SCI论文(www.lunwensci.com)
摘 要 :随着外卖行业的迅猛发展,外卖 App 对于菜品和商家的推荐服务精准度要求也水涨船高。因此,根据现有数据 研究出了基于决策提升树的外卖推荐算法。在算法的设计研究过程中,通过对外卖订单数据的初步分析,根据其特点选取决策 提升树作为算法的分类器。在具体模型方面,希望通过使用 3 种不同的模型,即 XGBoost、CatBoost 和 LightGBM,来分别 得到分类结果并分析研究在当前环境下性能最强的模型并给出相关建议。希望对于局部数据的研究能够在一定程度上代表长期 的用户外卖订单数据,进而能够为推荐算法的研究提供一定的新思路。
关键词:美团菜谱,推荐算法,GBDT
Research on Meituan Recipe Recommendation Algorithm Based on GBDT
CAO Rui
(School of Mathematics and Statistics, Huazhong University of Science and Technology, Wuhan Hubei 430070)
【Abstract】: With the rapid development of the takeout industry, the accuracy requirements of the takeout app for dishes and merchants' recommendation services are also rising. Therefore, according to the existing data a takeaway recommendation algorithm based on decision lifting tree is developed. In the process of algorithm design and research, through the preliminary analysis of sales order data, the decision lifting tree is selected as the classifier of the algorithm according to its characteristics. In terms of specific models, we hope to use three different models, namely XGBoost, CatBoost and LightGBM, to get the classification results, analyze and study the models with the strongest performance in the current environment and give relevant suggestions. It is hoped that the research on local data can represent the long-term user take out order data to a certain extent, and then provide some new ideas for the research of recommendation algorithm.
【Key words】: meituan recipe;recommended algorithm;GBDT
引言
近些年,随着我国移动设备的普及以及线上支付系 统的趋于完善,各个行业也希望将自己的业务内容“搬 到”移动设备上,使群众能够更加快捷方便的满足自己 的需求。在这些行业中,餐饮服务业的变化无疑是革命 性的—线上订餐 App 的诞生几乎改变了传统餐饮行 业的结构,而这无疑使人们能够更加方便地获得自己想 要的美食,同时也促进了商家的多元化发展,使其线下 业务逐渐向线上转移。外卖系统由于送餐到家和供选择 菜品较多的特点,逐渐被越来越多的群体所接受。
我们希望通过研究更为出色地算法来为当前的推荐 服务提供解决方案。在算法研究过程中首先需要解决的问题就是如何在众多数据文件中筛选出需要分析的内容。 数据集源于美团外卖 App 中部分商圈(蜂窝) 的用户在 2021年6月7日至2021年7月2日的订单及相关信息, 包含了用户外卖订单、用户属性、商家属性、菜品属性、 订单菜品关系以及订单下单前的商家点击序列共 6 类文 件,我们的目标是利用以上文件信息,对订单测试集中 的用户在最后一周可能购买的商家或菜品进行预测。
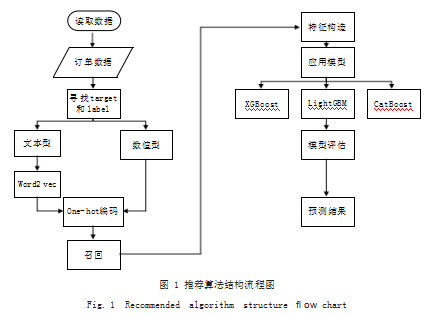
为尽可能提高推荐质量,决定对于不同的数据集采 用不同的方法来处理特征。对于特征提取后的数据,需 要对其作分类 [1]。同样的,为得到性能最好的推荐,分 别使用 XGBoost、CatBoost 和 LightGBM 3 种模型分 类器对数据特征进行分类。希望通过应用以上模型并比较以得到最适合作为主体的决策树框架,在此构建算法 的结构流程图如图 1 所示。
1 基于订单数据的特征提取与构造
1.1 订单数据预处理
训练集的基础特征和 label 的构建是特征提取的基 础。我们取训练集为历史数据中订单日期在 2021 年 6 月 7 日 至 2021 年 6 月 27 日之 间 的数据, 令 label 集 为训练集中的外卖订单号和外卖菜品号两特征,同时在 其中加入标签列使该部分数据在该列均为 1 用以表示之 后的召回过程中的真正样本。历史特征则为原历史数据 中的订单日期自 2021 年 6 月 7 日起前 20 天内的部分。 接着进行召回过程,在此过程中,我们的目的是通过简 单的规则对用户或商家某些特征统计偏好。例如,对于 用户来说,有近 20 万菜品供选择,我们选择销量或销 售金额前 30 位的菜品执行召回任务,以统计用户对于 这些菜品的偏好。在商品池中,我们抽取小部分菜品按 上述两个特征进行排序、细化等操作,挑选出 5 个最可 能被用户预定的菜品。(可以适当减少召回数量以减少 占用内存)在这里,召回率度量的是正类样本中有多少 被预测为正类,即真正例占被分为正例的比例。在本文 中,我们对召回进行分情况讨论,在读取菜品特征后, 分别按购买次数召回、考虑 / 不考虑下单时间段和按购 买金额召回、考虑/ 不考虑下单时间段进行 [2]。除此之外, 我们在召回的过程中还可以适当考虑用户的邻居行为, 对 于用户的位置进行交叉统计,对于相近的用户计算重合 度与相似度,对于相似度排名前五的菜品给予一定的权 重加入召回的目标向量,而对于商户的邻居行为同理。
1.2 特征构造
先构造用户特征。构造的过程中,对于用户的历史 单均价、工作日历史单均价和周末历史单均价,我们使 用独热编码对其进行区间等距划分后编号 0 ~ 5.从而 得到其数值型特征。接下来利用 Word2Vec 构造菜品 名和用户名的特征。对于不同类型的特征,我们将其数 据转化为不同维度的向量并存入列表中,随后为其进行 编码。例如,对于外卖菜品名称和标准菜名称,我们使 用 10 维向量来统计其特征,而对于菜品品类标签、食 材标签和口味标签,我们适当降低维度,使用 5 维向量 将其存入列表中。同理,对于商户,我们同样使用该模 型进行特征构造。最后是历史特征的构造,分为基于用 户侧和基于菜品侧的特征构造。我们在已知用户的情况 下,分别根据下单时间段、用户收藏蜂窝、收餐地址兴 趣面和它们的随机组合对菜品进行购买数量和购买金额 的统计 ;在已知菜品的情况下,依然分别根据下单时间 段、用户收藏蜂窝、收餐地址兴趣面和它们的随机组合 对用户数量和购买金额进行统计。最后构造用户购买菜 品的时间统计特征及用户最近一次购买该菜品的时间间 隔。接着对测试集重复上述步骤,并将两个集合所得数 据合并,得到接下来要应用到模型中的数据集。
2 基于 GBDT 的三种模型特征分析
首先分析样本数据应用在算法中的性能。混淆矩阵 是用来展示算法性能指标的矩阵, 可展示真正(TP)、 真负(TN)、假正(FP) 和假负(FN) 样本的数量。 据此,我们能够得出正负样本比例,本次研究中的正负 样本比例为 93408/1418245.先选取训练集的数据, 在其中不重复的外卖订单中划分出 20% 的数据作为验证 集,将验证集部分剔除,观察标签“label”列(原进 行召回时设置的特征),保留真正样本,对其余部分进 行随机抽样,抽取其中 10% 的数据与真正样本的数据 合并且按照外卖订单 ID 排序构成最终的训练集。由于 样本中负样本比例较大,我们不希望机器在学习过程中 受负样本影响过大,进而影响预测的准确度,这里我们 采用下采样的方式来调整失衡的正负样本比例。显然调 整过后,正负样本比例处于 1:1 和 1:2 之间。由于这些 分析是基于之前的特征提取时的算法得到的结果, 3 种 不同模型的选取并不会影响该部分。
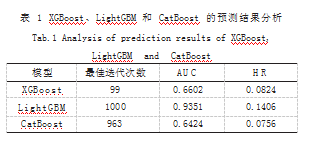
接下来,将选取合适的参数,将 3 种不同模型应用 到已有的特征中。为将在不同模型中不同的特征的重要 性更直观的体现出来,绘制了直方图以直观展示特征在 模型的预测中的作用。XGBoost 模型的特征重要性由于 权重集中于以下 3 个特征 :基于用户侧的收餐地址兴趣 面的购买数量、基于用户侧的菜品购买数量和基于用户 侧的收藏蜂窝的菜品购买数量, 3 种特征对于模型的影 响程度远超其他特征, 达到 95% 以上, 故该模型的应用 意义不大。而在 LightGBM 和 CatBoost 的模型特征直 方图构建过程中,发现在不同模型中,相同的特征有着 不同的重要性。在 CatBoost 的直方图中, 特征重要性 数值较小且不同特征之间差距较大 ;而在 LightGBM 的 直方图中,发现其特征重要性均较高,说明每个特征对 模型的构建影响均有意义 [3]。通过预测结果和真实订单 结果比较,并根据 HR@5(hit rate @Top 5) 评分。HR@ N 是目前 Top-N 推荐研究中常用的评价指标,计算方 式为用户总数与测试集中的项目出现在 Top-N 推荐列 表中的用户数量的商,本次研究中取 N=5.对于 3 种不 同的模型,能够得到不同的结果如表 1 所示。显然,在 3 个模型的共有参数相同的前提下, LightGBM 模型的 评分较高, 预测的准确率高, 而 CatBoost 和 XGBoost 模型的评分低,相应的其对于订单数据的预测能力也较 差。因此通过比较,推荐选取 LightGBM 模型作为最 终的分类预测模型,以提高在 TOP-N 预测中的命中率。
AUC 值的比较在推荐算法中也是衡量模型性能的 指标,通过计算 ROC 曲线下的面积,能够得到 3 种 模型的 AUC 值如表 1 所示,XGBoost 和 CatBoost 的 AUC 值差距不大且均较低,只有 LightGBM 的 AUC 值超过了 0.9.分析可能是本研究中的特征属性中文本 和数值型混合,而 CatBoost 对于文本型分析能力强, 故不适合 XGBoost 和 CatBoost 的应用。
通过以上的评估方法,不难发现经过交叉验证后的 模型更适合应用到此案例中。同时,还希望能够通过对模型的部分参数进行调优的方法来提高模型性能。然而 在实验过程中,发现对于例如学习率、树的最大深度等 重要参数的调整对于模型预测结果的最终评分几乎没有 影响,因此有理由认为参数调优的方法对于该案例的作 用几乎无效,故对于参数调优不作详细的介绍和解释。
3 结语
在本次推荐算法研究中,选取了美团外卖一个月内 的订单数据作为样本,对未来一周内的订单进行了预 测。首先通过词向量模型、独热编码等方法对数据文件 进行数值化的处理,接着对菜品和商家进行了召回,并 构造相关特征,最后将所得特征代入模型中进行分类预 测,经过参数调优等方法得到最终的预测结果。
鉴于推荐算法的多样性,本小组研究的此算法作为 一种对于推荐问题的解决办法,显然还有较大改进空 间。在研究过程中发现,对于此种订单推荐式算法,可 以通过更好的方法对数据文件中的文本型数据进行处 理,从而解决词向量模型忽视用户位置的问题,故有理 由相信在经过改进后能够得到更高的 HR 指标。此外, 在用户的召回过程中,对于召回规则的设置较为简单, 而为了提高召回率,仍可以通过对更多其他因素如对于 商家或菜品页面的浏览时间和用户餐后的评价的考量来 设置更为复杂的召回规则,同时还可以尝试增加召回的 商品量来在一定程度上提高召回的准确性。
综上所述,推荐使用更适合订单数据的 LightGBM 模型作为特征分类预测的主模型,并在其中应用交叉验 证来增加预测的准确性。在此,希望该算法及其思想能 够得到某种程度上的应用来检测算法的有效性,以方便 对其进行进一步的修改,提高 HR 和 AUC 指标,为用 户提供更满意的推荐服务。
参考文献
[1] 朱峙成,刘佳玮,阎少宏.多标签学习在智能推荐中的研究与 应用[J].计算机科学,2019.46(S2):189-193.
[2] 刘慧.基于XGBoost的个人贷款信用风险分析模型研究[D]. 郑州:郑州大学,2020.
[3] 周围.基于LightGBM-Logistic回归的网贷个人信用评分模 型研究[D].杭州:浙江工商大学,2018.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/53567.html