SCI论文(www.lunwensci.com)
摘 要: 随着人工智能和大数据的蓬勃发展, 目前各高职院校都陆续开设了人工智能技术服务和大数据技术等专业, 但 AI 和大数据技术对实验环境有着较高的要求,如何更好的利用学校的硬件设备,提高硬件的使用效率成为一个新的课题。本文 提出了一种基于 Kolla OpenStack 的人工智能与大数据教学实验平台,通过开源云计算技术、GPU 透传技术对硬件资源的共 享利用,让用户可以自由分配资源,自主搭建 AI 或 BigData 实验环境。
关键词:AI,Bigdata,GPU透传,Kolla,实验环境
Design of AI and Big Data Teaching Experiment Platform Based on Kolla
XIA Xun1.2
(1.Luzhou Vocational & Technical College, Luzhou Sichuan 646000;2.Luzhou Key Laboratory of Data Intelligent Analysis and Processing, Luzhou Sichuan 646000)
【Abstract】:Now many vocational colleges have successfully set up AI technology services and big data technology and other majors with the vigorous development of AI and big data, but AI and big data technology have high requirements for the experimental environment. How to better use the school's hardware equipment and improve the use efficiency of hardware has become a new topic. This paper proposes an AI and big data teaching experimental platform based on Kolla OpenStack. Through the sharing and utilization of hardware resources through open source cloud computing technology and GPU transparent transmission technology, users can freely allocate resources and independently build AI or BigData experimental environments.
【Key words】:AI;Bigdata;GPU transparent transmission;Kolla;experimental environment
0 引言
随着各个高校开设人工智能和大数据相关专业, AI 和 Big Data 对教学、科研、实验的环境提出了较高的 要求, 如果使用传统的机房, 那么单台 PC 的配置要求 非常高,且资源不能得到比较充分的利用,相关实验必 须上云。通过云计算对资源的统一规划、管理和利用, 改 变了我们获取计算机硬件、软件和服务等资源的方式, OpenStack 是一种基于虚拟机的云计算技术 [1],传统 的部署方式有着诸多缺点,如部署水平要求非常高、基 本不可能升级等。Kolla 项目通过结合容器技术, 利用 预定义的 Docker 镜像部署 OpenStack,可以提供高 可用的、生产级别的、开箱即用的、循环升级的交付能 力。本文通过 Kolla 部署一个 10 余台服务器的高可用 集群,利用服务器搭载的 GPU 进行透传,搭建人工智能与大数据教学实验的平台,可以自由的扩展和伸缩, 提高了硬件的利用率。
1 硬件参数和节点规划
硬件参数 :
CPU :E5 12 核 24 线程 *2
内存 :128G
SSD :400G PCIE
硬盘 :2T*4 企业级(阵列卡设为直通)
显卡 :2080Ti*2
网卡 :双万兆光网卡
交换机 :H3C 48 口万兆光交换机
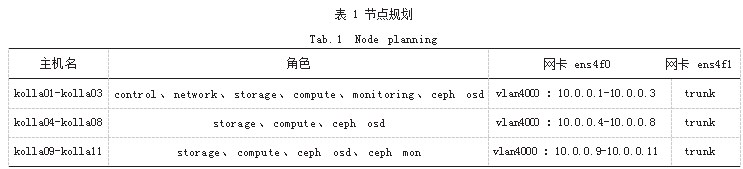
节点规划如表 1 所示。
所有节点安装 Ubuntu 20.04 LTS Server 系统, 网卡 ens4f0 设置为内部网络,交换机端口属性设置 Access,vlan4000.主要承载 Kolla 主机间的连通和 Ceph 分 布式存储的数据交换,不连通校园网,防火墙上设置 NAT 连接外网,使得校园网内部不能直接访问 Kolla OpenStack 集群主机,采用逻辑隔离网络的方式保证集 群的安全。网卡 ens4f1 交换机端口属性设置为 Trunk, 允许校园网分配网段 vlan 219 通信,允许 VXLAN 通信。
2 Ceph 分布式存储
Ceph 是一个可靠、自动均衡、自动回复的分布式存 储系统,随着版本的演进,目前已经达到生产可用的状 态。Kolla OpenStack 早期版本使用 Kolla 的 Docker 实 现 Ceph 分布式存储,但不够灵活,维护也较为不方便, 现在官方已经删除了通过 Kolla 构建 Ceph 的文档,转而 介绍 External Ceph 的配置, 因此需要使用其他 Ceph 的 构建方式。笔者使用了 Ceph-ansible 进行 Ceph 的构建, 为避免 kolla01-kolla03 过多角色造成故障集中点,因此 将 Ceph 的 Mon 节点放到了 kolla09-kolla11.Ceph 创 建好后, 创建 4 个 Pool, 分别存储 OpenStack 的卷、镜 像、备份、虚拟机。
ceph osd pool create volumes
ceph osd pool create images
ceph osd pool create backups
ceph osd pool create vms
并通过 ceph auth get-or-create 命令创建响应的 ceph 用户权 限, 在 /etc/kolla/globals.yml 中配置启 用外置 Ceph。
# Glance
glance_backend_ceph: "yes"
ceph_glance_keyring: "ceph.client.glance. keyring"
ceph_glance_user: "glance"
ceph_glance_pool_name: "images"
# Cinder
cinder_backend_ceph: "yes"
ceph_cinder_keyring: "ceph.client.cinder. keyring"
ceph_cinder_user: "cinder"
ceph_cinder_pool_name: "volumes"
ceph_cinder_backup_keyring: "ceph.client.cinder-backup.keyring"
ceph_cinder_backup_user: "cinder-backup"
ceph_cinder_backup_pool_name: "backups" # Nova
nova_backend_ceph: "yes"
ceph_nova_keyring: "{{ ceph_cinder_keyring }}"
ceph_nova_user: "cinder"
ceph_nova_pool_name: "vms"
3 主机的 GPU 透传
Nvidia 的 vGPU 功能能够进行显卡的虚拟化, vGPU 驱动对显卡的管理和利用效率也更高,缺点是只支持 Grid、 Tesla、Quadro 系列显卡,不支持 GeForce 显卡, 并且 vGPU License 较为昂贵,用于教学实验环境显得不太划 算。综合考虑自建平台使用了 GPU 透传的方式利用显 卡资源。
要使用透传,首先开启主板 BIOS 的 VT-d,即英 特尔支持直接 I/O 访问, 并编辑 /etc/default/grub 文 件,在主机上启用 IOMMU。
GRUB_CMDLINE_LINUX_DEFAULT=="quiet splash intel_iommu=on"
将 snd_hda_intel、vga16fb、nouveau、nvidiafb、 nvidia 加 入 blacklist 中, 重 新 生 成 initramfs。 增 加 Kolla 的配置, 在 /etc/kolla/config/nova.conf 中, 增加 PciPassthroughFilter,并在 [pci] 中增加显卡信息。
[pci]
alias={"vendor_id":"10de", "product_id":"1e04", "device_type":"type-PCI", "name":"Nvidia2080Ti" }
passthrough_whitelist = { "vendor_id": "10de", "product_id": "1e04", "address": "0000:0c:00.0" }
4 Kolla 的部署
Kolla 官方已经预制好了 OpenStack 各种功能的镜 像, 基于平台的需求, 编辑 /etc/kolla/globals.yml 文件, 开启(1)Keystone :身份认证服务, 即 OpenStack 各个功能的身份验证 ;(2) Nova :计算服务,管理虚拟机实例的生命周期 ;(3) Glance :镜像服务,为创 建虚拟机提供镜像模板 ;(4) Neutron :网络服务,为 创建的虚拟机提供网络管理 ;(5) Cinder :块存储,为 创建的虚拟机实例提供持久化存储 ;(6) Heat :编排 服务,通过 Heat 模板,实现虚拟机的自动化部署 ;(7) Horizon :OpenStack 的 WebUI,用于各项功能的管理和 直接面向用户 [2]。同时开启 Mariadb 的高可用,以及外置 Ceph 存储功能, 并配置管理 IP 地址为 10.0.0.100.在 ./ multinode 文件中根据节点规划的各个角色,配置 kolla01- kolla11 的角色,然后即可进行 Kolla 的部署,部署的 命令如下 :
kolla-ansible -i ./multinode deploy
部署完成后,在防火墙上,配置校园网 IP(例 : 192.168.176.250) 和内部隔离网络 10.0.0.100 的端口 转发,将 80、6080 端口的数据转发到内部网络,即可 通过 192.168.176.250 访问平台, 保证了主机内部网络 的逻辑隔离,如图 1 所示。
为了能够使用 GPU,可以额外创建一个实例类型, 关联设置的 PCI 直通硬件。
openstack flavor create --vcpus 4 --ram 8192 --disk 80 --property "pci_passthrough:alias"="Nvidi a2080Ti:1" 4C.8G.2080Ti
在创建实例时,选择实例类型为 4C.8G.2080Ti 即 可使用显卡资源。
5 配置 VXLAN 和 VLAN 的同时使用
默认情况下, Kolla 不支持VLAN,基于校园网环境 可能需要用到VLAN 的情况,需要设置VLAN,编辑/etc/ kolla/neutron-server/ml2_conf.ini 文件, 修改对应配置, 其中 217:219 为外部网络即校园网能够使用的 VLAN。
[ml2]
type_drivers = flat,vlan,vxlan
[ml2_type_vlan]
network vlan_ranges = physnet1:217:219
设置后需要重启网络节点的 Neutron 相关容器。
6 资源的分配
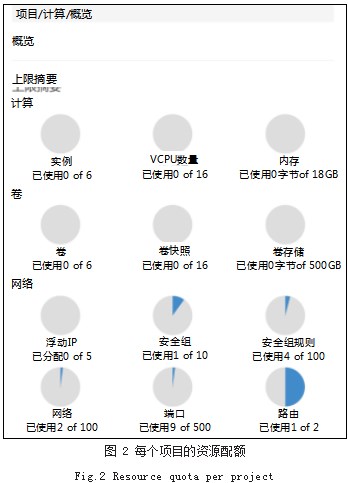
为了让用户能够自由的分配资源,为每一位使用平 台的教师和学生建立一个账号,并隶属于自己独立的 Project, 为 Project 设置 CPU、内存、硬盘空间、浮 动 IP 等资源的配额,如图 2 所示。
7 教学和实验镜像的制作
通过上述方式,平台已经能够将资源分配到各个用 户进行使用,但为了满足教学和实验的要求,还需要 教师做好各种实验环境的镜像,如 Centos7 基础镜像、 Hadoop 完全分布式镜像、Hive 镜像、大数据环境部署 镜像、数据采集环境镜像、TensorFlow 镜像、Pytorch 镜像等,如图 3 所示。需要特别注意的是,我们的平台 Glance 服务采用了 Ceph 作为后端存储, Ceph 是不 支持 Qcow2 镜像格式的,只支持 RAW 格式。即使上 传了 Qcow2 格式的镜像,在发布实例时,计算节点会 从 Ceph 中下载镜像, 转换为 RAW 格式, 然后再上传 到 Ceph 存储中,因此看似占用空间很小的 Qcow2 格 式的镜像反而会非常耗时, 看似较大的 RAW 格式再发 布时因为 Ceph 的三备份机制反而非常的快,经过测试200 人同时使用平台进行实验的情况下,绝大部分镜像1min 内都可以发布。还有一个技巧是制作镜像时,尽量将初始硬盘设置足够的小,通过配置 cloud-init 的方式,自动根据实例类型的空间扩展硬盘分区。/etc/cloud/cloud.cfg 自动扩展硬盘示例如下 :
bootcmd:
- [ cloud-init-per, always, grow-partition, growpart, / dev/vda, 2 ]
- [cloud-init-per,always,resize-filesystem,resize2fs, / dev/vda2]
8 小结
本文描述了一个实际环境中自行部署使用的人工智 能和大数据的教学实验平台,经过两年的使用,目前的 配置优化已经达到了生产级别,可以满足 200 人同时 进行相关的实验。平台通过 Kolla OpenStack 进行资 源的分配和利用,极其充分的使用了大部分硬件。但 是因为 Nvidia 为了利益没有下放 vGPU 功能到民用的 Geforce 显卡,只好使用基于 GPU 透传的方式使用显 卡, GPU 的利用效率并不高,在后续的过程中,准备 编程检测实例是否在使用,定时释放 GPU 资源,以尽 可能的利用 GPU。
参考文献
[1] 干瑞杰.基于OpenStack的校园实验室私有云构建及高可用 性研究[J].中国科技信息,2020(8):100-103.
[2] 陈亚威,朱龙.基于容器技术的高可用OpenStack云平台快 速部署应用[J].电子测试,2018(18):60-63.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/55753.html