分隔符,标识记录的终止,是ISO/IEC 646或ISO/IEC 6429的IS3。
1.2机读目录数据管道
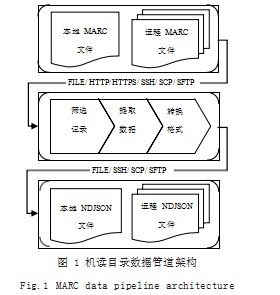
机读目录数据管道是源端到目的端的数据批处理工序,能够自动化地将原始数据精简为具有针对性和通用性的形式。具体而言,它从不同来源读取包含一条或多条机读目录记录的文件,然后从中筛选记录、提取数据、转换格式,最后存储结果集到指定位置以供下游数据用户使用,其管道架构图如图1所示。
为便捷地构建数据管道,本文设计了一种称为MDPL(MARC Data Pipeline Language)的DSL(Domain Specific Language)。它采用from、select、to 3个关键词和简单的语法来描述处理流程,即从何处读取文件,通过何种规则来转换数据,最后保存结果集到何处,即:
from源文件路径或URI|编码方式;
select数据转换规则;
to目标文件路径或URI。
2数据管道的设计
2.1数据访问
数据访问从本地计算机或远程服务器读取机读目录记录文件并将文本流引入数据管道。文件路径或URI、字符编码方式是此过程的必要参数。错误参数将导致文件无法被访问或解析。如果多个源文件配有相同的转换规则和目标文件,数据访问语句可组合在一起使用。
例1:访问本地文件。编码方式为UTF-8。注释:非关键词开头的行均被视为注释。
from~/local/path/file.mrc|utf-8
例2:通过FILE协议访问本地压缩文件。编码方式为GBK。
fromfile:///home/user/file.bz2|gbk
例3:通过HTTP、HTTPS协议访问远程压缩文件。编码方式为ISO-8859-1。
from https://example.com/path/file.gz|iso-8859-1
from http://example.com/path/file2.gz|iso-8859-1
例4:通过SSH、SCP、SFTP协议访问远程文件。编码方式为UTF-8。
from[ssh|scp|sftp]://username:password host:port/path/file.iso|utf-8
2.2数据转换
数据转换从满足条件的机读目录记录中提取指定数据并将其转换为适用于后续应用的JSON(JavaScript Object Notation)格式。JSON是一种数据交换格式[2],易于人类读写和机器解析。对于产生(序列化)和读取(反序列化)JSON数据,所有现代编程语言都提供了良好的支持[3]。JSON采用简洁清晰的层次结构和独立于编程语言的文本格式来存储和表示数据,其对象和数组结构为机读目录数据的组织和交换提供了理想的数据结构支持。
数据转换规则:字段项1字段项2……字段项N筛选条件。
字段项指定从记录中何处提取数据,包括记录头标、控制字段、数据字段各子字段、字段指示符。每个字段项由字段标识符、可选的子字段代码或星号(*代表字段指示符)构成。
筛选条件以表达式的形式描述字段匹配规则。每个条件表达式由字段标识符、字段指示符、子字段代码、可选的字段特征构成,并支持逻辑组配。如果(子)字段存在且符合正则表达式所描述的字段特征,则对应条件表达式的值为真,否则为假。正则表达式是用正则表达式语言创建的一些用来匹配和处理文本的字符串[4],赋予使用者描述和分析文本的能力[5]。这种转换规则的设计旨在借助正则表达式的灵活性和表现力,通过有限的符号描述多样的需求。无字段特征表示仅验证(子)字段存在与否。条件表达式因(子)字段的重复出现会多次求值,其终值或在记录解析完毕后才能确定。逻辑运算符,按照运算优先级从高至低的顺序,包括逻辑非(!)、逻辑与(&)、逻辑或(|)。逻辑非对条件表达式的值取反;逻辑与表示其两侧条件表达式的值应全部为真;逻辑或表示其两侧条件表达式的值应至少有1个为真。小括号可改变运算顺序和提升可读性。筛选条件中的空格和小括号具有不同的语义,为避免歧义,字段特征中的空格和小括号前置反斜线()转义。
下横线(_)作为通配符可代替字段标识符、字段指示符、子字段代码中的任意字符,实现模糊匹配和多(子)字段聚合提取。
如果记录符合条件,转换结果为序列化为JSON的被提取数据,否则为JSON空对象。同一字段项的历次值在去除重复后,以字符串数组结构被保存。(子)字段能否重复由标准规定,而是否重复由主客观因素综合决定。为保持数据结构一致以便解析,字段项的唯一值同样以字符串数组结构被保存。{"字段项1":["值"],"字段项2":["值1","值2"],……,"字段项N":["值1","值2",……,"值N"]}的结构使得后续解析免于判断某字段项的值是字符串还是数组类型。
例1:无条件提取245$a、$k。(示例以$表示子字段分隔符。)
select 245a 245k
例2:如果010$a存在,则提取010$a、101字段的指示符。
select 010a 101*010__a
例3:如果记录头标的第5位字符不是“d”,则提取001字段。记录头标在转换语句中被视为字段,通过标识符“LDR”表示。
select 001!LDR___^.{5}d
例4:如果200字段的指示符为“1”并且$b为“专著”,则提取005、010$a。
select 005 010a 2001 b^专著$
例5:如果200$a或者任意5字段$a含有“算法”,则提取其$a。所有5字段$a在去除重复后聚合在一起。
select 200a 5__a 200__a算法|5____a算法
例6:如果245$a含有“machine learning”并且$k为“monograph”,则提取245$a和300$a。
select 245a 300a 245__a(?i)MachineLearning&245__k^monograph$
例7:如果200$a包含“Java”并且不含“script”,或者606$a为“Java语言”,则提取整个200字段,即包括子字段标识符在内相连排列的全部子字段。
select 200(200__a(?i)java&!200__a(?i)script)
|606__a^Java语言$
2.3数据存储
数据存储将转换后的数据以NDJSON格式集中保存到本地计算机或远程服务器上的文件中。NDJSON(Newline Delimited JSON)是一种方便的格式,用于存储和流式传输可以一次处理一条记录的结构化数据[6]。它采用UTF-8编码,要求每一行均为有效的JSON值,并以n或rn作为行分隔符。鉴于文件中的每一行都是一个独立的JSON文档,用户在解析数据时无需将整个文件读入内存,并且还能够容易地追加新记录到文件中。
机读目录数据管道并非全流程的数据处理,而是对若干项目中相似性、重复性部分的封装。因此,它的输出结果通常会成为其他应用的源数据。
例1:保存数据到本地计算机。
to~/local/path/file.ndjson
例2:通过FILE协议保存数据到本地计算机。
tofile:///home/user/file.ndjson
例3:通过SSH、SCP、SFTP协议保存数据到远程服务器。
to[ssh|scp|sftp]://username:password host:port/path/file.ndjson
3数据管道的实现
3.1容器化应用
机读目录数据管道应用程序是一套通过Docker容器化的Python脚本。它首先读取与解析使用MDPL编写的管道定义文件,然后按照既定方案自动完成整个流程。
所谓容器是对应用程序及其依赖关系的封装[7]。Docker是一个跨平台、可移植并且简单易用的容器解决方案,可在容器内部快速自动化地部署应用,并为容器提供资源隔离与安全保障[8],如图2所示。不同的容器相互隔离,容器之间可以通过网络互相通信[9]。得益于这种轻量级虚拟化技术的优势,用户不必自行配置Python运行环境和解决依赖关系,只需要在运行容器时挂载管道定义文件和涉及本地读写的文件夹即可。例如,将宿主机当前目录下的管道定义文件my.mdp挂载到容器内的/mdp并运行名为marcpipe的容器:docker run--rm-v`pwd`/my.mdp:/mdp marcpipe。
3.2应用案例
基于Redis实现中文书目搜索引擎。Redis是一种使用内存存储的非关系数据库[10],其全文搜索引擎模块RediSearch[11]搭配RedisJSON[12]模块,可实现索引、查询JSON文档。
首先访问文件服务器上的中文文献机读记录文件,然后选择2010年及以后我国大陆出版的图书并从记录中提取ISBN、正题名、出版者、出版年、主题词,最后保存JSON格式的结果集到本机。
编写管道定义文件cnmarc.mdp:
from http://192.168.12.24/biblio/cnmarc.mrc|utf-8
select 010a 200a 210c 210d 60_a 010__a^978-?7&200__b^专著$&210__d^20[12]d$
to/data/cnmarc.ndjson
运行容器:
docker run--rm-v`pwd`/cnmarc.mdp:/mdp-v`pwd`:/data marcpipe
查看结果:
{"010a":["978-7-80731-080-8","978-7-80731-082-2"],"200a":["射雕英雄传"],"210c":["广州出版社","花城出版社"],"210d":["2010"],"60_a":["侠义小说","长篇小说"]}
……
{"010a":["978-7-5675-2265-7","978-7-5675-0442-4"],"200a":["1984","动物农场"],"210c":["华东师范大学出版社"],"210d":["2013"],"60_a":["长篇小说"]}
……
{"010a":["978-7-5121-2043-3"],"200a":["Python程序设计教程"],"210c":["清华大学出版社","北京交通大学出版社"],"210d":["2014"],"60_a":["软件工具"]}
……
对数据在内容、语义、类型层面进行转换。这种转换不在数据管道的处理范围内,也没有数据管道中格式转换般的普适性解决方案,应根据需求而定。就中文书目记录而言,它包括但不限于将ISBN去除连字符,将出版年转为数值型,将中国图书馆分类法的类号转换为对应类名,例如:
{"010a":["9787807310808","9787807310822"],"200a":["射雕英雄传"],"210c":["广州出版社","花城出版社"],"210d":2010,"60_a":["侠义小说","长篇小说"]}
将数据导入Redis后建立索引:
FT.CREATE idx:book ON JSON PREFIX 1"book:"LANGUAGE CHINESE SCHEMA$.010a.*AS isbn TAG$.200a.*as title TEXT$.60_a.*AS subject TAG$.210d AS year NUMERIC SORTABLE
TEXT索引适用于全文搜索,支持中文分词。例如,搜索正题名中包含“互联网”和“金融”但不含“报告”的记录:
FT.SEARCH idx:book"title:(互联网金融-报告)"
TAG索引与TEXT索引相似,以功能简化换取效率提升,适用于非模糊搜索。例如,搜索ISBN为“97871154 02844”的记录:
FT.SEARCH idx:book"isbn:{9787115402844}"
NUMERIC索引适用于数值搜索。例如,搜索主题词为“侦探小说”或“推理小说”且出版年为“2018至2020”的记录:
FT.SEARCH idx:book"subject:{侦探小说|推理小说}year:[2018 2020]"
一些技术工具同RediSearch一样仅支持有限的数据格式,但与数据管道协作,即可实现对机读目录数据的兼容。
4结语
本文在介绍机读目录相关概念的基础上,提出一种可自定义任务的数据管道技术方案。基于该方案开发的应用程序可灵活地将机读目录记录按需转换为易于解析的JSON数据,进而为数据分析、数据展示等后继项目和各种关联性研究提供便利。
经过长期应用于不同规模的项目,机读目录数据管道从功能设计到技术选型逐步被完善,现已达到预期目标。考虑到大数据环境下异构数据处理的需要,扩展在HDFS(Hadoop Distributed File System)上访问和存储MARC及其变体格式MARCXML和Aleph Sequential记录文件的支持,将成为机读目录数据管道下一阶段的目标。
参考文献
[1]全国信息与文献标准化技术委员会.信息与文献信息交换格式:GB/T 2901—2012/ISO 2709:2008[S].北京:中国标准出版社,2012:4.
[2]BASSETT L.JSON必知必会[M].魏嘉汛,译.北京:人民邮电出版社,2016:1.
[3]马尔斯.JSON实战[M].邵钏,译.北京:人民邮电出版社,2018:3.
[4]福塔.正则表达式必知必会[M].门佳,杨涛,译.修订版.北京:人民邮电出版社,2019:4.
[5]FRIEDL J E F.精通正则表达式(3版)[M].余晟,译.北京:电子工业出版社,2012:1.
[6]NDJSON.ORG.Newline Delimited JSON[EB/OL].(2020-06-23)[2022-10-10].http://ndjson.org.
[7]MOUAT A.Docker开发指南[M].黄彦邦,译.北京:人民邮电出版社,2017:3.
[8]浙江大学SEL实验室.Docker容器与容器云(2版)[M].北京:人民邮电出版社,2016:4.
[9]杨保华,戴王剑,曹亚仑.Docker技术入门与实战(3版)[M].北京:机械工业出版社,2018:5.
[10]CARLSON J L.Redis实战[M].黄健宏,译.北京:人民邮电出版社,2015:4.
[11]Redis.RediSearch[EB/OL].(2022-07-27)[2022-10-10].https://redis.io/docs/stack/search/.
[12]Redis.RedisJSON[EB/OL].(2022-09-08)[2022-10-10].https://redis.io/docs/stack/json/.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网! 文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/62047.html