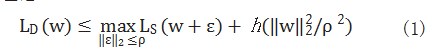SCI论文(www.lunwensci.com)
摘 要:现代神经网络模型仅依赖于 training loss 值的优化方式进行训练 , 由于使用了过多的参数 (Over-parameterize), 在这种情况下, 即便 training loss 值很低 , 也依旧无法保证模型的泛化 (Generalization) 能力。P. Foret 和他的合作者 [1] 提 出了一个名为 Sharpness-Aware Minimization (SAM) 的程序,来同时最小化 Loss Value and Loss Sharpness,SAM 程序 在基准数据集中提升了模型的泛化能力。SAM 程序有一个单一的超参数 ρ(即 the Neighborhood Size),P. Fore 等人通过网 格搜索的方式在 CIFAR 训练集中找到了最佳超参数 ρ=0.05.但在相关人员实际训练的过程中 [2],不同的训练集与模型的最佳 超参数 ρ 并非均等于 0.05.在训练时使用不恰当的超参数 ρ 会浪费计算资源且影响模型的泛化能力,我们提出一种简单的实验 方式,以便在训练初期快速找到超参数 ρ 的最佳值。
关键词:SAM 程序,泛化能力,最佳超参数
Optimal Rho Value Selection Based on Sharpness-Aware Minimization Program
SHEN Aoran
(St.Cloud State University,Saint Cloud, MN 56301-4498)
【Abstract】: Modern neural network models rely only on the optimization of loss values for training. Due to Over-parameterize, in this case, even if the training loss value is very low, the Generalization ability of the model is still not guaranteed. P. Foret and his co-workers proposed a program called Sharpness-Aware Minimization (SAM) to simultaneously minimize the Loss Value and Loss Sharpness. The SAM program improves the generalization capability of the model in the benchmark dataset. The SAM program has a single hyperparameter ρ (the Neighborhood Size). P. Fore et al found the optimal hyperparameter ρ = 0.05 in the CIFAR training set by means of a grid search. However, in the process of actual training by those involved, the optimal hyperparameters ρ for different training sets and models are not all equal to 0.05. Using inappropriate hyperparameters ρ during training wastes computational resources and affects the generalization ability of the model. We propose a simple experimental approach to quickly find the optimal value of the hyperparameter ρ at the early stage of training.
【Key words】: SAM program;generalization capability;best hyperparameters
0 引言
模型的泛化能力是机器学习对新鲜样本的适应能 力。而评价一个模型的好坏可以引入奥卡姆剃刀原则, 即简单有效原理,若有一些连续点,可以用二次或更 复杂的函数拟合,那么就用二次函数来拟合。但同时, Over-parameterize 导致训练的模型泛化能力弱, 我们 需要一个新的方式优化模型, P. Foret 和他的合作者提出了 SAM 程序,使用 SAM 提高了一系列广泛研究的 计算机视觉任务和模型的模型泛化能力。
1 损失函数
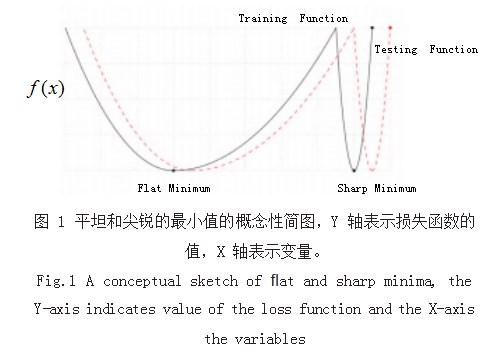
损失函数是一个将随机事件或其相关随机变量的值 映射为非负实数的函数,以表示随机事件的“损失”[3]。 对于机器学习,损失函数一般收敛于最优点的宽阔平 坦区域边界附近的点,大部分时候,参数收敛在 FlatMinima 区域的模型, 比参数收敛在 Sharp Minima 区域的模型,具有更好的泛化能力,如图 1 所示可直观 表现该观点 [4]。鞍点所有参数的一阶导数均为 0 且存在 某一参数的二阶导数小于 0.极大值的一阶导数均为 0 且对于所有参数二阶导数均大于 0.
2 SAM 程序原理
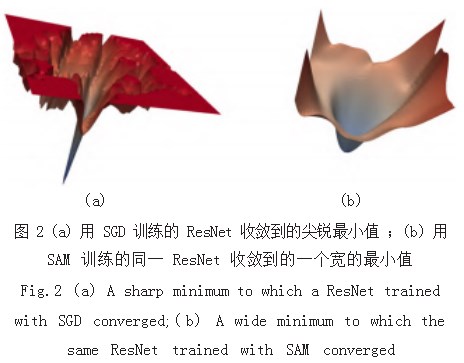
SAM 程序(锐度感知最小化)是一种新的、有效 的方法,它可以同时减小损失值和损失锐度,在领域 Rho 内寻找具有均匀的低损失值的参数, SAM 在各种 基准数据集上都改善了的模型泛化。如图 2 所示为利用 SGD 训练与利用 SAM 程序训练的对比。
2.1 SAM 程序的原理
现代神经网络模型中损失函数通常是非凸的,因此 具有多个局部最小值,这些最小值产生的 loss 值会直接影 响模型的泛化能力 [5]。P. Fore 等人给出如式(1) 所示 的理论 [6] :
h 是一个严格的单调递增函数, LS 是在训练集 S 上 的损失值,如式(2)所示 :
2.2 SAM 程序的实现
P.Foret 在论文中给出了 SAM 程序的伪代码,我们 使用 Python+Pytorch 实现核心代码,如图 4 所示。
3 实验过程
为了寻找 SAM 程序中的最优邻域值 Rho,首先应 验证该超参数对模型训练过程具有重要影响,其次应验 证是否存在一个最优邻域值对所有数据集和模型均有效。
3.1 验证 Neighborhood Size 对训练过程的影响
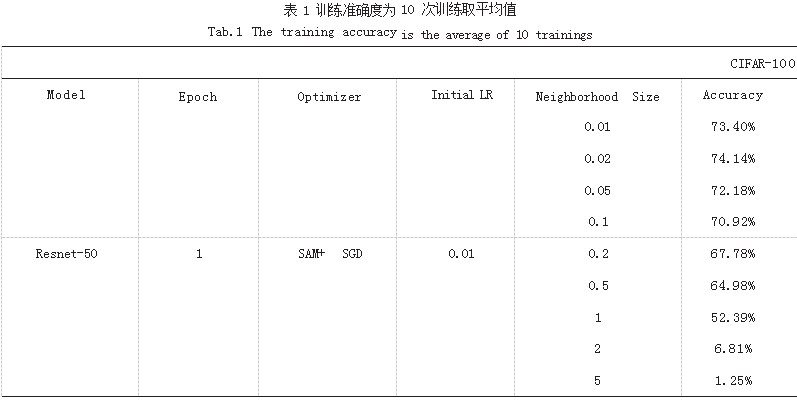
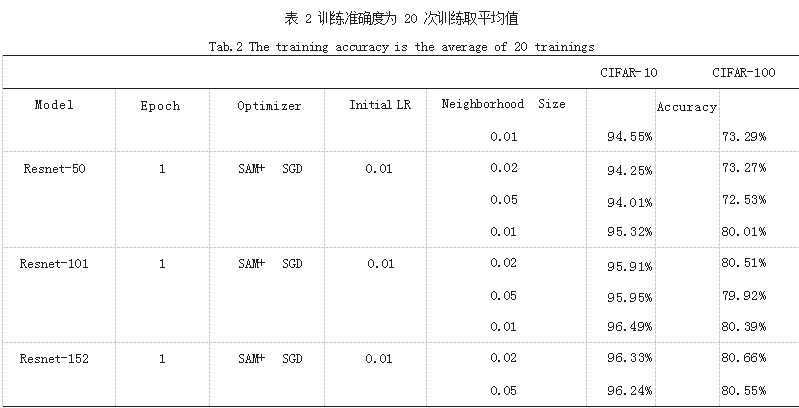
我们首先评估 SAM 程序设置不同 Neighborhood Size 对验证集准确性的影响。我们在 GPU 为 3070Ti Laptop 16G、CPU 为 Ryzen 9 5900HX、运行内存为 32GiB 的主机 上进行训练,训练集选择 CIFAR-10 和 CIFAR-100.模型选 择 Resnet-50、Resnet-101、Resnet-152. 超参数如表 1、 表 2 所示。
3.2 寻找最优邻域值 Rho 的方法
当保持 Rho 值不变时,模型训练过程较为平缓。 一般表现为 Train 集准确率迅速提升,之后上升趋势平 缓。而当使用每周期变化的 Rho 值时,模型训练过程 初期准确度波动较大。一般表现为 Train 集准确率迅速 提升,之后突然小幅下降,并发生震荡,再出现一个相 对平缓的上升趋势。Train 集准确率波动幅度最大的区 域所使用的 Rho 值,与通过表格搜索找到的最优 Rho 值相符。通过该方式可以快速找到最优 Rho 值。
4 实验结果与分析
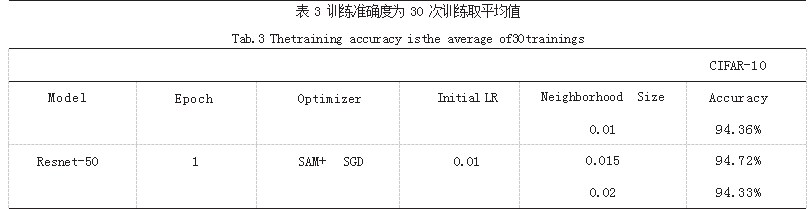
本文首先介绍了 SAM 程序的基本原理, 并对原作者 提出的许多关键函数给予说明,之后通过原论文的理论, 给出了 SAM 程序实现的 Python 代码示例。本文的研究 重点是 SAM 程序中的 Rho 值选择,我们运用表格搜索 的方式,确定了不同模型与不同数据集具有不同的最优 Rho 值,在此理论基础上,通过对同一模型与同一数据 集的不同 Batch 运用大量不同的 Rho 值的 Loss 值结果 绘制图表如表 3 所示,通过该图表总结规律,确定曲线 抖动最陡的区域所对应的 Rho 值为相对最优 Rho 值。
参考文献
[1] FORET P,KLEINER A,MOBAHI H,et al.Sharpness-aware Minimization for Efficiently Improving Generalization[C]// International Conference on Learning Representations,2021.
[2] Jungmin Kwon.Rho for Adaptive Sharpness Aware Minimization (ASAM) #37[OL].(2021-07-30).github.com/ davda54/sam/issues/37.
[3] Prince Grover.5 Regression Loss Functions All Machine Learners Should Know[OL].(2018-06-05).heartbeat.comet. ml/5-regression-loss-functions-all-machine-learners- should-know-4fb140e9d4b0.
[4] KESKAR N S,MUDIGERE D,NOCEDAL J,et al.On large- batch training for deep learning: Generalization gap and sharp minima[J].2016:03+09.
[5] Jia-Yau Shiau,Sharpness-Aware Minimization(SAM): 简单有效地追求模型泛化能力[OL].(2021-02-23).medium. com/ai-blog-tw/sharpness-aware-minimization-sam-简单 有效地追求模型泛化能力-257613bb365.
[6] FORET P,KLEINER A,MOBAHI H,et al.Sharpness-aware minimization for efficiently improving generalization[J]. 2020:03.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/54609.html