SCI论文(www.lunwensci.com)
摘 要:文本数据处理分析是大数据处理中的重要分支之一,它能从大规模文本数据中提取感兴趣的信息。文章以《三国 演义》为例,介绍了在 Python 环境下进行文本数据处理分析的实现方法。通过中文分词、图表可视化和词云制作等方式,可 以帮助读者快速获取关键词和高频词,迅速把握文章蕴含的主旨,深入理解文本数据处理分析的意义和价值。这些方法为大规 模文本数据的处理提供了可行性,同时也为 Python 在文本数据处理领域的应用提供了有益的参考。
Research on Text Data Processing Based on Python
CAI Ying
(Ningbo Middle School, Ningbo Zhejiang 315000)
【Abstract】:Text data processing and analysis is a crucial branch of big data processing, as it enables the extraction of relevant information from massive amounts of textual data. This article uses "The Romance of Three Kingdoms" as an example to illustrate the implementation of text data processing and analysis in a Python environment. By utilizing techniques such as Chinese word segmentation, chart visualization, and word cloud creation, readers can quickly obtain keywords and high-frequency words, grasp the main theme of the article, and gain a deeper understanding of the significance and value of text data processing and analysis. These methods provide feasibility for the processing of massive amounts of textual data while also serving as a valuable reference for Python's application in the field of text data processing.
【Key words】:Python;Chinese word segmentation;chart visualization;word cloud
0 引言
随着社会的高速发展、科技的进步以及信息的畅 通,对于海量数据的挖掘和运用变得至关重要。在我们 的日常生活中,文本数据无处不在。如何从大量的文本 中提取有用的信息,可以让我们快速了解文本的核心内 容,这是值得我们深入研究的问题。Python 因其简洁、 优美、开源、易学等优点,成为了目前最热门的数据处 理工具之一。同时, Python 拥有众多丰富的第三方库, 例如 NumPy、Matplotlib、Pandas 和 WordCloud 等, 已经成为文本数据分析领域中不可缺少的分析工具。
文本数据处理的主要流程包括 :获取数据源、分 词、特征提取、数据分析和结果呈现。在中文分词方面, Python 中的Jieba 模块可以快速提取文本中的词语。通 过对词语进行统计,我们可以迅速了解文章中每个词语出现的频率。在此基础上,结合可视化模块 Matplotlib 和 WordCloud, 我们可以直观地显示高频词汇, 这在 视觉上具有一定的冲击力,能够让我们获取文章的重要 信息。本文以著名作家罗贯中的《三国演义》为例,尝 试对此书进行数据分析,以了解其重要内容。
1 数据分析重要过程
1.1 中文分词
1.1.1 分词理论基础
分词是自然语言处理(NLP)中文本处理的基础环 节和前提 [1]。它指的是将连续的字序列按照规定重新组 合成词语的过程。相较于英文,中文分词更为困难,因 为汉字之间没有像英文单词一样的空格来区分,而且在 基本文法上具有独特性,因此,中文分词涉及到复杂 的提取方法。通常情况下,中文的简单划分是以字、句子和段落为单位,而不是以词作为分解符。例如以下句 子 :下雨天留客天留人不留。不同人可以划分出不同 的词组合。(1) 下雨天留客 / 天留人不留 ;(2) 下雨天 留客 / 天留人 / 不留 ;(3)下雨天留客 / 天留人不 / 留 ; (4)下雨 / 天留客 / 天留人不留 ;(5)下雨天 / 留客天 / 留人 / 不留 ;(6) 下雨天 / 留客天 / 留人不 / 留 ;(7) 下雨天 / 留客天 / 留人不留。每个人因为理解不同,倾 向的情感不同,可以有不同的分词方法。
目前中文分词面临的技术难点主要包括词的界定、 歧义消除以及未登录词识别 [2]。常用的分词算法可分为 三类 :基于规则、基于统计和基于词典。基于规则的方 法需要模拟人的理解方式,通过学习大量的资料和规则 来实现分词,但目前仍处于研究试验阶段。相比之下, 基于词典和基于统计的方法更适合日常数据处理应用。
基于 Python 的中文分词模块 Jieba,利用字典库 对待分词内容进行比对,并通过高效词图扫描图和动态 规划找出基于次品的最大切合组合。除此之外, Jieba 还支持自定义中文词组,并采用基于汉字成词能力的 HMM 模型来处理未登录词。Jieba 分词支持 3 种模式 的切割方式。
(1)精确模式。默认模式。句子精确地切开,每个 字符只会出现在一个词中,适合文本分析。例如 :
>>> sent=jieba.cut(' 我爱高中信息技术课程 ',cut_ all=False)
>>> print(' 精确模式 :'+'/'.join(sent))
输出结果 :
精确模式 :我 / 爱 / 高中 / 信息技术 / 课程
(2)全模式。把句子中所有词都扫描出来 , 速度非 常快,有可能一个字同时分在多个词,存在冗余。例如 :
>>> sent=jieba.cut(' 我爱高中信息技术课程 ',cut_ all=True)
>>> print(' 全模式 :'+'/'.join(sent))
输出结果 :
全模式 :我 / 爱 / 高中 / 中信 / 信息 / 信息技术 / 技 术 / 技术课 / 课程
(3) 搜索引擎模式。在精确模式基础上,对长词再次 进行分割,以提高召回率,适合搜索引擎分词 [3]。例如 :
>>> sent=jieba.cut_for_search(' 我爱高中信息技 术课程 ')# 搜索引擎模式
>>> print(' 搜索引擎模式 :'+'/'.join(sent))
输出结果 :
搜索引擎模式 :我 / 爱 / 高中 / 信息 / 技术 / 信息技 术 / 课程
其他 :jieba 的分词还有一种jieba.lcut 方法, 同 jieba.cut() 对比, 两者使用参数一致, 区别在于返回的 对象,一个是返回的列表,一个返回的是可迭代对象。
1.1.2 实例展示
为了进行《三国演义》文本分析,首先在可靠的 网站中获取数据源,确认数据源的编码方式,并采用 Python 程序读取文件进行数据分词。为了方便后续分 析,可以采用jieba.lcut() 方法,并选择精确模式进行 分析。部分代码如下 :
importjieba
import codecs
txt=codecs.open('threekingdoms.txt','r', encoding='utf-8').read()
words=jieba.lcut(txt)# 按词典库进行分词, 列表 展示
1.2 词频统计
词频,是一种文本挖掘的常用加权技术, 用以描述 一个词在文本中出现的重复次数。字词随着它在文件中 出现频率的增加,其重要性也成正比例提升。目前,大 多数中文文本分析中都采用词作为特征项,通过词频统 计获得特征词,提高文本处理的速度和效率。
在《三国演义》案例中,通过 Jieba 分词,已经获 取全书所有词汇,数量较大,有近 5 万多个词。对于文 本数据分析,我们重要的是抓住文章的主旨,所以获取 出现频次最高的词语是较为重要的。在众多词语中,如 何确定每个词的词频,通过 Python 工具,有很多实现 的方法。在人为统计的时候,有两种方式 :(1)找到 第一个词,全文阅读,找出这个词在文章中出现的总次 数。随之再找出第二个词,确认其在全文中出现的次 数。依次反复,工作量巨大 ;(2)我们仍需逐步获取每 个词,找到第一个词,次数标记 1.然后查看文章出现 的第二个词,判断确认,如果已存在,则出现次数累计 加 1.若不存在,则计数为 1.遍历下一个数,直至所 有数统计完成。显而易见,第(2)种方式的执行效率 更高, 采用第(2)种方法的算法流程图来实现如图 1 所示。
在程序实现方面,可以做到如下优化 :
(1)文章中含有大量语气助词、副词、介词、连接 词等,如 :的、地、得等,通常以单个字存在,可以直 接过滤掉。
(2)不同人物在不同场景下有不同的称呼,可以统 一,比如“孔明”“诸葛亮”“孔明曰”,其实都是同一 个人物的出场。
Fig.1 Flow chart of word frequency statistics
(3) 如想了解《三国演义》中主要人物,可以经过 多次统计,剔除无关词语,统计前 15 名主要人物。
优化代码如下 :
word_c={}
for word in words:
word=word.strip('\n')
if len(word)==1:
continue
# 对同一个人物不同情况的称呼进行统一
elifword == " 诸葛亮 " or word == " 孔明曰 ": rword = " 孔明 "
elifword == " 关公 " or word == " 云长 ": rword = " 关羽 "
elifword == " 玄德 " or word == " 玄德曰 ": rword = " 刘备 "
elifword == " 孟德 " or word == " 丞相 ":
rword = " 曹操 "
else:
rword = word
if rword in word_c:
word_c[rword]+=1
else:
word_c[rword]=1
#word_c[rword] = word_c.get(rword,0) + 1
excludes = {" 将军 "," 却说 "," 二人 "," 不可 "," 荆州 "," 不能 "," 如此 "," 商议 "," 如何 ",\
" 主公 "," 军士 "," 左右 "," 军 马 "," 次 日 "," 引兵 "," 大喜 "," 天下 "," 东吴 ",\
" 于是 "," 今 日 "," 不敢 "," 魏兵 "," 陛下 "," 一人 "," 都督 "," 人马 "," 不知 ",\
" 汉 中 "," 众将 "," 汉 中 "," 只 见 "," 后主 "," 蜀兵 "," 上马 "," 大叫 "," 太守 ",\
" 此人 "," 夫人 "," 先主 "," 后人 "," 背后 "," 城 中 "," 天子 "," 一面 "," 何不 ",\
" 大军 "," 忽报 "," 先生 "," 百姓 "," 何故 "," 然后 "," 先锋 "," 不如 "," 赶来 "}
for word in excludes:
del word_c[word]
print(word_c)
1.3 数据可视化
1.3.1 生成词频统计图
统计图是一种有效的数据可视化工具,利用 Python 的 Pandas 模块和 Matplotlib 模块, 可以提取出《三国 演义》中出现频率最高的 15 个人物。采用词频统计图 便于读者更直观的确认书中重要人物,在提高数据理解 方面有着重要的作用。
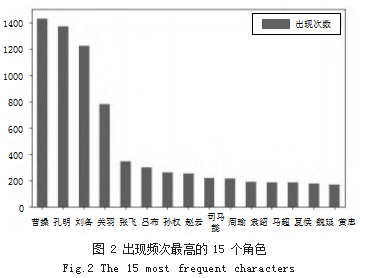
采用柱形图来显示《三国演义》中出现频率最高的 15 个人物,可以清晰地了解每个人物提及的次数以及 相对其他人物的次数变化,效果图如图 2 所示。相关代 码如下 :
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] s1=pd.Series(word_c)
df1=pd.DataFrame(s1.columns=[' 出现次数 '])
df2=df1.sort_values(' 出现次数 ',ascending= False)
df2[0:15].plot(kind='bar',rot=0)
由图 2 可知, 《三国演义中》出现频次最高的 3 个 人物是曹操、孔明、刘备。在词频统计的基础上,通过 可视化的方式,我们可以直观感受到不同角色的重要 程度。
1.3.2 生成词云图
词云图又称“文字云”或者“标签云”,是数据分 析中常见的一种可视化手段,用于展示文本数据中的关 键词和频率 [4]。通常情况下,出现频率较高的关键词以 较大的字体显示,而出现频率较低的关键词则以较小的 字体显示。这样,人们可以快速浏览文本数据,了解 其中最重要的主题或关键词。词云图广泛应用于文本分 析、营销研究、舆情监测等领域。
在 Python 中, 可以使用 WordCloud 来生成词云图。 WordCloud 易于使用,同时可以支持定制化 :WordCloud 允许用户自定义字体、颜色、形状等参数,从而生成更 适合自己需求的词云图。WordCloud 库函数操作具体 步骤 :
(1)按需配置具体参数 :
width 和 height :词云图的宽度和高度,默认为 400 和 200.可以根据需要自行设置。
background_color :词云图的背景颜色, 默认为 黑色。可以使用字符串、RGB 元组或颜色名称指定颜色。
colormap :词云图中使用的颜色映射表。可以从 matplotlib 库中选择一个预定义的映射表, 如 'Pastel1'、 'gist_rainbow' 等。
font_path :用于生成词云图的字体文件路径。可 以使用本地系统中的任何 TTF 或 OTF 字体文件,也可 以使用在线字体。
stopwords :要忽略的常见词列表。可以使用空格 分隔的单词字符串,或包含单词的列表。
max_words :词云图上显示的最大单词数。默认 为 200.
mask :掩码图像,用于控制词云图形状。可以使 用 PNG、JPG、BMP 等格式的图像作为掩码。
contour_width 和 contour_color :词云图轮廓线 的宽度和颜色。
random_state :词云图生成器的随机种子。使用 相同的种子将生成相同的词云图
(2) 采用 WordCloud.generate() 或 WordCloud. fit_words() 生成词云图 :
WordCloud.generate() 方法接受一个字符串类型的文
定要保存的文件名和路径。
词云图适合对全文进行可视化分析,最多可以显示 200 个单词。对《三国演义》全文内容进行词云分析, 效果显示如图 3 所示,代码如下 :
from wordcloud import WordCloud
wordcloud=WordCloud(font_path='msyh. ttc',background_color='white').fit_words(word_c)
plt.imshow(wordcloud)
plt.axis('off')
wordcloud.to_file(' 词云 1.jpg')
plt.show()
在 Python 中制作词云时,可以使用遮罩(Mask) 来控制词云的形状。遮罩是一个与词云大小相同的黑白 图像,其中的白色区域表示词云应该出现的地方,而 黑色区域则表示词云不应该出现的地方。词云显示通过 Mask 参数,可以从指定路径下读取图片,并通过背景 轮廓生成词云图,可以大大提升了词云图的趣味性和用 途方向性 [5]。如图 4 所示是根据词频生成的指定形状的 词云图。
from wordcloud import WordCloud
import imageio
mask=imageio.imread('hose.png')
wordcloud=WordCloud(font_path='msyh. ttc',background_color='white').fit_words(word_c)
plt.imshow(wordcloud)
plt.axis('off')
wordcloud.to_file(' 词云 2.jpg')
plt.show()
2 结论
本文采用 Python 对《三国演义》一书进行文本数 据分析,并通过柱形图和词云来展示处理后的结果。这 种可视化的方式既能激发读者的兴趣、感受小说的魅 力,又能提高读者快速概览小说、理解小说脉络的能 力。同时,柱形图与词云能够突出重点,帮助读者明确 文章中的关键人物以及重要事件。这种别具一格的阅读 方式丰富了读者的阅读体验。
目前正处于信息爆炸的时代,基于 Python 进行文本数据分析可以为我们带来许多帮助。通过可视化数 据,我们可以更加直观地了解数据,并识别出不同变量 之间的关系和趋势,有助于我们更好地理解文本,并发 现新的见解。我们希望更多人能够利用这个工具,发掘 文本数据中隐藏的信息和价值,从而促进科技创新和社 会进步。同时,我们也需要更加注重数据的隐私和安全 问题,在尊重个人隐私的前提下,合理地利用文本数据 进行分析和应用。未来,我们期待使用 Python 进行文 本数据分析的技术能够不断发展和完善,为我们带来更 多的可能性和机遇。
参考文献
[1] 徐博龙.应用Jieba和Wordcloud库的词云设计与优化[J].福 建电脑,2019.35(06):25-28.
[2] 汪言.基于Python的词云生成及优化研究— 以“十四五” 规划为例[J].电脑知识与技术,2021.17(19):23-28.
[3] 何冠辰.人工智能与中文分词的研究[J].中国新通信,2019.21 (04):66-68.
[4] 潘亚星.基于Python的词云生成研究— 以柴静的《看 见》为例[J].电脑知识与技术,2019.15(24):8-10.
[5] 潘琴.基于Python的词云生成与分析探究— 以《围城》 文本数据分析为例[J].中小学电教,2023(Z1):149-151.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/61967.html