SCI论文(www.lunwensci.com)
摘 要:本文阐述了智慧实验室系统的功能,有针对性的提供智慧服务,并基于 Spark 框架给出了数据标准与使用规则, 设计了大数据采集流程、大数据处理框架、大数据存储模式及大数据展示等智慧实验室系统的概要设计架构。
关键词:智慧实验室,大数据处理,Spark
Construction of Smart Laboratory System Based on Spark Framework
YU Kailan, HONG Xiaojuan, WANG Zhijun, SONG Limin
(Schoolof Management, Nanjing University of Postsand Telecommunications, Nanjing Jiangsu 210003)
【Abstract】: This paper expounds the functions of the smart laboratory system, provides targeted smart services, gives the data standards and usage rules based on the spark framework, and designs the outline design architecture of the smart laboratory system, such as big data acquisition process, big data processing framework, big data storage mode and big data display.
【Key words】: smart laboratory;big data processing;Spark
引言
近几年教育部已经出台了多项文件 [1.2] ,鼓励并支持 各地、各高等院校在教育领域借助物联网、大数据、5G 等新一代信息技术实现因材施教,提升教育数据的管理 与共享,促进校内管理、服务流程再造,构建智能化、 专业化、感知化的新型智慧教育生态和智慧教育模式。
高校实验领域无论从所涉范围(包括教学、科研、校 企合作等),还是从数据、信息的供需量来说都是高校智 慧化建设的重点,因此,怎样依托大数据处理框架构建 高校智慧实验室系统,协同各数据平台,丰富产学研生 态资源已经成为当前高等学校高质量发展的重要课题。
1 智慧实验室系统的功能
结合多位业内专家的观点 [3.4],本文认为智慧实验室 系统应构建在先进信息技术基础设施之上,集成若干个大 数据处理平台,具备以下这几项功能:(1)通过大数据平台实现多系统的集成,打造信息流校内闭环,丰富实验资 源,共享实验资源;(2)提供丰富的业务模块,满足实验 室运营的各项需求,做到实验室多维度的开放;(3)挖掘 校内数据湖泊的价值,实现实验课程 / 项目推荐、科研团 队推荐、实验环境预警以及实验场所能耗监管等智慧应 用;(4)为未来提供数字孪生实验平台预留好接口。
2 智慧实验室系统架构设计
以当下流行的 Hadoop 家族为大数据框架,采用 Spark 计算引擎为智慧实验室提供数据挖掘服务,本文 所构建的系统更偏向于为教师和学生提供面向实验的各 种智慧应用与智能安全保障。
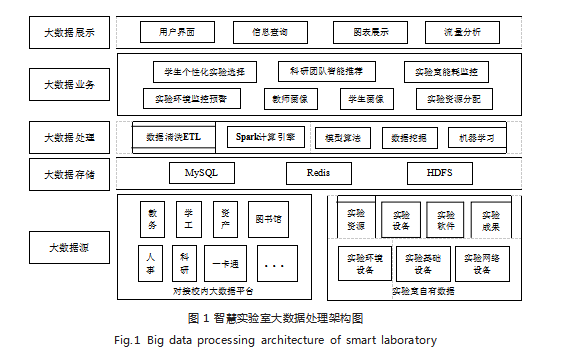
Spark 是 Apache 旗下的一个开源大数据计算引擎, 由于它使用 DAG 执行引擎优化计算,并且将计算所需数 据存放在集群节点的内存中,因此可以实现快速计算 [5]。 Spark 解决了前辈 Hadoop 因磁盘 IO 开销大而造成的计算速度慢,但它仅专注于计算,数据存储和资源管理方面 依然和 Hadoop 框架紧密集成 [6]。Spark 支撑多种编程语 言,拥有丰富的 API 集,可以支持批处理、流数据计算、 机器学习、图计算和交互式查询。本文所描绘的智慧实验 室系统选择 Spark 计算引擎从海量校园数据中挖掘数据特 征,构建模型并优化算法,实现对实验室的智慧化管理, 如图 1 所示展示了智慧实验室大数据处理架构。
2.1 数据标准与使用规则
高校实验室系统的数据架构是学校整体数据架构的 一个重要组成部分,因此在完善整个实验室系统数字化 架构过程中,管理制度和组织架构应依据各校实际情况 予以制定。所使用的数据标准参照校内数据标准执行, 而高校在执行统一的校内数据标准时,一方面要参考国 家和教育行业的数据标准;另一方面要考虑到今后区域 性教育资源共享的大趋势,因此应充分考虑本地区学校 使用的主流标准。
在制定数据的使用规则前, 应该梳理一遍基于数据应 用的所有项目,同时还要结合保障数据安全的相关条款。
2.2 大数据采集
实验室信息系统要能够做好智慧服务,实现智慧应 用,仅依靠和实验相关的数据还不能满足要求,必须通 过校内大数据平台对接其他业务部门的相关数据,因此 采集到的将会是海量、多源异构数据。这些数据来源大 致可分为 2 类:
(1)实验室系统自有数据的采集,这类数据根据其 用途可分为 4 类: 1)实验教学资源,包含实验课件、 实验视频、指导手册、参考资料以及实验数据等;2)实验室基础设备 [3] ,涉及物理空间、水电系统、照明设 备、环境传感器等;3)实验室教学设备 [3] ,多媒体设 备、实验仪器、实验软件、触控设备、录播设备、门禁 及监控设备等;4)网络设备 [3] ,包括服务器、中间件 与网络通信设备。
(2) 来自校内其他业务部门的数据,通过校内数据平 台接口获取。其中来自于教学、科研等业务机构的离线数 据属于结构化数据, 一般存放在 MySQL、Oracle 等关系 型数据库中(本文仅以 MySQL 为例),可以通过 Spark 家族 Spark SQL 模块提供的关系型接口转接 [5]。而对于实 时产生的流式数据的采集会采用 Kafka 和 Flume 组件, 其中 Flume 可以对不同类型的日志数据源进行采集, 捕捉新增数据,将数据发送到指定位置; 经过 Flume 采集的数据需经过 Kafka 组件,通过 Kafka 对消息队 列的良好管理,为系统抵抗瞬时数据洪流的冲击,因此 两个组件合并使用能够保证流式数据收集过程的高并发 性、高可用性和高吞吐量。
2.3 大数据处理
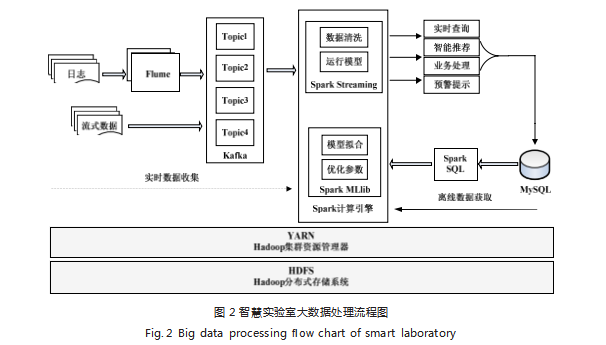
大数据处理流程是整个智慧实验室系统的核心所在, 如图 2 所示。
不同类型的离线数据在导入时即可通过 Spark SQL 进行过滤与规约,再借助 Spark 生态圈中 MLlib 组件 进行数据挖掘、建模,给出教师画像、学生画像,提供 实验课程 / 项目的推荐模型、科研团队的推荐模型、实 验环境监控预警模型以及实验室能耗监管模型等。
而实时数据经由 Kafka 消息队列分发至不同的 Topic 中,Spark Streaming 通过拉取不同 Topic 中的数据首先会进行数据清洗和过滤,然后存入 HDFS 中为后 续离线优化模型做好存储; 同时这些数据还要按照各类 业务的处理要求进行计算,挖掘数据应用价值,将计算 结果写入 MySQL,支撑前端数据访问并提供在线查询、 智能推送、业务处理、预警提示等功能。例如将实时的 实验环境数据调入预警模型,进行在线检测,捕捉异常 值,做好实验室实时安全保障;提供可视化的实验室实 时能耗监测管理系统;在未来基于 Spark 引擎的数字孪 生平台可以智能匹配最佳算法,支持虚拟实验的服务, 做到按师生实际需求、实时请求自动分配实验资源。
在整个实验室的运营过程中利用 MLlib 定期进行 机器学习,利用推荐项目的点击率、(实验 / 科研团队) 配对成功率、学生评价等不断产生的新数据,优化各种 推荐模型和预警模型,提升系统功能的精准度。
2.4 大数据存储
收集来的多源异构数据会存储在 HDFS 分布式文 件系统, 采用 HDFS、Hbase 进行存储与管理。HDFS 是 Hadoop 的底层存储系统,也是 Hadoop 的重要组 成部分,具有高吞吐量、高容错性、高拓展性的特点; Hbase 同样是分布式的开源数据库,但它更适合于存 储非结构化的数据,支持数据的动态扩展与实时读写访 问。计算过程中,热点数据依靠 Redis 缓存。计算后需 要展示的数据可借助 Spark SQL 写入 MySQL。
2.5 资源管理与协调服务
由于 Spark 计算引擎是运行在分布式架构之上, 因 此存在协调集群资源、统一管理的任务,这一角色就由 Hadoop 的资源管理系统 YARN 来扮演。在调度计算资源同时 YARN 也跟进应用执行的整个过程。
但是仅有 YARN 的资源协调还不够,在进行大规模 分布式计算过程中,需要系统各节点操作 / 处理的数据 具备一致性(比如,实验课程选课期或者实验资源需求 高峰期,每个用户终端实时反馈的可选实验课程余量、 空闲设备余量必须保证一致), 这种情况下本系统需要 使用 Zookeeper 提供的协调服务。
2.6 大数据展示
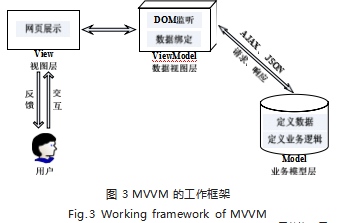
智慧实验室系统依托前后端分离架构进行构建,前 端着力于关注视图层,后端重点解决业务逻辑。可视化 前端采用渐进式框架 Vue, Vue.js 使用了 MVVM 的设 计模式,通过数据的双向绑定(如图 3 所示),减少了 在数据更新过程中因维护 View 与 Model 的映射关系 而产生不必要的 DOM 代码, 通过 Axios 和后端进行异 步数据交互,使得局部视图得以自动刷新。由于采用了 响应式的页面布局,可以适配屏幕尺寸不同的设备 [7]。
除了数据驱动, Vue 组件化的思想也是该模式流行起来 的一个重要原因,通过小型组件来构造大的应用,允许 封装可重用代码,这些都提升了代码的可维护性,为系 统高效开发和快速应用提供可能。
后端是基于 SpringBoot 的三层架构,即 DAO 层、 Service 层和 Controller 层。DAO 层负责和数据库的交 互,通过对应接口实现对数据的增删改查;Service 层提 供业务逻辑并提供接口;Controller 层调用 Service 层, 做好与前端的连接交互工作,前后端采用 JSON 数据进 行传输。SpringBoot 继承了 Spring 的优良性能, 摆脱 了 Spring 的繁琐配置,缩短了整体开发时间。
3 结语
本文顺应实验室智慧化发展的趋势,给出了基于 Spark 的智慧实验室信息系统的概要设计,研究了 Spark 框架下大数据处理在高校实验平台的应用,既能够满足个 性化的实验教学需求,以兴趣引导科研团队的构建,又能 为实验室节能减排,提供安全保障,同时也使得校内数据 孤岛问题得以解决,在保障信息安全的前提下创造校内 数据福利,为产学研一体化获取更多的数字支撑。
参考文献
[1] 中华人民共和国教育部.关于加强网络学习空间建设与应用 的指导意见[EB/OL].(2019-01-25)[2022-04-19].http://www.moe. gov.cn/srcsite/A16/s3342/201901/t20190124_367996.html.
[2] 中华人民共和国教育部.关于推进教育新型基础设施建设构 建高质量教育支撑体系的指导意见[EB/OL].(2021-07-21)[2022- 04-19].http://www.moe.gov.cn/srcsite/A16/s3342/202107/ t20210720_545783.html.
[3] 胡国强,杨彦荣 .智慧教育背景下高校智慧实验室的构建与 研究[J].实验技术与管理,2021.38(3):283-287.
[4] 颜婉茹,杜青林,魏金枝,等 .基于互联网+技术智慧实验室的 研究与创建[J].实验室科学,2020.23(6):170-173.
[5] Benjamin Bengfort,Jenny Kim.Hadoop数据分析[M].王 超纯,译.北京:人民邮电出版社,2018:52-53+146.
[6] Tom White .Hadoop权威指南[M].王海,华东,刘喻,等, 译.北京:清华大学出版社,2017:548-549.
[7] 肖文娟,王加胜 .基于Vue和Spring Boot的校园记录管理 Web App的设计与实现[J].计算机应用与软件,2020.37(4):25- 30+88.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/52697.html