SCI论文(www.lunwensci.com)
摘 要:为了提高科研统计的效率,研究从文献数据库中自动获取机构发表论文数据的问题。给出了发表论文数据的爬虫 程序设计,探讨了其关键环节即爬取网页源码和提取论文数据的实现方法。编写程序从知网数据库中爬取了某机构发表论文, 结果与人工检索一致。
关键词: 网络爬虫,科研统计,知网数据库
Crawling the Data of Papers for Scientific Research Statistics: Taking HowNet as an Example
WU Jiaxing, WANG Yulong, SUN Meifeng
(Guangling Collage,Yangzhou University, Yangzhou Jiangsu 225000)
【Abstract】: In order to improve the efficiency of scientific research statistics, the problem of automatically obtaining the data about papers published by an institution from the literature database is studied. This paper presents the design of a program crawling data of papers, and discusses the implementation method of its key steps, that are, crawling web page source code and extracting paper data. This paper compiles the program and actually crawls the paper data of an organization from the HowNet database, and the results are consistent with the manual retrieval.
【Key words】: web crawler;scientific research statistics;HowNet database
引言
论文是科学发现和科学研究很重要的成果和载体, 发表论文的数量和质量一直被视为大学、科研院所研究 实力的表示,因此高校、科研院所都非常重视本单位的 论文发表,与之相适应,登记、审核本单位发表论文情 况是科研管理的一项基本工作。
通常论文登记、审核的流程是这样的 :首先是论文 作者个人填报,经层层汇总后形成单位发表论文汇总 表 ;然后由专门的审核人员对正确性把关 ;最后基于审 核确认过的数据进行各项日常科研管理工作。传统的科 研管理系统基本照搬上述流程,且其中关键的审核环节在系统外人工完成,系统不过提供了审核结果的存储。
网络爬虫是一种按照一定规则,自动抓取 WWW 信息的程序或者脚本,其很早就在搜索引擎中得到应用。 近年来,随着对在线数据深度分析和利用的兴起 [1-3],对 爬虫技术的研究和应用成为热点 [4-8]。其中, 文献 [6] 和 文献 [8] 和本文内容有交叉,但是文献 [6] 的关注点在于 爬取多个论文数据源的效率和结果的融合 ;文献 [8] 提 出利用网络爬虫变传统科研管理系统的人工审核为自动 审核,两者均缺乏爬虫的实现细节。
本文具体研究面向科研统计的单位发表论文数据的 爬取的实现。比较国内提供文献服务的三大中文数据库网站(知网、万方、维普),可以发现知网数据库提供 的论文信息最为详细,对科研统计的支持最为全面,因 此本文仅以知网为例,但包含其中的分析和设计方法同 样适用于其他数据源。
1 机构发表论文数据的爬虫程序设计
正如文献 [1] 指出的,网络爬虫是自动抓取 WWW 信息的程序或者脚本。由于 WWW 网页被设计为通过 浏览器的人工访问,显然为了爬取某个网页,首先了解 人工获取该网页信息时,必须经历的过程,然后正确地 模拟出浏览器发出的网络行为获取网页源码,并从中提 取想要的信息。
那么当用户想从知网数据库中获取单位发表论文数 据时,将做什么呢?必定是首先以“作者单位”和“发 表年度”为关键字检索到单位发表论文的列表 ;然后进 一步点开指向每篇论文的链接,访问论文详情以获取科 研统计非常关注的作者排名、单位排名、期刊收录信息 等,显然论文详情页的访问信息包含在列表页中。
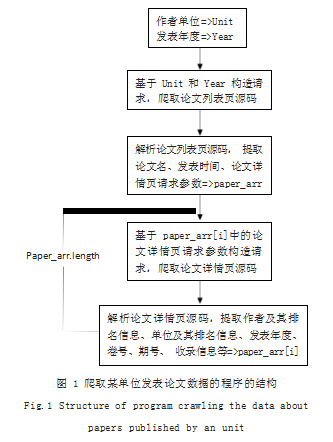
综上,得到以作者单位和发表年度为关键词的单位 发表论文数据的爬虫程序的结构,如图 1 所示。
2 机构发表论文数据的爬虫程序实现 —以知网为例
图 1 爬虫程序中, 无论是爬取论文列表还是爬取论 文详情,都由两个动作组成 :爬取网页源码和提取论文 信息,下面分别讨论其实现。
2.1 爬取网页源码
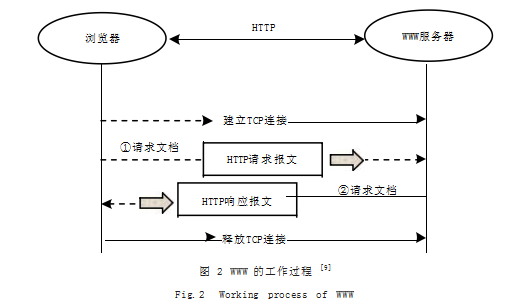
如图 2 所示是 WWW 的工作过程示意图。浏览器与 WWW 服务器按照 HTTP 协议规则交互, HTTP 协议 是一个无状态协议 :首先双方建立 TCP 连接,然后由 浏览器向 WWW 服务器发出 HTTP 请求报文, 再然后 WWW 服务器向浏览器返回 HTTP 响应报文, 最后释放 TCP 连接。网页源码就包含在 HTTP 响应报文中, 若想 WWW 服务器做出期望的反应、返回包含爬取信 息的网页源码,关键则是构造的 HTTP 请求报文能够 通过 WWW 服务器程序的检查。
由于 WWW 的超连接特性,展现在浏览器窗口的 一幅图文并茂的画面,通常由多个网页组成,爬取动作 必须首先分析出爬取信息所在的网页,然后进一步分析 出该网页的请求报文。目前浏览器普遍带有一个扩展功能即开发者工具,可在用户访问网页的同时,截获浏览 器与 WWW 服务器之间的所有交互报文,对该项任务 提供了完美的支持。
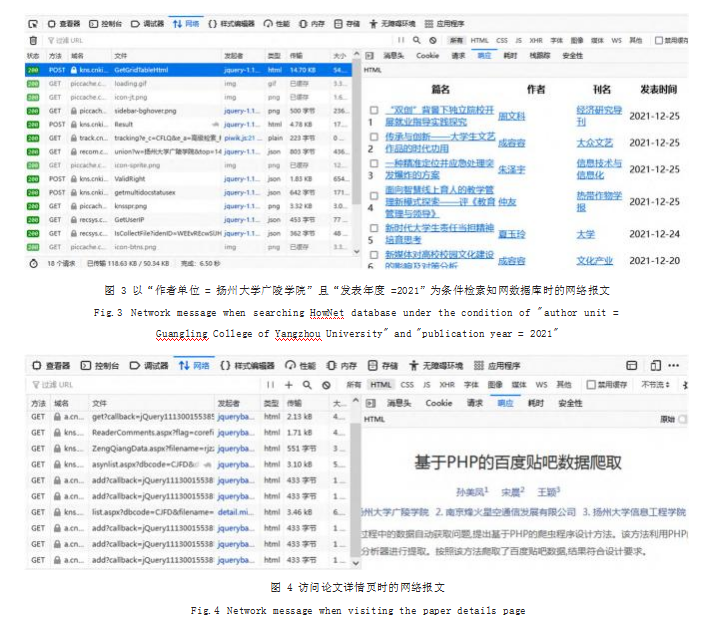
如图 3 所示是以“作者单位 = 扬州大学广陵学院” 且“发表年度 =2021”为条件检索论文列表时,通过开 发者工具截获到的网络交互情况。左侧窗口按时间顺序 列出一个个交互的请求概要信息 ;右侧窗口展示焦点交 互的具体内容,包括消息头、Cookie、请求实体、响应 实体等。
逐个查看图 3 中每个交互的响应实体,便可定位出 论文列表页的请求为“POST https://kns.cnki.net/KNS8/ Brief/GetGridTableHtml”。获取网页源码只需参照开 发者工具的显示,正确设置必要的头部字段和 POST 参 数。经测试,必要的头部字段有 5 个 :“X-Requested-With”“Content-Type”“User-Agent”“Origin”“Referer”; 主要的 POST 参数有 :“QueryJson”,其包含查询条件 “作者单位”和“发表年度”;“CurPage”表示待爬取论 文列表页的页号 ;“RecordsCntPerPage”表示每页的记 录数 ;“SearchSQL”是个动态参数,第一次访问论文 列表页不需要这个参数,后续访问时其值为前一次访问 的论文列表页源码中的元素“input[id=sqlVal]”的值。
如图 4 所示是访问论文详情页时截取到的网络交互 情况。采用同样方法可定位出论文详情页的请求为“GET https://kns.cnki.net/kcms/detail/detail.aspx? dbcode=……& dbname=……&filename=……”。其中,“dbcode”“dbname” “filename”随着论文的不同而不同,但是都可以从论 文列表页源码的每篇论文的篇名区域提取。论文详情页 信息在爬取时遇到的困难是通讯作者信息的获取,通信作者在论文详情页中表现为作者名后面跟随一个信封图 片,但是爬取到的论文详情页源码在相应位置却没有信 封图片。经分析,该图片元素是通过源码引入的 JS 计 算得到的,模仿 JS 的逻辑便可判断通讯作者。
2.2 论文信息的提取
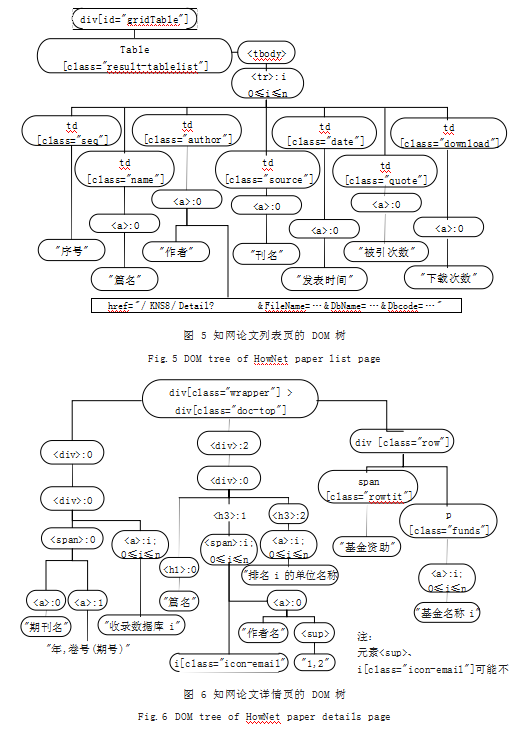
从源码中提取论文信息的关键是识别它们在文档中 的位置,这一任务同样可借助开发者工具完成。如图 5 和图 6 所示分别是论文列表页的 DOM 树以及论文详情 页的 DOM 树,椭圆框代表文档元素结点,矩形框代表元素属性。对元素的表示采用了标签加属性的方式,如 “div[class=’xxx’]”表示 Class 属性等于字符串“xxx” 的 DIV 元素 ;以及标签加序号的方式,如“:0”表 示这是上层结点的 0 号孩子,且它是一个 DIV 元素。图 中的边表示父子关系, 也就是 HTML 标签的嵌套关系。 图 5 和图 6 仅列出与科研统计有关的数据项所在的元素。
3 结果展示
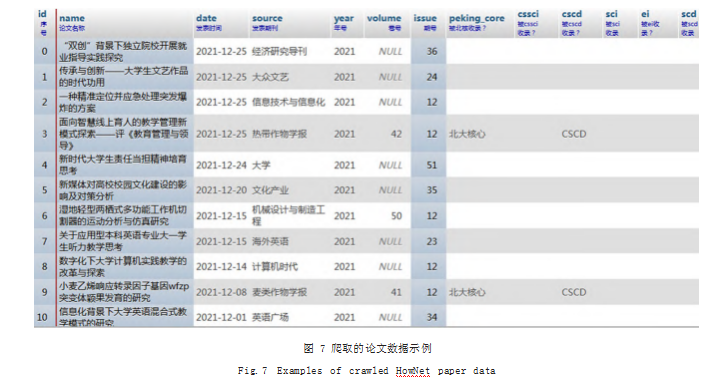
根据上面方法,本文编写了知网论文发表数据的爬 虫程序,并用它实际爬取了扬州大学广陵学院于 2021年度的期刊论文信息,使用 4 张表存储,分别是论文概 要信息表、论文作者信息表、论文单位信息表和基金资 助信息表。经多次执行和检查,爬取结果和人工通过浏 览器检索到的结果一致。篇幅所限,这里仅展示论文概 要信息表,如图 7 所示。
4 结语
本文给出了从文献数据库中自动爬取机构发表论文 数据的方法,包括程序结构及其中关键步骤的实现细 节。利用该方法,可以完全省去科研统计中论文登记和 审核的人工,大大提高科研统计的效率、降低成本。本 文对实现的讨论虽以知网数据库为例,但包含其中的分 析和设计方法同样适用于其他数据源。
参考文献
[1] 刘德喜,聂建云,万常选,等.基于分类的微博新情感词抽取方 法和特征分析[J].计算机学报,2018.41(7):1574-1597.
[2] 张连峰,周红磊,王丹,等.基于超网络理论的微博舆情关键节 点挖掘[J].情报学报,2019.38(12):1286-1296.
[3] 金涛,丁国栋,焦清局.基于百度贴吧的学习者群体挖掘研究 [J].中国教育信息化,2019(7):57-62.
[4] 曾健荣,张仰森,郑佳,等.面向多数据源的网络爬虫实现技术 及应用[J].计算机科学,2019.46(5):304-309.
[5] 孙美凤,宋晨,王颖.基于PHP的百度贴吧数据爬取[J].软 件,2020.41(11):23-26.
[6] 侯晋升,张仰森,黄改娟,等.基于多数据源的论文数据爬虫技 术的实现及应用[J].计算机应用研究,2021.38(2):517-521.
[7] 陈思宏,刘紫仪.基于网络爬虫的住宅型房地产评估测评系 统[J].商业经济,2020(5):139-141.
[8] 唐绍华.网络爬虫技术在科研成果管理中的应用研究[J].现 代信息科技,2020.4(19):93-95.
[9] 谢希仁.计算机网络(第8版)[M].北京:电子工业出版社,2021: 276.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/54042.html