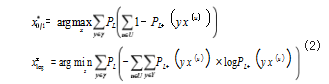SCI论文(www.lunwensci.com)
摘 要:在互联网技术创新和移动互联网深度普及中,社交网络平台作为目前人们获取和传播信息的有效途径,用户数量 一直呈现直线上升趋势。现如今,人们对社交网络平台的依赖性越来越高,甚至有不少人将其看作获取信息资讯的首选。但是 在进入大数据时代后,社交网络平台充斥着大量虚假信息,并由此造成了一系列社会问题。因此,本文在了解当前社交网络平 台发展现状的基础上,根据人工智能检测虚假用户的优势和挑战,提出了以双层采样主动学习为核心的社交网络虚假用户检测 技术。最终实验研究结果证明,主动学习策略能更快识别社交网络平台中的虚拟用户。
False User Detection Technology Based on Target Terminal and Social Data
HAN Yu
(Guangdong University of Technology, Guangzhou Guangdong 510000)
【Abstract】: In the innovation of Internet technology and the depth of the popularization of mobile Internet, the social network platform, as an effective way for people to obtain and spread information, the number of users has been showing a straight upward trend. Nowadays, people are increasingly dependent on social network platforms, and many people even regard them as the first choice for obtaining information. However, after entering the era of big data, social network platforms are filled with a lot of false information, which has caused a series of social problems. Therefore, on the basis of understanding the current development status of social network platforms, this paper proposes to detect and detect fake users with dual sampling active learning based on the advantages and challenges of the AI. Final experimental results show that active learning strategies can identify virtual users in social network platforms faster.
【Key words】: social network platform;fake users;detection technology;social data;target terminal
0 引言
社交网络的飞速发展虽然为用户提供了便捷渠道, 但开放的网络环境加剧了虚假用户和虚假信息带来的影 响,直接威胁着网络系统运行的稳定性和安全性,因此 各国学者在实践探究中提出运用人工智能进行检测分析。 现如今,研究社交网络虚假用户的检测技术,主要是从 基础信息、行为特征、网络关系等方面入手分类用户, 但是因为人工标注用户数据需要消耗大量时间,所以导 致分类器可以使用的标签样本并不多。本文研究在了解 人工智能检测优势的基础上,提出了以双层采样主动学 习为核心的社交网络虚拟用户检测技术,并利用社交数 据验证技术的应用价值。
1 人工智能检测虚拟用户的发展现状
1.1 技术优势
普通用户无法准确辨别网络海量信息的真实性和完 善性,在社交网络平台极容易受到欺骗或误导,因此学 术界在整合实践累积经验的基础上,提出运用人工智能 新技术构建自动监测框架,以此检测网络系统中的虚假 用户,有效治理违规违法的数据信息。在 2021 年 3 月, 美国兰德公司官网发布了《构建基于人工智能的反虚假 信息框架》,重点研究了人工智能在检测网络虚假信息中 的优势和挑战,并为构建反虚假信息全新机制提出了建 议。同年 5 月,长期研究人工智能检测虚假信息技术和 产品的欧洲知名企业,在大数据研究门户网站中发布了《大数据和人工智能如何助力解决假新闻和虚假信息问 题》,从技术层面探讨了应用大数据和人工智能消除虚假 信息的技术进展和相关问题 [1]。
1.2 面临挑战
目前普遍缺少可以管理人工智能模型和解释更深层 策略的技术专家,这不利于新时代下社交网络平台的进 一步发展。根据上述问题分析可知,以目标终端和社交 数据为核心的虚假用户检测技术将会面临以下挑战 :首 先,在检测文本线索时要建模,以此准确获取和区分人 类发布或机器生成的内容 ;其次,要逐步优化视觉内容 编辑和处理技术,配备最尖端的计算机设备、语音识别、 多媒体分析技术等,从而判断虚假用户是否存在剽窃等 不良行为 ;最后,要遏制虚假信息的生产和传播,利用 先进人工智能模型自动理解视觉内容,以此在自我学习 训练中,提高人工智能设备的应用水平 [2]。
2 基于目标终端与社交数据的社交网络虚假用户检测技术
2.1 主动学习
这项策略主要是解决当前社交网络平台中标签数据 不充足、标注数据时间过长的问题。与被动学习模式相 比可知,主动学习的应用策略会在控制分类器的基础上, 选择输入所需样本。在没有标记样本的情况下,会选择 信息量更高的数据内容,有效提高整体学习效率和质量。 按照选择没有标记样本方式的差异,可以将主动学习策 略分成 3 种形式 :首先是指成员查询综合 ;其次是指以流 为核心的主动学习 ;最后是指以池为核心的主动学习 [3]。 其中,目前应用最广泛的就是以池为核心的主动学习策 略,根据选择没有标记样例的标准进行划分,又包含以 不确定性为核心的采样策略、以模型改变期望为核心的 采样策略、以版本空间缩减为核心的采用策略、以误差 缩减为核心的采样策略。
假设fθ 代表以梯度为核心的学习模型, L 代表原有 的训练数据结合, ∇fθ(L)是指学习模型在参数 θ 时的梯 度, ∇fθ(L ∪ (x, y))是指新加入的标记样本学习模型的梯度。这种算法可以利用如式(1)所示的公式选择样本 :
在公式(1)中,∗ 代表梯度相量在欧式空间中的长度。
以误差缩减为核心的采用策略,会在有效控制分类 器数量的基础上,优化算法的泛化水平。这项算法策略 的操作步骤为 :在有效标记每一个没有标记样本进行后, 全部添加到训练集合中,重新训练分类器,整合分析数 据误差发生的变化,由此利用最大程度有效控制分类器 的误差 [4]。假设 L 代表原本的训练数据集合, L+=L+(X.Y) 代表加入样本(x, y)之后的数据集合,因为样本的标签是不确定的,所以要对所有取值进行概率化,以此得 到 0/1 误差和 log 误差函数下的选择标准, 具体计算公 式如式(2 所示 :
2.2 检测模型
本文研究从目标终端和社交数据入手,利用双层采样 主动学习算法,首先利用少量的标签,在构建用户训练集 合的基础上,得到初始化的分类器 ;其次,要在熟练运用 分类器的条件下,准确判断没有标记数据集合中包含的用 户标签,并结合双层采样的学习算法,获取没有标签的用 户数据, 以此得到价值最大的多个用户 ;然后, 再利用人 工标注的方式标注标签,并将其融入到训练集合中,重新 学习一个全新的分类器 ;最后,要重复上述操作,一直到 无法提升分类其性能为止。从整体操作过程来看,双层采 样主动学习策略的第一层采样, 会将样本的代表性和不确 定性,看作评价样本的主要标准。从实践应用角度来看, 样本的不确定性,可以直接利用主动学习策略获取,而样 本的代表性要结合密度进行评估分析, 且在第二层需要对 候选样本进行聚类分析, 而后以簇为单位重新排列样本的 不确定性,选择出价值最大的没有标记的样本 [5]。
在了解传统主动学习策略概念的基础上,根据离群 点的问题,运用样本代表性度量相应价值,基于加权算 法让样本的不明确性和代表性有机结合到一起,以此得 到具有代表性和不明确性的采样方式(SUR),具体定义公式如式(3)所示 :
SUR (x )= α× H (x )+ ( −α)×AS (x ) (3)
在公式(3)中, H 代表样本x 的信息熵, AS (x)是指样本x 的代表性, SUR (x)是指不明确性和代表性的加权数值, α 代表加权系数,且符合α ∈ (0.1)这一条件。
如果α = 1 ,那么算法就是只考虑样本代表性的主动学习 采样模式,但若是 α = 0 ,那么就是以不确定性为核心 的采样算法。
而样本的代表性可以充分展现数据集合当中样本与 其他样本之间的相似度。在本文研究实验中,主要运用 密度探讨样本的代表性,结合皮尔森相关系数计算分析 彼此之间的相似度,相应公式如式(4)所示 :
在上述公式中, rp (xi , xj )代表两个向量的皮尔逊相 关系数, sim(xi , xj )代表标准化到区间的用户相似度, S(x)= {s1 , s2 ,..., sK }代表和用户x 相似度较高的 K 个样本。
3 结果分析
首先,在实验研究中,主要对比分析本文提出的 SUR、DDTLS 算法与监督型机器学习算法。这两种算法 的精确度可以达到监督型机器学习算法 ;实验期间利用 支持向量机模型作为基础的分类算法,初始的标签样本 数设定为总体样本数量的 1%,每次迭代选择的新样本数 是总体的 1%。最终实验结果显示,在 Twitter 数据集合 和 Youtube 数据集合达到总体样本的 15% 之后,分类 器的各项性能将趋向于稳定性 ;在 Apontador 数据集合 中的结果显示,达到总体样本的 60%,分类器的各项性 能将会趋向于基本稳定,只会出现小幅度的波动,这就 证明在社交网络平台中运用主动学习算法,可以准确识 别标签、账户不充足等问题。对比分析准确率、召回率、 稳定数值可以发现,本文研究的 SUR、DDTLS 这两种 算法要比其他主动学习方法更加有效,分类器的性能影 响更快。尤其是在召回率指标中, DDTLS 算法地提升非 常明显,这就证明第二层的距离算法可以有效保障样本 集合的多样性,控制信息的冗余,以此提高分类器的泛 化能力。
最后,分析参数的敏感性。这部分主要探讨双层采 样模型的参数敏感性,模型中等待确定的参数有很多, 在实验分析中要运用信息熵计算样本的不确定性,将逻 辑回归模型作为基础分类算法。最终结果显示,初始样 本数据对实验结果并没有构成影响,为了降低人工标注 的成本支出,在实验期间要优先选择更少的初始样本, 即初始样本数量是 10.可以达到样本总数的 1%[6]。
4 未来社交网络平台虚假用户的检测发展分析
4.1 技术进展
在近几年技术科研探讨中,人工智能研究取得了重 要进展, 可以有效缓解部分挑战压力。其中, 阿尼尔 • 班达卡威在研究中提出,大数据在数据处理和采样方面 取得了创新成果,找到了可以有效提取相对较小、但包 含所有关键模式和信号的代表性数据样本的有效方法, 既提高了人工智能的洞察力,又降低了算力的需求。同 时,应用全新模型进行压缩和知识提炼策略,可以降低 人工智能创造的复杂性, 且不会影响实践应用的精度 [7]。 另外,目前科研学者已经可以建立和运行更加先进的人 工智能集成系统,快速抓取和处理无穷尽的数据流,提 炼更加精准地判断信息,熟练掌握影响范围、内容可信 度等因素,并自主分析虚假信息背后的关联性。
4.2 关键路径
为了有效遏制当前社交网络平台,虚假用户和虚假 信息持续泛滥的发展趋势,持续探讨人工智能在社交网 络平台中的检测功能,自己研发相应的技术方案,是各 国学者探讨的主要问题。有学者在研究中提出,运用人 工智能检测虚假用户,要重点关注政府主管部门的积极 作用,注重制定有效的解决对策 :首先,要科学协调人 工智能企业和平台运营企业,优先开发和应用快速识别 社交网络平台,虚假用户的先进模型 ;其次,公共平台 和私营机构要建立以用户为中心的发展原则,适当开展 数字技术的科普培训活动,以此提高用户对社交媒体虚 拟信息的认知判断能力 ;最后,在构建以人工智能为核 心的反虚假信息框架时,要注重提升整体框架的组织管 理能力 [8]。
5 结语
综上所述,在本文研究中,社交网络平台中的标签 用户数量较少,人工标注用户的时间较长,提出以双层 采样主动学习策略为核心的虚假用户检测框架,第一层 会在没有标记的样本空间中,选择不确定性较大且代表 性较高的部分样本 ;在第二层会利用聚类重新排序选择 样本集合整体多样性较高的样本进行人工标注,标注之 后可以为后续训练分析提供有效依据。最终实验结果证 明,这种虚拟用户的检测方法符合当前社交网络平台的 运行需求。
参考文献
[1] 王莉.网络虚假信息检测技术研究与展望[J].太原理工大学 学报,2022.53(3):397-404.
[2] 谭侃,高旻,李文涛,等.基于双层采样主动学习的社交网络虚 假用户检测方法[J]. 自动化学报,2017.43(3):448-461.
[3] 吕成戍.基于双重欠采样代价敏感学习的推荐系统虚假用户 检测方法[J].系统科学与数学,2021.41(12):3548-3558.
[4] 方勇,刘道胜,黄诚.基于层次聚类的虚假用户检测[J].清华大 学学报(自然科学版),2017.57(6):620-624.
[5] 张东杰,黄龙涛,张荣,等.基于主题与情感联合预训练的虚假 评论检测方法[J].计算机研究与发展,2021.58(7):1385-1394. [6] 曲强,于洪涛,黄瑞阳.社交网络异常用户检测技术研究进展 [J].网络与信息安全学报,2018.4(3):13-23.
[7] 杨超,项振辉,李涛.基于DCA算法的微博虚假信息检测[J]. 计算机测量与控制,2019.27(3):183-187+191.
[8] 曹东伟,李邵梅,陈鸿昶.基于GCN的虚假评论检测方法[J]. 计算机工程与应用,2022.58(3):181-186.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/61243.html