SCI论文(www.lunwensci.com)
摘 要:万维网(下文简写 WWW) 动态文档是浏览器访问万维网服务器时由应用程序临时生成的文档, 是万维网资源 中最有价值的部分。为了实现对动态文档中数据的爬取,研究动态文档的生成逻辑分析。在给出万维网原理和分析工具的基础 上,提出对动态文档请求和动态文档源码进行分析的一般方法。实践证明,该方法可有效地指导动态文档爬虫程序的设计。
Analysis of Crawling World Wide Web Dynamic Document
XU Tianhao1. WANG Ziyang2. SHEN Hao1. SUN Meifeng1
(1.Guangling Collage of Yangzhou University, Yangzhou Jiangsu 225000;
2.Yangzhou Baoyang Digital Technology Company, Yangzhou Jiangsu 225000)
【Abstract】: World Wide Web(Abbreviation: WWW) dynamic document is the document generated by the application temporarily when the browser accesses the WWW server. It is the most valuable part of the WWW resources. To crawl the data in the dynamic document, you need to understand and simulate how the dynamic document is generated. Based on the principle of WWW and analysis tools, a general method for analyzing dynamic document request and dynamic document source code is proposed. A lot of practice has proved that this method can effectively guide the design of dynamic document crawler.
【Key words】:Web crawler;dynamic document;WWW
0 引言
网络爬虫是一种按照一定规则,自动获取 WWW 文档中信息的程序或者脚本,其很早就在搜索引擎中得 到应用。近年来,随着对在线数据深度分析和利用的兴 起 [1.2],对爬虫技术的研究和应用成为热点 [3.4]。
文献 [5] 将 WWW 文档分为动态文档和静态文档。 其中,动态文档是在浏览器请求 WWW 服务器时才由 应用程序临时生成的文档,内容随请求参数的不同而不 同,表现出动态性 ;静态文档则由网站的内容提供者创 作后存放在 WWW 服务器中的文档,除非人为修改,内 容不会发生改变。据 BrightPlanet 公司技术白皮书 [6], 在 2000 年,主要由动态文档组成的深层 Web 资源容量 与主要由静态文档组成的表层 Web 资源容量的比值已经达到 500 倍,而且有价值的信息资源主要存在于动态 文档。这些年各种互联网应用都表现出向 WWW 访问 方式迁移的特征, WWW 世界的有价值资源主要分布 在动态文档的情形只会更甚,因此研究动态文档的爬取 具有实际价值。
另一方面,爬取动态文档难度大。静态文档是 URL 可直达的文档,爬取时提供正确的 URL 即可 ;而 动态文档的 URL 指向的是应用程序,应用程序如何生 成文档并没有规定,完全取决于程序编写者,因此爬取 动态文档需要理解应用程序生成该动态文档的逻辑,既 麻烦又专业,而且对一个应用的爬取方法不能套用到另 一个应用,这一点从相关文献所针对的某个具体网站亦 可看出 [4.7.8]。
本文对爬取动态文档时面临的关键且困难的问题即 动态文档的生成逻辑分析进行研究,在大量动态文档爬 取实践的基础上,提出对文档请求和文档源码的分析方 法,可为同类工作提供有价值的参考。
1 工作基础
1.1 WWW 原理
WWW 文档是保存在 WWW 服务器中,由 WWW 服务器程序管理并经由浏览器程序对外发布的文档资 源。要想越过 WWW 事先规划好的方式获得文档,必 须首先弄清楚其内部工作机理。
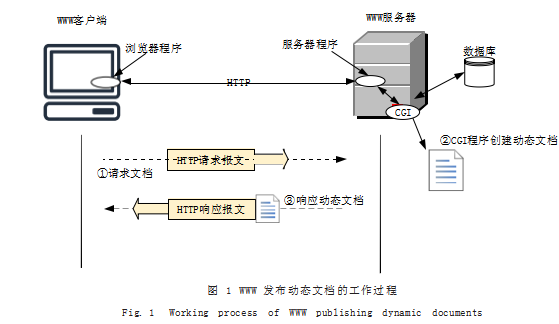
如图 1 所示是 WWW 发布动态文档的工作过程示 意图。浏览器程序(简称浏览器)与 WWW 服务器程序 (简称 WWW 服务器或服务器)按照 HTTP 协议规则交 互 :第一步,浏览器向 WWW 服务器发出 HTTP 请求报 文以请求文档 ;第二步, WWW 服务器从 HTTP 请求报文 发现请求资源是一个 CGI 程序,就调用相应的 CGI 程序创 建动态文档 ;第三步, WWW 服务器将 CGI 程序返回的 文档封装在 HTTP 响应报文中返回浏览器,浏览器将其 显示在窗口中。HTTP 协议是一个无状态协议, 服务器 返回什么只取决于本次请求,而与它过去的请求无关。
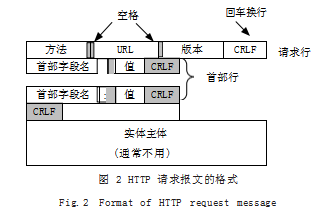
如图 2 所示是 HTTP 请求报文的组成。对于请求文 档为动态文档的情形, URL 指向的是创建该文档的 CGI 程序,程序参数有两种传递方法 :“GET”和“POST”。 “GET”方法将参数以“? 变量名 = 值 & 变量名 = 值 &……” 形式附在 URL 的后面,由于 URL 长度受限,一般用于参 数数量少且简单的情形 ;而“POST”方法将参数封装在 请求的实体主体位置,参数数量不受限且隐蔽性好。首 部行是对浏览器和报文主体的一些说明信息,俗称请求头,用于向 CGI 程序说明请求环境。
1.2 WWW 分析工具—浏览器的开发者工具
当前每一款浏览器都包含一套强大的开发工具套 件,或内置于浏览器或作为浏览器的附加组件。该工具 能够捕获浏览器与 WWW 服务器之间的所有交互报文, 其“网络”监视器功能可以用来查看捕获报文的详细信 息,而其代码“查看器”功能则可以用来检查当前页面 的 HTML 源码,显示各标签元素在页面中的呈现,该 工具对动态文档的爬取分析提供了完美支持。
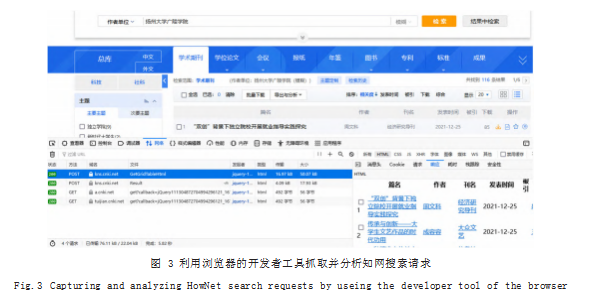
如图 3 所示是在清空缓存的情况下,以作者单位、 出版年度为关键字搜索知网论文时(结果随搜索条件不 同而不同,典型的动态文档),利用火狐浏览器的开发 者工具截获浏览器发送给 WWW 服务器的所有请求, 并在网络监视器功能下查看请求文档类型为 HTML 的 结果。可发现本次访问中浏览器向 WWW 服务器共发 出了 4 个 HTML 文档请求,左侧的窗口列出了请求的 概要信息,包括请求结果(状态)、方法、域名、URL, 以及请求文档的类型、大小和实际传输大小。选中一个请求,右侧窗口便给出该请求的详细信息,包括 :消息 头、Cookie、请求(参数)、响应(文档)等。
如图 4 所示是利用火狐浏览器的开发者工具的代 码查看器功能,查看知网搜索结果页源码的效果。当 把鼠标移到源码中某一标签元素上,页面相应区域便 会突出显示(比如图 4 中鼠标停在 "……" 标签,论文区域突出显示),由此可确 定爬取信息在源码中的位置。
2 动态文档请求的分析
根据 WWW 原理, WWW 服务器返回响应的依据 是浏览器发送给它的本次请求,因此爬取到动态文档的 关键是,构造出与文档对应的 HTTP 请求。
2.1 请求 URL 和方法的分析
由于 WWW 的超连接特性,展现在浏览器窗口的 一幅图文并茂的页面,通常由大量类型不同的文档资源 组成, 如 HTML、CSS、JS、JSON 文档以及图片文件等。在打开浏览器开发者工具的条件下,人工访问动态 网页,开发者工具将抓取到组成该网页的所有文档的请 求,显示在网络监视器中。为了确定爬取信息所在的 请求,分析者可事先评估一下动态文档类型(一般是 HTML 文档或 JSON 文档),筛选出相应类型请求,逐 个选中这些请求并查看其“响应”一栏的内容,找到包 含爬取信息的响应(文档),请求 URL 和方法便随之 确定。按此方法对图 3 中以作者单位、出版年度为关键 字搜索知网时抓取的 HTML 文档请求进行查看,发现 第一个请求的响应便是搜索结果页面中的论文列表。至 此,若爬取目标是知网搜索结果,则已经找到了需要模 拟的 HTTP 请求。点击该请求的“消息头”标签,最 上面一行“POST https://kns.cnki.net/KNS8/Brief/Get GridTableHtml”即为请求 URL 和方法。
2.2 请求头的分析
前文已述, HTTP 请求报文包含若干首部行,用来说明请求的环境信息。可如图 3 所示选中一个请求后,点 击“消息头”标签,查看请求的首部字段及值。归纳起 来, HTTP 请求的首部字段分成 3 种类型 :(1)浏览器的 说明字段, 如 User-Agent、Accept、Accept-Language、 Accept-Encodeing、Connection-Alive 等。(2) 构造请 求时实时计算的字段,如 Content-Length、Date 等。(3) 应用环境说明字段,这些字段的值由服务器端的文档内 容决定,因此反映了请求的应用环境,包括 Content-Type、 Referer、Origin、X-Request-With、Cookie 字段等。
构造 HTTP 请求时,哪些字段必须被赋予限定的 值,否则将影响动态文档的获取呢?实时计算类型的名 字本身就说明服务器端接受这些字段的值的变化,因此 最不可能被限定,基本可以忽略。从 WWW 资源一方 的角度,对请求行为具有隐含的期望 :通过浏览器进行 (是浏览器便可, 不限定什么浏览器以及浏览器的具体 特性), 且被请求文档与请求的来源文档关系服从开发 者的安排。这意味着,具有反爬意识的网站开发者在创 建动态文档的 CGI 程序中可能检查并限定浏览器说明 字段中的“User-Agent”以及应用环境说明字段以保 证当前请求符合预期。相应地,爬取的时候就要特别关 注这些字段,将其伪装成用户访问时的值。
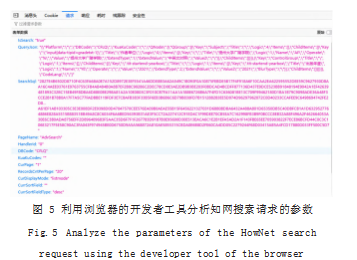
到 ;而“POST”方法将参数封装在请求的实体主体位置, 需在浏览器开发者工具的网络监视器下, 选定一个请求 后点击“请求”标签进行查看。无论是“GET”方法还是 “POST”方法,在观察到人工访问请求的参数后,结合请 求的背景信息,分析者一般能够推断出参数项的含义。比 如,如图 5 所示是以“‘作者单位’=‘扬州大学广陵学院’ 且‘出版年度’=‘2021’”为条件在知网中搜索学术期 刊时所得结果的第 3 页对应的 POST 请求参数,容易看出 “CurPage”是当前页数, “RecordsCntPerPage”是每页的 记录数, 而“QueryJson”是查询条件等。在构造 HTTP 请求的时候,一般需要保持参数项不变,同时针对爬取 目标重新设置某些项的值。比如,如果爬取目标是“扬 州大学 2021 年度的出版论文”, 只需将“QueryJson” 参数值中的“扬州大学广陵学院”替换成“扬州大学”。
然而,具有反爬意识的网站开发者可能使用动态参 数,使爬取变得复杂。比如,机械照搬图 5 中的知网搜 索请求的参数并不能实现对搜索结果的成功爬取。经分 析和测试,发现“SearchSQL”是一个动态参数,对搜 索结果的第一次请求并未使用它,可是后续的每一次请 求都包含该参数且其值隐藏在请求的来源文档的表单项 “input[id=sqlVal]”中。雅学网的搜索功能触发的请 求“POST http://www.yaxue.net/CSDXSearch.aspx” 中也使用了同样方法。该请求包含 3 个动态参数“__ VIEWSTATE”“__VIEWSTATEGENERATOR”“__ EVENTVALIDATION”, 均隐藏在其来源文档即搜索页 文档的表单项中。
网站开发者还可利用 JS 程序进一步增加爬取的难 度。比如,在爬取雅学网搜索结果时, “下一页”指向 的请求中携带一个参数“__EVENTTARGET”,虽然该 请求的来源文档确实存在“id=__EVENTTARGET”的 表单项,但是参数值却不是该表单项的直接值,而是与“下一页”元素关联的一个 JS 函数的运行结果。
总之,当发现某个请求参数是动态参数时,可到来 源文档中寻找该参数的正确取值,可能存在一个隐藏的 表单项为它赋值,也可能存在一段 JS 程序计算它的值。
3 动态文档源码的分析
在爬取到动态文档之后,接下来的任务是分析爬取 内容在文档中的位置,以便编程提取。利用浏览器开发 者工具的代码查看器功能,按照图 4 所示的操作方法, 此任务可轻松完成,但也可能出现意外。比如,本文作 者在分析知网的论文详情页源码时,发现作为通讯作者 标识的信封图标是源码中 "" 元素的呈现 ;然而在爬取到的论文详情页文档的通讯作 者位置却找不到该元素,导致提取通讯作者失败。研究 发现,这个元素是文档加载事件的处理程序添加的。总 之,爬取数据在文档中的存在形式或者是直接元素,或 者 JS 程序生成,沿着这两个方向总能分析得到爬取内 容的提取方法。
4 结论
各种对在线数据的分析和利用首先要求自动获取到 数据。由于对应用程序如何生成动态文档没有统一规 定,以及网站开发者反爬意识的提高,爬取动态文档是 一项富有挑战性的任务。本文在深入研究 WWW 原理常用的应用环境说明字段解释如下 :Content-Type 代表请求携带的实体数据格式 ;Referer 代表请求的来 源,即触发本次请求的网页 URL ;Origin 表明请求来自 于哪个站点,只有跨域请求或同域 POST 请求包含此字 段 ;X-Request-With 表明请求是传统的 HTTP 请求还是 来自 Ajax 的异步请求 ;Cookie 字段作为 HTTP 无状态 特性的补充手段,用于在不同程序之间传递信息。具体 方法是服务器端的一个程序将需要传递的数据通过响应 报文的 Set-Cookie 字段返回浏览器并保存在客户机中, 后续浏览器发出的每个请求自动将客户机中的 Cookie 数据赋给 Cookie 字段,又传回服务器,其他程序便可 获得该数据。
本文作者爬取过的大量网站中,请求头中使用最为 普遍的是“User-Agent”字段 ;只有个别反爬意识较 强的网站结合使用了“X-Requested-With”“Content- Type”“Origin”“Referer”字段 ;而各种要求登录的应 用型网站,则全都使用了 Cookie 字段,保证仅当用户 通过登录验证才能访问业务数据。
2.3 请求参数的分析
正如前文所述,对动态文档的请求本质是对 CGI 程 序的调用,请求中携带了程序参数, “GET”方法将参数 附在 URL 的后面,因此在分析请求 URL 的时候便可得的基础上,总结大量动态文档爬取的实践经验,形成一 般性分析方法,可为相关工作提供参考。
参考文献
[1] 黎睿臻,吴永萌,支锦亦.基于网络评论数据的无线耳机舒适 性研究[J].机械设计,2020.37(9):134-139.
[2] 刘德喜,聂建云,万常选,等.基于分类的微博新情感词抽取方 法和特征分析[J].计算机学报,2018.41(7):1574-1597.
[3] 沈承放,莫达隆,黄文韬.网页数据采集算法及在住户调查中 的应用[J].统计与决策,2021.37(7):52-56.
[4] 曾健荣,张仰森,郑佳,等.面向多数据源的网络爬虫实现技术 及应用[J].计算机科学,2019.46(5):304-309.
[5] 谢希仁.计算机网络(第8版)[M].北京:电子工业出版社,2021: 272-288.
[6] BERGMAN M K.The Deep Web:Surfacing Hidden Value[J].J Electronic Publishing the University of Michigan, 2000.50(1):476–481.
[7] 孙美凤,宋晨,王颖.基于PHP的百度贴吧数据爬取[J].软件, 2020.41(11):23-26.
[8] 吴嘉兴,王玉龙,孙美凤.面向科研统计的机构发表论文数据 的爬取— 以知网为例[J].软件,2022.43(12):31-35.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/58680.html