SCI论文(www.lunwensci.com)
摘 要: 目前道路工况巡视、无人驾驶等领域需要应用道路障碍自动识别、检测技术,论文提出了基于图像识别的道路障 碍检测方法,通过应用双视觉识别模型实现道路障碍检测,论文首先阐述了摄像机视觉模型,在此基础上提出了双视觉模型, 重点对基于图像的障碍物检测算法进行了详细阐述,通过本算法提高了道路障碍检测的自动化处理效率。
关键词 :障碍检测,图像识别,数字化处理,双视觉识别
Research on Road Obstacle Detection Method Based on Image Recognition
GUO Jiayi
(Xianlin Campus, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210023)
【Abstract】: At present, it is necessary to apply road obstacle automatic identification and detection technology in the fields of road condition inspection and unmanned driving. This paper proposes a road obstacle detection method based on image recognition, and realizes road obstacle detection by applying the dual vision recognition model. Based on the camera vision model, a dual vision model is proposed, and the image-based obstacle detection algorithm is elaborated. The automatic processing efficiency of road obstacle detection is improved through this algorithm.
【Key words】: obstacle detection;image recognition;digital processing;dual vision recognition
0 引言
传统的道路障碍检测通过人工辨别方式及时发现处 理完成,但对于一些道路工况复杂区域、危险性较高的 区域,常规的人工排查方式受限或不准确,因此产生一 些道路障碍自动辨识的工具或平台,如应用于工况复杂 的隧道安全机器自动检测、无人驾驶汽车、危险道路的 巡视等领域中,通过摄像头自动获取图像,自动检测出 道路存在的障碍。
1 摄像机视觉模型
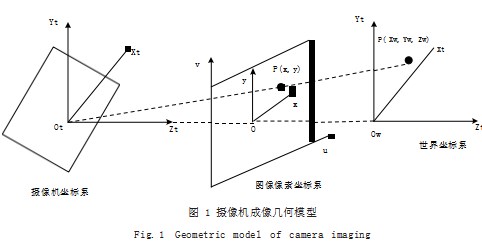
道路障碍物检测通过双目视觉模型取得左右两视图, 然后通过逆成像生成三维空间坐标系下的目标点的三维 坐标 [1]。为了说明左右视图下的三维坐标信息,对摄像 机视觉模型进行阐述,然后把此模型进行拓展,拓展到 双视觉模型中。如图 1 所示为摄像机成像几何模型图。
由图 1 可知,图像像素坐标系为二维坐标系统,坐 标系统的原点为摄像机光轴交点,其坐标轴 x 与 y 分别 与世界坐标系的 Xt 和 Yt 平行。摄像机坐标系统为定义在三维模型中的坐标系,坐标系的原点 o 为摄像机的光 心位置, x 轴、y 轴分别平行于图像坐标系中的 x 轴、y 轴。Z 轴为摄像机的光轴,垂直于成像平面,根据成像 原理,在摄像机坐标系中的某一点坐标是通过投影映射 到图像坐标平面的。世界坐标系即为客观真实世界中的 三维空间坐标系,其原点与 X 轴、Y 轴、Z 轴的设置需 要根据实际情况进行设置,这种设置坐标系统与其他坐 标系存在着平移变量和旋转变量关系,通过坐标变换可 实现不同坐标系之间的转换。
一般来说,摄像机的初始参数、平移变量与转换矩 阵参数等,在出厂前均已设置固定,其不会产生因成像 环境、应用次数而发生改变。摄像机的外参矩阵与在摄 像过程中的空间坐标中的运行轨迹相对应,当摄像机的 位置、方向发生变化时,就会自动产生对应的转换变量。
2 双视觉识别模型
双目视觉模型是指通过立体图像表来表达真实场景 的模型,其基于视差理论基础而开发的 [2],视觉系统分为两类 :一类是由同一台摄像机采用运摄像方式,从不 同角度来拍摄静止的景像 ;另一类是由两台不同的摄像 机,分别采用不同角度来完成景物的拍摄。由于是两台 不同的摄像机拍摄模式,即双目视觉,比较适合动态场 景的检测,其灵活性强,满足道路障碍检测的需求。文采用双视觉识别模型来实现道路障碍检测。
双目视觉系统采用以下步骤来实现 :
(1)图像采集。图像采集即通过视觉传感器从不同 角度采集到立体图像对,这是双目视觉成像的前提,进 行图像采集时,要考虑到具体的场景特征、光线、摄像 机的性能等。
(2)摄像机标定。现场场景中某一点与其在两个图 像平面上的投影位置关系是由摄像机的模型、参数来决 定的,摄像机精度决定了障碍物检测时的精度,设定摄 像机参数的过程就是摄像机标定。
(3)图像特征提取。本过程就是从图像中提取用于 匹配的基元过程,提取的特征是为立体匹配提供基础准 备的。在系统中,为提高立体匹配的精度以及匹配的速 度,同时保证匹配的稳定性,需要选择合理的图像特征。
(4)立体匹配。所有空间点在两个不同的摄像机平 面投影之间存在一定的几何关系,寻找这种几何关系的 过程即为立体匹配,立体匹配主要目的就是获取相应的 视差,提高匹配精度、降低匹配复杂度是当前立体匹配 研究的热点问题。
(5)三维深度确定。通过匹配点之间的映射关系和 摄像机的标定配置,计算出真实环境中目标点的三维深度, 故提高三维深度其关键是提高立体匹配与标定的精度。
3 图像数字化预处理
道路障碍物检测系统首先通过视觉系统采集图像, 然后对图像进行预处理。摄像机拍摄的图像是连续的, 而计算机所能够处理的图像属于数字信息,因此需要把拍摄的图像转成相应的数字图像。数字图像是指在亮度 上经过量化处理,空间上采样之后的图像,即对一幅连 续的图像,经过加工处理为成组的样本,每个数字图像 由数字矩阵组成,在坐标系中, x 轴与行数递增的方向 一致, y 轴与列数递增的方向一致, 数字图像矩阵中各 元素代表着像素。摄像机在采集图像过程中,会出现一 些噪声,而噪声会对障碍物的检测识别产生影响,因此 需要对采集的图像进行处理,如通过平滑处理降噪。
通常处理的方法包括两种 :空间域法和频率域法, 其中频率域法处理过程较复杂,实时处理性较低,而论 文研究的道路障碍物检测要求实时性较高,因此数字图 像处理采用了空间域法。在降噪处理时,判断某一个像 素是否需要平滑处理,需要验证,使其像素的灰度值是 否其相邻领域的灰度值的平均值相差不大,如果其灰度 值与邻域值的平均数相差较大,则过滤掉原来的孤点, 使此像素的灰度值等于领域平均值。
4 基于图像的障碍物检测算法
前面阐述了双目视觉模型,论文通过双目视觉模型 来实现图像障碍物检测过程,下面分别从障碍物区域的 确定、障碍物基点的计算、建立约束条件以及构造障碍 物检测框等方面来设计基于图像的障碍物检测算法。
4.1 确定障碍物区域
在道路障碍物检测过程中,为减少障碍检测处理的 复杂度,引入基于路面消失点检测算法来提取路面,以 便确定机器人或无人机在巡视检测中的目标障碍区域。 路面区域的计算即去除天空、非需处理的交通标志牌以 及较远程的景物等,具体通过采用双目视觉的路面提取 算法来计算,然后通过道路边侧的消失点为界线消除图 像背景,以降低一些非障碍物区域内的视点差对检测过 程产生的影响。
在移除路面的背景以及远方景物后,需要进一步移除路面信息,才能确定障碍区域,为减少路面移除过程 的计算复杂度,提高计算速度,利用视差图拟合到路径 斜线的方式来实现,即拟合斜线后反投影转换成视差 值,然后把路面区域的所有像素点视差值赋为 0.然后 在视差图中把路面区域进行移除,余下的区域为确定的 障碍物区域。
4.2 计算出障碍基点
通过前面设计可知,在视差图中移除了路面区域和 背景区域后,视差图中非 0 的视差值组成的像素区域即 为目标障碍物区域。为了更有效地对障碍物区域进行分 析和数据提取,进一步细化处理检测目标障碍物,可对 目标区域内的障碍物进行划分,划出障碍物的基点,即 查找出障碍物与路面的交叉点。计算目标障碍物的基 点,一般采用边缘检测算法来实现,本论文采用的边缘 检测算法为 Canny 算法 [3],其为最优的边缘检测算法, 其处理模式采用了基于边缘梯度方向的非极大值限制, 同时采用双阈值的滞后阈值来处理,其性能较强,检测 效率高。
4.3 建立约束条件完成区域扩展
在提取障碍物区域基点后,由于障碍物在视差图中 存在相近的视差值,同时在双目视觉识别模型中,左右 摄像机的成像平面距离差值较小,因此可采用视差值控 制在一定范围内的约束,把三维视差图中的基点视为区 域生长算法的种子点和扩展方向,来完成障碍物区域中 目标障碍物的轮廓提取,其过程就是利用图像中像素点 的相似,根据预置的相似性判断参数对目标像素点进行 聚集处理,把特征相同且相似度参数范围内的区域进行 分割处理。区域生成即以种子点为基础,随后对像素种 子其周围的像素进行相似性度量参数进行对比,如果两 值在允许范围内,则当前像素点与原子像素点继续向外 扩展。
4.4 构造障碍物检测框
通过区域生成算法来获取目标障碍物在视差区域 后,根据计算出来的基点袖差图,对提取的障碍物检测 框进行标识,通过视差图对障碍物的高度信息进行采 集,经过 Hough 变换计算出障碍物线段、构造检测区 域的高度值,然后再经过 Hough 变换,根据视图差拟 合的线段结果来确定障碍物的宽度值,通过上述步骤, 实现目标障碍物检测框的完整构建,最终确定障碍物。
在构造完成障碍检测框后,便可确定路面的目标障 碍物,完成道路障碍物的识别检测。
5 道路障碍检测的实现
前面对基于图像识别的道路障碍检测模型、算法进 行了设计,本部分主要对具体的实现功能进行描述。道 路障碍检测系统可应用于机器人、道路无人自动巡视设 备和无人驾驶等领域,检测系统从框架上可分为感知 层、数据通信层、业务计算层、控制层等,下面分别对 这些层的设计进行描述。
(1) 感知层 :主要用于获取客观图像, 系统采用双 摄像机,采集三维成像,感知层主要采集道路信息、远 处影物以及道路背景等。感知层通过设置一定的图像采 集频率来执行图像采集,如设置 5 张 / 秒,可根据巡视 速度、驾驶速度来设定。
(2) 数据通信层 :在感知层获取图像后, 通过数据 通信层把采集到的数据传输到核心计算层,为保证数据 通信的稳定性,采用通信电缆实现数据的稳定传输,对 于一些速度较慢、数据传输性能要求较低的巡视设备, 可采用蓝牙通信模式。
(3) 业务计算层 :采集完成数据后, 根据图像识别 算法,分别做图像预处理、障碍物区域的确定、障碍基 点的计算以及构造障碍物检测框等,来完成目标障碍物 的识别、检测处理,并且把计算结果传输给控制层。
(4) 控制层 :根据业务计算层的结果, 记录道路障 碍物的状况,以成像或预警的方式对目标障碍物进行处 理,控制层根据应用场景来实现控制,当检测到障碍物 时,会自动进行预警提示或发出相应的指示,把当前距 离及时地反馈或记录在巡视日志中。
6 结语
本文首先论述了道路障碍检测的需求,然后分别介 绍了摄像机视觉模型和双视觉识别模型,随后阐述了图 像数字化预处理过程,在此基础上重点设计基于图像的 障碍物检测算法,最后在算法设计后,完成了系统平台 的实现。
参考文献
[1] 张艳霞.机器人立体视觉中摄像机的标定探析[J].机电工程 技术,2019.48(7):120-123.
[2] 唐东林,游传坤,丁超,等.爬壁机器人双目视觉障碍检测系统 [J].机械科学与技术,2020.39(5):765-772.
[3] 赵子润,高保禄,郭云云,等.基于改进Canny算法的噪声图像 边缘检测[J].计算机测量与控制,2020.28(12):202-206+212.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/53069.html