SCI论文(www.lunwensci.com)
摘 要 :随着社交平台的广泛应用,聊天文本数量增长迅速。要对如此庞大的群体进行分析,现有的系统和技术无法进行 准确的计算和设计。平台现有的算法存在很多不合理的地方,相应的数据分析体系不完善,不能给用户带来最舒适的体验。这 已成为当前社交平台面临的一个主要问题。针对上述问题,本文对基于微博大数据的文本情感倾向性分析构建算法模型,并进 行科学的数据分析和高维研究。本文比较了支持向量机(SVM)、RNN 和 CNN。研究结果表明,支持向量机(SVM)具有时 间效率,生成的关联规则数与 RNN 和 CNN 算法相同。数据量越大, RNN 和 CNN 的时间效率就越高。当数据量为 10 万时, 利用本文的数据模型得到的准确率高达 92.78%,这为社交平台的文本情感倾向性分析提供了依据。
Neural Network Analysis of Text Sentiment Bias in Big Data
WEI Qunfeng, QI Bin
(College of Electronic Information, Zhejiang Business Technology Institute, Ningbo Zhejiang 315010)
【Abstract】:With the widespread use of social platforms, the number of chat texts has grown rapidly. To analyze such big data, the existing systems and technologies cannot perform accurate computation and design.The existing algorithm of the platform has many unreasonable places, and the corresponding data analysis system is not perfect, which cannot bring the most comfortable experience to users. This has become a major problem facing social platforms today. In view of the above problems, this paper builds an algorithm model for the analysis of text emotion tendency based on micro-blog data, and carries out scientific data analysis and high-dimensional research. This paper compares the Support Vector Machine (SVM),RNN and CNN. The results show that the SVM is time- efficient and generates the same number of association rules as the RNN and CNN algorithms. The larger the data volume increases the time efficiency of the RNN and CNN. When the data amount is 100.000. the accuracy rate is 92.78%. This provides a basis for the analysis of text emotion bias on social platforms.
【Key words】:big data;neural network;word segmentation;Word2vec
引言
当前我国信息技术正处于快速发展的阶段,推动着 社交平台的同步快速发展。然而,我国的社交平台大部 分停留在社交本身的阶段,对于用户的数据分析的算法 还有待提升。近年来,将对社交平台上用户的行为进行 大数据分析作为重点突破的技术目标。虽然越来越多的 算法和数据进入了社交平台,但整体整合程度并不高。 很多数据都是无用的,往往只能做一些简单的分析,也消极负面的情绪时,仍采用后台机器审查加人工审核, 审核效率低,难以保证数据的真实性和准确性。通过这 些收集到的数据,更无法为部分负面情绪的用户提供必 要的关怀。为了进一步了解和分析社交平台上用户的文 本倾向性分析的算法设计,本文将基于社交平台大数据 对用户的行为设计模型的构建进行了分析。
近年来,社交平台的快速发展使许多学者对社交平 台上用户的行为分析算法的设计进行了研究。现有的研究方案中, 大多都是以神经概率语言模型与预训练语言模型作为深度学习与自然语言处理结合的切入点, 并对 模型中的参数进行优化,从而提升准确率 [1]。张忠林等 人提出了注意力卷积神经网络条件随机场模型 (Attention Convolutional Neural Network CRF,ACNNC), 解 决 了现有中文分词模型大多是基于循环神经网络的,只能 捕捉序列整体特征,但存在忽略了局部特征的问题 [2]。 胡吴天等人探究了融入领域知识的机器学习模型 CRF、 深度学习模型 Bi-LSTM-CRF 和预训练语言模型 BERT、 RoBERTa、ALBERT 在非遗文本上的分词性能,并对 比了通用分词工具 HanLP、Jieba、NLPIR 的效果,对 特定的中文语料分词性能做了对比,得到了最高的召回 率 [3]。杨旭华等人利用 Mix-GCN 模型提升了文本分类 性能, 在 6 个基准数据集上与 8 种知名文本分类方法进 行了比较,得到的文本分类效果非常好 [4]。有学者利用 语音信号的识别,通过计算扩展噪声干扰数据的权重, 提出自然语言交互中语音信号识别方法 [5]。然而,这些 研究只停留在某个节点上,并没有将分词后的结果用于 具体的项目中,很难找到研究的成果适用其本质。因 此,有必要从分词后的效果进行分析,并应用到社交平 台上的情感倾向性上,协助平台对用户进行研究和分 析,更加有效为用户服务。本文的创新之处在于 :(1) 比较了传统的支持向量机(SVM)、RNN 和 CNN 算法 ; (2)利用本文改进的算法对各算法进行了关联规则挖掘 和比较,得到了更高效率的算法模型。
1 基于神经网络的文本情感倾向性分析原理
利用爬虫可以从微博等类似社交平台进行数据爬 取,并将文本进行数据预处理。进行预处理的目的主要 是为了避免爬取的数据中存在大量的语气词或者其他的 噪声,在后续的文本情感倾向性分析的时候影响其准确 性。数据预处理主要是对初始文本进行比如数据清洗、 删除与情感分类无关的文本或者情感分类存在干扰的文 本 ;接下来是文本分词,利用 Jieba 或者其他的库将用 户在社交平台的文本语料分成词语,以便于接下去将影 响文本情感分类的词进行停用词标记,去除对应的特殊 字符,再转化成词向量等一系列的操作。
1.1 数据清洗
对于社交平台爬取的用户行为语料,会包含很多对 于文本情感倾向性分析无用的语料。一般来说,发布动 态的语句的开头、语句中的超链接、用户转发其他人的 动态、或者利用 @ 关联相应用户,这些为后续处理中 文语料分词和特征提取带来很大的干扰,在进行中文语 料分词的时候带来不可预料的错误,最终会致使这些中 文语料样本无法满足需要,也无法处理成有效的词向量,中文语料文本特征提取的时候大概率会由于会出现 很多干扰信息使得算法无法进行下去。综上所述,爬取 的中文语料库一定要经过数据清洗后,变成有效的中文 文本,在进行数据清洗的时候,还需要使用正则表达式 对相应的词语进行快速精确的匹配,如表 1 所示。
在程序设计过程中,为了快速匹配到相应的中文语 料,利用正则表达式可以非常高效地实现所需的结果。 正则表达式中,利用中括号来表示其中的一个字符满 足某种条件。在对社交平台中的用户行为文本进行分析 时,可以发现,有 3 种文本需要着重处理 :(1)是 @ user_name 提到,这种情况主要是提到某用户,或者 某位用户参与了该用户的行为。可以利用正则表达式 @[^\\s]+,此表达式中, @ 打头,代表需要从 @ 开始 删除, 当遇到空格后就会停止 ;(2) 是“回复 @user_ name :评论”,回复某位用户的内容。无效的数据主要 是用户的名字,也就是说,删除了提到的用户的名字就 可以了,刚好到冒号就可以了。对应的正则表达式为 : “回复 @[^ :]+”;(3) 是评论 //@ user-name :评论, 这里是用户在评论其他人的观点,这些数据只能作为客 观的数据参考,不代表用户的主观数据。在处理的时候 要临时删除,正则表达式以“//@”开始,这里涉及到 转义字符, “/”需要“\”进行转换,所以正则表达式为 “\ /\ /@.+MYM”。当然还有其他的种类,比如网址链接 或者用户经常用到的表情符号,也是利用类似的正则表 达式进行清洗处理。处理后的用户行为文本数据如表 2 所示。
1.2 文本分词
在对中文文本进行分析时,需要借助分词算法。它 与西文的主要区别在于,西文表达方式采用的是单词的形 式,每个单词之间都是利用空格隔开的,要比中文简单很 多,也不需要分词算法。但是中文表达本身具有复杂性, 字和字之间没有间隔,还有很多词语或者成语、语气词 等, 导致基本上没有办法在不对文本进行分词的前提下直 接将其转化为词向量的模式。在自然语言处理的领域中,对于中文分词是非常重要的一个环节。根据不同的场景需 要,还要求对分词的效果有所区别。只有设计好了合适的 中文分词算法,才能有效优化模型的具体使用效果。
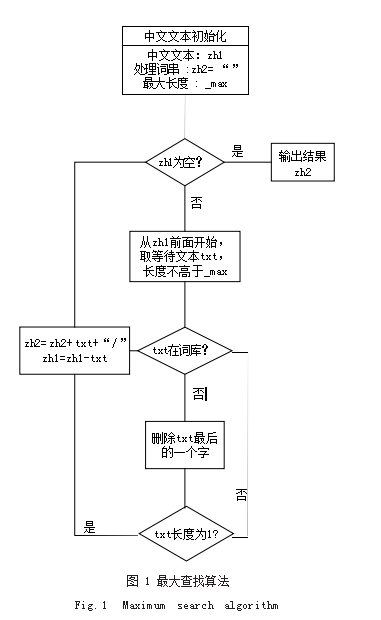
目前在 Python 的模块中,有个Jieba 的库,里面内 置很多算法。本文在处理中文文本分词的时候主要采用以 下两种算法。第一种算法是利用词典或基于规则的分词算 法,这种算法最重要的就是对字符串进行匹配,在编写算 法的时候,提前设定好策略,将需要处理的中文文本与已 知的字符串库进行高效的查找, 一旦查找到相应的中文文 本,就返回相应的结果。这种查找算法有很多种类,比如 根据查找方向来区分的话,又分为二分法查找法、正向最 大查找法、逆向最大查找法这 3 种方法。以正向最大查找 法为例,采用流程图如图 1 所示进行算法的设计。
假设现在要对“明天要去宁波学习”进行中文文本 分词,根据正向最大查找法的原理,从左往右查找后, 进行断句后变成“明天 / 要 / 去 / 宁波 / 学习”。这里可 以发现, “明天”是日期的词语, “宁波”是地理名次, 由此可见这个算法需要一个很强大的词典,否则在中文 文本情感分析中无法得到良好的效果。
本文在对中文文本进行分词的时候为了避免过于依 赖词库,通过数据建模,利用统计学的知识,设计了 机器学习算法。这种算法可以避免在中文文中语境不一 样、表达的具体含义不一样的情景。采用的手法就是将词 语或者成语处理为字符,就好比一个英文单词一样。进行 统计学分析时, 如果某两个字或者几个字同时出现的几率 越高,那么就说明这些这几个字在一起组成词语的概率就 越大。在进行统计学实验时,可以将某两个字或者几个字 同时出现的概率定义一个阈值,如果超过这个阈值,就标 记为一个字符。当前基于统计学分析的机器学习分词算 法流行的模型有隐马尔科夫模型,它的代表库为 imdict- chinese-analyzer、条件随机场模型(Conditional Random Fields,CRF)、最大熵模型(ME)等。
在进行中文分词的过程汇总时,还需要结合现有的成熟的第三方库进行处理,这样可以达到更好的效果。现有 流行的库主要有Jieba、mmseg4j、IK-analyzer、imdict- chinese-analyzer 等。本文结合使用的是Jieba 和 imdict- chinese-analyzer。在进行中文文本分词处理时可以将 出现超过阈值的多个字变成有向的无环图,利用状态 方程找到最优的求解路径,最后结合 imdict-chinese- analyzer 算法,解决处理过程中没有发现的词语。
1.3 噪声去除
将中文文本进行分词后,会出现很多干扰情感分析 结果的词,或者对于结果没有意义的词,在后续的处理 中会影响算法的执行效率的,这些统称为噪声。本文在 处理噪声的过程中,尽量保证算法的鲁棒性,选用了语 气词、连接词、破折号等符号、中文或者罗马数字尽可 能多的停用词等。在社交平台中,利用爬虫算法获取的 专属表情包会自动转化为文本,这些文本有些统一转换 为 [ 图片 ],有些转化为对应的表情文字。这里需要利 用算法进行标记,对于统一转化为的无意义的中文字符
3.2 模型参数
在进行实验过程中,模型的参数非常重要。本文主 要优化调用函数、迭代次数。采用的是控制变量法、对 照法等。
3.2.1 优化函数
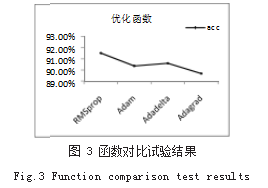
在中文文本情感分析过程中,需要对比不同的函数 实现的效果。这里列了几个函数作为对比,用于在训练 中文文本时构建复杂的神经网络,如图 3 所示。
在模型优化的过程中,发现采用 RMSprop 得到准 确率最高可达到 90.56%。这 4 种函数目前在深度学习中 是非常热门的,各有所长。运用的统计学原理都差不多, 但是对于本文的中文文本案例来说,采用 RMSprop 最好。
3.2.2 迭代更新次数
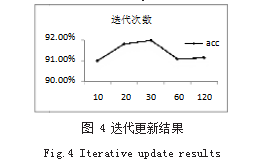
在实验过程中,需要对中文文本数据进行多次迭代 训练,以达到更适应的数据模型。但也仅限在一定的范 围内,因为在数学运算中,次数太多,得到的值会过拟 合,会降低模型预测的正确率,如图 4 所示。
随着迭代次数的不断进行,整个模型的准确率呈先 增加后下降的趋势。迭代次数从 10 ~ 20 的时候,增长 速度最快 ;迭代次数从 20 ~ 30. 准确率缓慢增加, 并 达到最大,从 30 ~ 60 时,开始出现负增长。本文的 迭代次数采用随机值的形式,区间段也选择在平稳的 20 ~ 30 之间。
3.3 实验结果
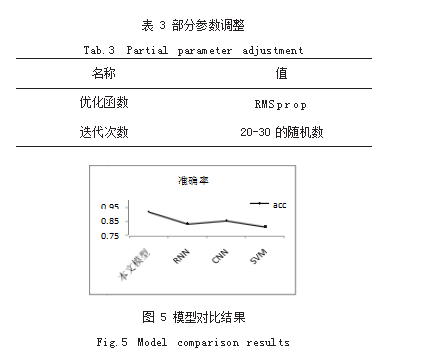
通过上述对部分参数的调整,得到比较优化的参 数,接下去利用对比法进行实验。如表 3 所示是列举的 部分实验参数。
将本文的中文文本数据用不同的模型进行对照实 验,每个模型进行 3 次训练,并求其准确率的平均值。 这里采用的成熟的模型有支持向量机(SVM)、RNN 和 CNN。如图 5 所示,可以发现,利用本文的数据模型 得到准确率高达 92.78%。说明对于模型的使用和参数 的优化都是合理的。本文建立的数据模型更加适用于社 交平台模型的训练。
4 结语
在实际应用过程中存在着很多中文数据集,由于进 行文本特征提取后本身的复杂性和类别信息多样性,诸 如类重叠分布以及掺杂的噪声样本都会在不同程度上影 响准确率,如果基于 Word2vec 特征提取进行有针对性 的数据预处理工作,对情感倾向性预测的准确率将会进 一步提高。另外,将所提方法应用高效率的情感倾向性 分析,将是未来一段阶段需要进一步研究的方向。
参考文献
[1] 王乃钰,叶育鑫,刘露,等.基于深度学习的语言模型研究进展 [J].软件学报,2021.32(4):1082-1115.
[2] 张忠林,余炜,闫光辉,等.基于ACNNC模型的中文分词方法 [J].中文信息学报,2022.36(8):12-19+28.
[3] 胡昊天,邓三鸿,张逸勤,等.数字人文视角下的非物质文化遗 产文本自动分词及应用研究[J].图书馆杂志,2022.41(8):76-83. [4] 杨旭华,金鑫,陶进,等.基于图神经网络和依存句法分析的文 本分类[J].计算机科学,2022.49(12):293-300.
[5] 祁斌,詹国华,李志华.关于自然语言交互中语音信号优化识 别仿真[J].计算机仿真,2018.35(4):137-140.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/57552.html