SCI论文(www.lunwensci.com)
摘 要:我国的高等教育从精英教育转变为大众教育,从而使高等教育毕业生的规模不断扩大,因此,在高校毕业生规 模每年都屡创新高的形势下,科学评价大学生就业能力对于社会发展具有十分重要的意义。本研究针对上述问题提出了釆用 SpringBoot+Vue 框架搭建一个学生信息管理系统,并提出基于 XGBoost 和遗传算法相结合的大学生就业预测模型,利用现 有数据集对模型进行训练后,预测精度达 85%,对于大学生就业能力评价具有一定现实意义。
关键词:机器学习,Vue框架,XGBoost,就业能力预测
A GA_XGBoost-based Research on the Employability Prediction of College Graduates
YANG Xin1. LIU Yongxi2. ZHANG Xin3. ZHAO Chen4
(1 .School of Economics and Management, Tianjin Agricultural University, Tianjin 300384;2.Heng An Standard Life Insurance Co., Ltd., Tianjin 300051;3.School of Management, Tianjin University of Technology, Tianjin 300384;4.Zhonghuan Information College, Tianjin University of Technology, Tianjin 300380)
【Abstract】:China's higher education continues to transform from elite education to mass education, so the scale of higher education graduates is constantly expanding. Therefore, under the situation that the number of college graduates hits a new high every year, scientific evaluation of college students' employability is of great significance for social development. In this study, SpringBoot + Vue framework is used to build a student information management system and a college student employment prediction model based on XGBoost and genetic algorithm. After the model is trained on the existing dataset, the prediction accuracy reaches 85%, which has certain practical significance for the evaluation of college students' employability.
【Key words】:machine learning;Vue framework;XGBoost;employability projections
0 引言
信息管理系统被广泛应用于各大高校和企业,为其 提供了高效、科学、安全的信息管理方式。当今世界是 一个信息爆炸的时代,每天都有海量的数据生成,而信 息管理系统的基本功能便是管理数据、处理信息以及帮 助管理人员在数据中提取需要的信息,从而帮助高校和 企业集中、统一、高效、及时、安全地管理数据,对于 高校的综合评价,教学和就业尤其重要。因此,本研究 以更好的管理教学和就业数据为目的进行建模,不断改 进教学方案,提升教育水平,最终提高毕业生的就业能力。
学生的就业能力既是国家对高素质人才的需要,也是缓解我国大学生就业压力的关键所在 [1]。伴随着教育 体制的改革,我国应届本科毕业生的规模在不断壮大, 但是学生和企业在就业方面存在矛盾。大学生薪酬预期偏 高,没有良好的职业生涯规划,对第一份工作的要求太 高。而大多数企业虽然渴望人才,但仅凭面试不能够深 刻地了解应聘者的各项能力,因此无法给出过高的薪酬。
另一个方面, 当前应届毕业生的成长环境不同。毕 业生多是 90 后,在中国经济持续发展的大环境下, 90 后的成长环境普遍比 80 后优越,接受教育的程度也更 高。同时,相对于 80 后也没有太大的经济负担,比起 薪酬,更想要一份自己喜欢的工作。不仅是 90 后有这样的想法,大部分的上班族都希望工作能与兴趣相匹 配,这逐渐成为职场人的就业新理念和新向往。
现有的研究主要有两个方面 :(1) 是从不同方面不 同维度来分析影响大学生就业能力的因素,通过制定一 系列标准来评价学生,但其仅停留在理论阶段,并没有 付诸于实际行动 ;(2)是研究的分析对象多为群体,并 未对个体学生做出具体分析和预测,也没有做出能力提 升计划,对学生个人没有实质性的帮助。如果能预测每 位学生的就业能力,不仅有利于了解学生的总体情况, 也有利于改进教学工作,更有利于学生及时调整个人的 学习计划和目标 [2]。
鉴于此,本文提出基于 XGBoost 和遗传算法相结 合的大学生就业预测模型对学生个体的就业能力展开预 测。XGBoost 是基于 Gradient Boosting 框架实现 的 机器学习算法,是一种优化的分布式梯度扩展库,具有 高效和灵活的特性,它深入考虑了系统优化和机器学习 的原理, XGBoost 库的目的是将机器计算的极限提高到 极限,以提供一个具有扩展性、移植性和准确性的机器 学习库。XGBoost 的可扩展性使其解决方案可以通过 分布式或者是通过内存限制来扩展到十亿数量级的实例 中,其运行速度可以达到普通解决方案的十倍以上或是 更高。
1 XGBoost 相关算法原理及参数
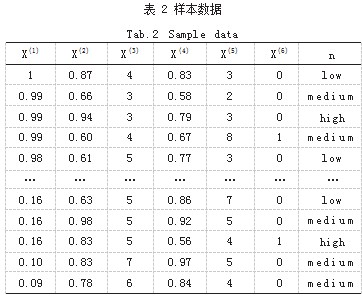
本研究数据主要来源于学校端对学生的打分,主要 基于学生的个人信息、专业信息以及个人相关简历信 息。预测系统所需的数据是直接从已经搭建好的学生信 息管理系统中所提取的,并确定大学生就业能力包括六 大方面个人特质、岗位适应能力、基础技能、问题解决 能力、人际交往能力、持续进步能力 [3]。本研究主要是 针对物流专业学生进行建模,所以认为测评时应当更加 考虑专业技能,最终确定将基础能力这一方面改成对专 业能力的考查更具有分类能力。
1.1 数据划分与特征选择
数据集中有 300 个样本, 除去重复样本保留 256 个 样本。将原始数据的 20% 作为测试集来测试模型的泛化 能力, 80% 作为训练集用来训练 XGBoost 模型,划分 好的数据集和标签存放于文件中。原始数据中的 High、 Medium、Low 3 个等级用数字 0、1、2 表示。本研究 将原始数据的 80% 作为训练集用来训练 XGBoost 模型, 将原始数据剩余的 20% 作为测试集,来测试模型的泛 化能力。
特征选择的目的就是从样本数据集中选取出具有分 类能力的特征,这一步操作的成功对于之后决策树的学习效率以及训练效果具有极大的影响,如果选择的特征 向量对当前的分类结果和随机分类没有产生较大的影 响,换句话说就是不具备分类能力,通常这一类的特征 向量在进行特征工程时会选择放弃掉,选择一个特征主 要看重于它的信息增益和信息增益比。在特征工程时会 选择一些表现比较优秀的特征,往往好的特征工程会带 来较高的收益。
1.2 决策树与 XGBoost
XGBoost 算法是通过一组分类器的串行迭代计算 实现更高精度的分类效果,其基学习器是分类回归树 (CART),在预测时将多个基学习器的预测结果综合考 虑得出最终的结果 [4]。决策树是机器学习中的一种分类 器,利用树形图来作为分析工具,这样更加利于数据科 学家进行分析。一般地,决策树是用叶子节点来代表决 策问题,用方案分支代表当前可供选择的方案,用概率 分支来代表有可能出现的各种结果,最终经过损益值的 计算比较得出一个结果 [5]。XGBoost 框架是一个基于梯 度步进决策树的模型实现工具库。XGBoost 模型如公式 (1) 所示 :
在 XGBoost 中,每一棵树都是不断地添加到集合中 的,类似于树向森林的转变。理论上希望每加一棵树使模 型的分类能力都能够得到提升。下面便是整个 XGBoost 这个框架的集成表示,也是整个算法的核心所在,如公式 (2) 所示 :
整个树一开始是 0.然后往里面添加一棵树,就多 了一个函数,再加第二棵树,就又多了一个函数,循环 往复。添加树的同时需要保证添加的新的树会增加整体 的表达效果,增加表达效果就意味着添加新树后目标函 数值(即损失值)将会降低。
XGBoost 用于监督学习问题(分类和回归)。监督学习的常用目标函数如公式 (4) 所示 :
1.3 XGBoost 参数说明
在运行 XGBoost 之前,须设置 3 种类型的参数 :通 用参数、Booster 参数和学习目标参数。XGBoost 有以下 8 个比较重要的参数 :max_depth、leaming_rate、n_ estimators、objective、booster、n_jobs、reg_alpha、 reg_lambdao,其作用如下 :
(1) max_depth。系统默认值为 6.相关研究通常 用 3-10 之间的数字,该值为树的最大深度,并控制过 拟合。max_depth 越大, 模型学习更加具体, 设置为 0 代表没有限制,范围为 [0.有限 ]。
(2)leaming_rate。系统默认值为 0.3. 每一步迭 代的步长很重要,过大运行准确率不高,过小运行速度 慢,该值设置一般比默认值小。
(3) n_estimators。又名 num_boosting_rounds, 这是生成的最大树的数目,也是最大的迭代次数。
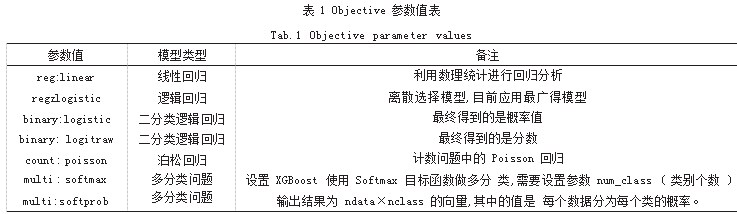
(4) objective。系统默认值为 reg:linear, Objective 参数值如表 1 所示。
(5) booster。我们有 2种参数选择,gbtree和gblinear ogbtree 是釆用树的结构来运行数据,而 gblinear 是基 于线性模型。
(6)n_jobs。使用多少个线性并行构建 XGBoost 模型,默认为 1.
(7)reg_alpha。L1 正则项的权重,默认为 0.
(8)reg_lambda。L2 正则项的权重,默认为 1.
在本研究中需要调参的有 max_depth、leaming_ rate、n_estimators、min_child_weight、subsample、 reg_lambdao。
1.5 调参
本研究的 XGBoost 模型中, 有 8 项需要调节的不 同功能的主要参数,模型参数的设置直接影响模型的拟 合效果。如果进行手动调参,不仅缺乏充足的理论依据,而且会导致出现模型拟合不合理等负面效果。据 此,本文中的模型参数运用遗传算法进行优化,将迭代 过程中的优秀个体保留并进行交叉、变异等操作,找寻 最优参数组合,得到最优训练模型。本文遗传算法的参 数设置如表 3 所示。
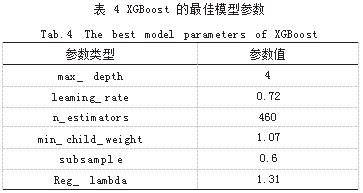
经过 100 次迭代之后得到 XGBoost 的最佳模型参 数如表 4 所示。
经过调参后模型在训练集和测试集上的表现良好, 训练集的分类精度达 99.5%,在测试集的分类精度达 85.33%。
1.6 模型训练及预测
能力预测系统的工作流程由 5 个部分组成 :数据源、 数据清洗、特征工程、模型、预测过滤,如图 1 所示。
现阶段所使用的机器学习方法大多包含了模型训练 和模型预测两个阶段。在模型训练的阶段,我们需要实 现从数据源中获取模型所需要的数据,然后对获取到的 脏数据进行清洗和提取特征,接着把处理后的数据作为 模型的输入。模型在获得输入后,经过多次学习迭代, 迭代过程中会更新模型中一些参数的值,整个迭代过程 被称为模型的训练环节。在得到了模型之后需要对模型 的性能进行测试,因此继续从之前的数据源中按照相同的方式输入训练完成的模型中,模型会对数据进行计算 然后得出结果输出,这整个过程即为机器学习。在了解 机器学习之后再介绍就业能力预测的流程。
训练的流程 :首先从学生端获取数据,对数据进行 清洗,然后进行特征工程,接着对模型进行训练,最后 保存所得的参数。
预测流程 :首先从学生端获取数据, 对数据进行清 洗,然后进行特征工程,接着对样本进行预测,最后将 预测结果存到数据库中方便服务器端处理客户端的请求。
1.7 算法对比
机器学习的算法有很多,分类、回归、聚类、推 荐、图像识别领域。不同的算法对于不同的问题表现能 力也就不一样,所以在实际应用中,通常会选择大家普 遍认同的算法,例如 SVM 支持向量机、Logistic 回归 或随机森林等,但随着算法的不断发展,深度学习、神 经网络算法也得到了广泛应用。
现有的理论中没有任何一个算法能够十分完美地解 决所有的问题,换言之,所有的算法都必须要根据不 同的问题进行建模调参。本研究对 SVM 支持向量机、 Logistic 逻辑回归、随机森林 3 种算法对于该问题的表 现能力做了测试与对比。研究发现对于本研究的分类问 题,通过调参学习训练之后,在训练集都能拥有良好的 预测精度,但是在测试集上 SVM 算法表现就不如人意 了,具体如表 5 所示。
如图 2 所示,对于本研究的回归问题,通过调参学 习训练之后,将 XGBoost 对样本的拟合结果与 3 种算 法模型进行对比可知,4 种算法中,SVM 仍然表现得不 尽如人意, XGBoost 则较优秀的完成了对实际值的预 测,相较于其他机器学习算法的预测结果, XGBoost 的 预测结果更加符合实际情况,证明了 XGBoost 算法在 很大程度上都更优于其他算法,表明了该算法的实用性 和合理性。
2 结论
本文设计了基于 XGBoost 算法的毕业生就业预测 需求预测模型,本文的创新点在于利用机器学习算法预 测毕业生的就业能力,利用 XGBoost 算法构建能力预 测模型,相较于其他机器学习算法, XGBboost 算法的 预测结果更加符合实际情况,是一种可以用来评价毕业 生就业能力的方法。这种方法一定程度上让学生对自己 的能力有一个认识,对于大学生就业能力评价具有一定现实意义。
参考文献
[1] 韩玲,霍菲.供给侧改革视阈下的大学生就业能力提升[J].中 国大学生就业,2022(18):42-47.
[2] 巩红,陈阳,周晨晖,等.基于CatBoost算法的硕士研究生就 业能力预测模型[J].西安邮电大学学报,2021.26(6):89-96.
[3] 吕芹.大学生职业胜任力培养的问题及对策[D].桂林:广西师 范大学,2017.
[4] 李琦,孙咏,焦艳菲,等.基于HMIGW特征选择和XGBoost的 毕业生就业预测方法[J].计算机系统应用,2019.28(6):203-208.
[5] 陈颖,杨欣,孙道贺.基于GA_XGBoost模型的大学生科研能 力预测问题研究[J].数学的实践与认识,2021.51(6):318-328.
[6] 傅翠霞,罗亦泳.基于MK-RVM学习方法的大学生科研能力 预测模型[J].现代电子技术,2019.42(23):163-167.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/55750.html