SCI论文(www.lunwensci.com):
摘要:针对两相流流型识别,以ERT系统为基础,将多种类型PSVM进行组合,设计基于反馈思想的组合并行支持向量机模型,对油/水两相流的流型进行识别。仿真实验结果显示,基于反馈思想的组合并行支持向量机是一种有效的流型识别方法。
关键词:反馈式;流型识别;并行支持向量机
Research on Manifold Recognition of Combined PSVM Based on Feedback
ZHANG Hua
(Jilin Institute of Architecture and Technology,Changchun Jilin 130114)
【Abstract】:Forflow pattern identification of two-phaseflow,based on ERT system,various types of PSVM are combined,and a combined parallel support vector machine model based on feedback idea is designed to identify theflow pattern of oil/water two-phaseflow.The simulation results show that the combined parallel support vector machine based on the feedback idea is an effectiveflow pattern identification method.
【Key words】:feedback type;flow pattern recognition;parallel support vector machine
流型是两相流研究领域的一个重要参数。流型的数据量和复杂度在流型获取技术的快速发展下不断增大。大规模样本的训练和预测难以使用单机环境下传统的SVM算法处理,而并行支持向量机(PSVM)[1]的出现解决了以上问题,为了缩短训练时间,PSVM可按分而治之的原则将原始大问题分解成若干小问题,继而将所有小问题并行处理后再集成起来。本文根据各种PSVM的特点,组合几种常用的PSVM,构造一种基于反馈思想的组合并行支持向量机模型,对ERT系统下的油水两相流进行识别,有效提高流型识别的精度和速度。
1 ERT系统结构和工作方式
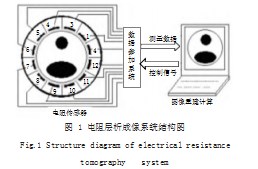
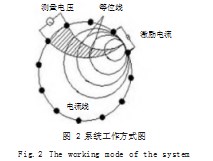
电阻层析成像(ERT)系统主要由三部分组成,分别是电阻传感器阵列、数据采集系统、图像重建计算机[2]。它的工作原理是电流激励、电压测量,系统结构如图1所示。本文的电导率波动信号由12电极的电阻传感器阵列采集,对相邻电极进行激励,因此一幅图像包含12×(12-3)=108个测量数据。系统工作方式图如图2所示。
2基于反馈思想的组合并行支持向量机模型构建
2.1基于反馈思想的组合并行支持向量机模型构建原理
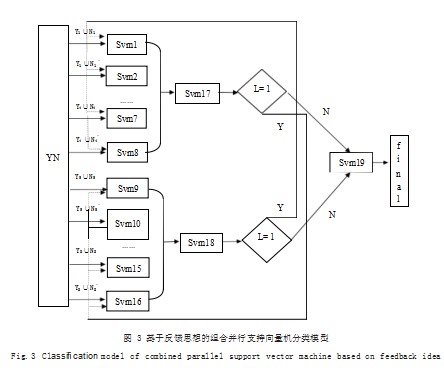
PSVM设计模式的常见形式有层叠式、分组式、反馈式[2]。三种模式各有特点,具有训练时间优势的是层叠式和分组式PSVM,它们可以提高训练速度,缩短训练时间,但分类精度无法保障。具有分类精度优势的是反馈式PSVM,它可以提高训练精度,但是存在训练时间过长、无法确定满足要求的精度等问题。另外,这几种模式在划分训练样本子集时都是随机划分,无法保证样本在各子集内部的均匀分布,使分类信息增加了损失的可能性。因此本文根据各种PSVM的特点,组合几种常用的PSVM,构造一种基于反馈思想的组合并行支持向量机分类模型。首先将分组式和层叠式PSVM进行组合训练,再将训练结果分组交叉反馈到各初始样本集中进行二次训练,进一步提升分类准确度。在设计分类模型时,为了减少分类信息损失,提高识别精度,在训练前随机交叉组合原始样本子集,可是这样的操作又会直接导致组合迭代的层数增多,延长PSVM的训练时间。为了解决这个问题,采用计算各类间的分离度[3]的方法,比较分离度大小,将所有类平均分成两部分,比较难分离的类对应的子样本集作为难分样本集,比较容易分离类对应的子样本集作为易分样本集,再将难分样本集与易分样本集进行交叉组合。
2.2基于反馈思想的组合并行支持向量机模型构建过程
2.2.1计算类间分离度
首先对ERT系统中测量的四种流型计算不可分离度。根据下列公式计算各类间的不可分离程度。公式中的Si,j表示第i类和第j类流型的不可分离程度,其中i∈(1,2,3,4)
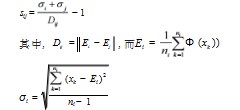
四种流型两两之间的不可分程度分别用S1,2,S1,3,S1,4,S2,3,S2,4,S3,4表示,第i类的分离度(Ti)可以用第i类与其余4-i类不可分程度的值求平均值表示。将原始样本平均分成8份,每份子样本集按照类间分离度值的大小,平均分成两部分,一部分是易分样本集Yi,另一部分是难分样本集Ni,由于随机性的原因,每个子样本集中的难分样本集不能准确代表其他子样本集中的难分样本,因此对于第i个难分样本集Ni,从其他8-i个难分样本集中随机抽取不相同的样本集Ni’与之合并,第i个难分样本集就变成了Ni和Ni’,最后将Ni和Ni’分别与每个样本子集中的易分样本集Yi进行交叉组合[4]。
2.2.2构造PSVM分类模型
第一次训练,先将每个原始样本子集中的易分样本集Yi分别与难分样本集Ni和Ni’进行交叉组合,产生16个样本子集,将每个样本子集输入到各自的支持向量机中进行并行化训练。因为大多数样本空间中,非支持向量的比例要远高于支持向量,因此,第一层SVM训练过后,就会将大部分非支持向量过滤掉,只保留少数支持向量。接着剩余的支持向量被分成两组,用2个SVM并行训练。第二层训练过后,两组的训练结果交叉反馈到第一层的对方组样本中,继续进行第二次训练。最后,将两组的训练结果汇总输出。基于反馈思想的组合并行支持向量机模型如图3所示。
3实验过程和识别结果
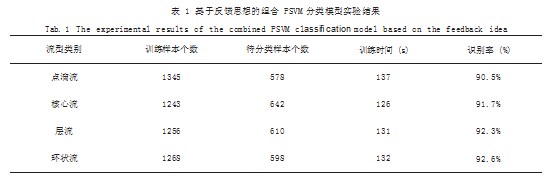
本实验基于Hadoop平台,每个样本包含108个特征数据,在训练和测试前,需对训练样本和待分类样本数据做特征提取。基于反馈思想的组合PSVM模型实验结果如表1所示。
4结论
本文提出在两相流流型识别领域中设计一种基于反馈思想的组合PSVM分类模型。仿真实验结果证明基于类间分离度的反馈式混合PSVM的流型识别效果能够兼顾训练时间和识别准确率,是一种效率较高的流型识别方法。
参考文献
[1]胡健,王祥太,毛伊敏,等.基于Relief和BFO的并行支持向量机算法[J].计算机应用研究,2021,39(2):447-455.
[2]边肇祺,张学工.模式识别[M].北京:清华大学出版社,2000.
[3]白玉辛,刘晓燕.并行SVM算法在Flink平台的应用搞研究[J].小型微型计算机系统,2021(5):1003-1007.
[4]张华,谢宇航,曹江.基于并行支持向量机的两相流流型识别研究[J].通讯世界,2019(11):30-31.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/50617.html