SCI论文(www.lunwensci.com):
摘要:针对当前主流PDF阅读器复制文字尤其是中英文混合排版文字时存在的全角字符、错误标点符号、多余换行符和空格等问题,提出了一种面向PDF文档的文本复制优化方法,通过剪贴板监听自动感知复制内容变化,基于正则表达式分析复制文本内容特点并采用不同优化策略修正文本格式错误,并提出了3种不同的段落切分策略正确识别文本中的段落,实现了用户“无感知”情况下的复制文本自动优化。在报纸、社科、理工和国防类期刊等4类PDF数据集的实验表明,与直接复制相比,提出的方法能够消除95%以上的格式错误,极大地减轻了人工负担,提高了处理效率。
关键词:PDF文档;文本复制;文本优化;段落切分
Research on a Text Copy Optimization Method for PDF Documents
HE Weixiong1,BAI Linyuan2,GUO Wenjuan2
(1.Academy of People's Armed Police,Beijing 100010;2.Army Engineering University of PLA,Nanjing Jiangsu 210001)
【Abstract】:To solve the problems of full-corner characters,wrong punctuation marks,redundant line breaks,and spaces in the copying of text,especially the mixed typesetting text in Chinese and English,in the current mainstream PDF readers,a text copying optimization method for PDF documents was proposed.Based on the regular expression analysis of the characteristics of the copied text content,different optimization strategies were adopted to correct the formatting errors of the text.Three different paragraph segmentation strategies were proposed to correctly identify paragraphs in the text,which realized the automatic optimization of the copied text in the case of"No Perception"by users.Experiments on four kinds of PDF data sets,such as newspaper,social science,science and technology,and national defense journals,show that compared with direct copying,the proposed method can eliminate more than 95%of format errors,significantly reduce the manual burden and improve the processing efficiency.
【Key words】:PDF document;text copy;text optimization;paragraph segmentation
0引言
PDF是由Adobe公司开发的一种电子文件格式,具有不依赖具体的操作系统、显示信息和文档信息相互独立、内容不易修改等特点,广泛应用于电子图书、电子报刊、电子文件和图表等领域[1],中国知网、万方数据、维普网等收录的论文大多采用PDF格式作为载体。
学习笔记制作、语料库搜集、信息采集时对PDF文档内容的复制引用是常见的应用,但是由于PDF主要是面向显示[2],内容复制时并不方便,经常出现句子截断、多余空格、标点错误等各种问题,极大地影响了处理效率。而当前对PDF文档内容的研究,主要集中在文档信息[3]、关键内容提取[4]、文本内容抽取[5]和全文检索[6]等方面,尚未有学者对PDF内容复制时存在的诸多不足进行分析解决。为此,本文提出一种面向PDF文档的文本复制优化方法,在保留原始内容的情况下尽可能消除格式错误,从而减轻人工负担,提高工作效率。
1问题的提出
当前,阅读PDF文档的常用软件有Adobe Acrobat Reader、Chrome或Edge浏览器、Foxit(福昕)PDF阅读器、金山PDF阅读器等,但是经试用发现,使用这些软件在复制PDF文字时均存在类似错误,以“中国知网”下载的文献[7]为例,仅复制论文摘要部分,存在的典型问题如图1所示。
其中,主要问题包括多余的换行和空格、错误的标点和全角字符等,手工修改工作量大,不利于文章内容的参考引用、内容转载和后续处理。总的来说,这些问题可归结为格式错误问题,因此需要研究PDF复制文本的格式优化方法,使其文本格式更接近于其原始格式。
2 PDF文本复制优化方法
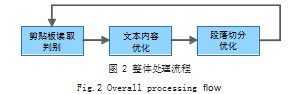
为了能够自动检测并修正各类PDF文档阅读器复制文本时的错误问题,本文设计了一整套PDF文本优化处理流程,整体结构如图2所示,其中共涉及3个阶段,分别是剪贴板监听判别、文本内容优化和段落切分优化。
2.1剪贴板监听判别
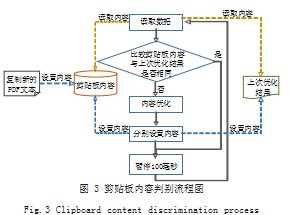
剪贴板是操作系统中内置的存放信息空间,用来临时保存剪切和复制的信息[8]。当用户在PDF文档中复制文字时,文字内容会保存在剪贴板中,此时如果复制文本优化程序在后台监听并自动美化优化处理剪贴板内容,并将处理后的内容重新放回剪贴板中,那么用户后续粘贴引用的就是优化后的文字,达到“无感知”的效果。
由于程序在后台需要长时间监听剪贴板,为了保证不重复处理剪贴板文本,需要专门开辟一个变量存储上次处理后的文字结果,然后每隔一定时间进行轮询,只要发现剪贴板的内容是与上次处理后的结果不一致的内容,就自动启动文本优化流程。优化后,设置剪贴板并保留上次已处理文字结果部分,整体流程如图3所示。
2.2复制文本内容优化方法
PDF文本在复制时经常出现的问题包括多余的换行,由于这些错误都属于格式问题,可以借助正则表达式对其进行修正。正则表达式又称规则表达式,是一种便捷高效的文本处理工具,由普通字符以及特殊字符组成的文字模式,描述了待搜索字符串的匹配模式[9],例如“[a-zA-Z]”能匹配所有大小写字母,“[u4e00-u9fa5]”能够匹配所有汉字。下面针对不同类型的复制错误问题提出针对性的修正方法。
2.2.1不规范的空格
考虑到英文单词使用空格进行区分,因此不能将文本中所有空格全部删除,而是需要区分英文还是中文的空格,保留英文后面的空格,删除中文后面的空格。
(1)将英文后面的多个空格合并为1个空格,可以使用正则表达式“[a-zA-Z](s{2,})”找到所有英文字母后面2个或2个以上的空格,然后将其替换为1个空格。
(2)删除中文后面的空格,可以使用正则表达式“[u4e00-u9fa5,。《》“”)?!](s+)”找到中文和中文标点符号后面的所有空格,并将其删除。
2.2.2错误的标点符号
在英文表达中,标点符号通常使用半角符号,即逗号用“,”,句号用“.”,而中文标点符号一般用全角,即逗号用“,”,句号用“。”。因此,对于所有汉字后面结尾的英文标点符号需要统一替换成中文标点符号,可以使用正则表达式“[u4e00-u9fa5》)]([.,:;?!])”找到中文后面常见的英文标点符号,然后根据标点符号类型进行针对性修改,反之亦然。
2.2.3全角的英文与数字
在部分PDF文档中,英文和数字都是全角,在图1中就是用“RNK56”而不是常见的“RNK56”,需要将全角的数字和英文统一修改为半角的英文和数字。
一般来说,利用字符的Unicode编码可以实现全角字符的判断和字符转换,Unicode编码是国际标准组织对各国文字、符号进行统一性编码,每个字符一个编码,共65534个字符[10],例如字母“a”的Unicode编码为97。判断时,除了全角空格的Unicode编码为12288,其他全角字符的Unicode编码都在65281和65374之间。转换时,除了全角空格转半角需要将Unicode编码从12288变为32以外,其他全角字符和半角字符的Unicode编码均相差65248,因此可以把所有Unicode编码在65281-65374范围内的全角字符统一换成半角字符。
需要注意的是,由于部分全角字符在中文中作为标点使用,包括“,?!:;”,因此在全角和半角转换时,需要对上述字符的Unicode码进行排除。
在对内容进行优化时,处理顺序对结果影响很大,例如全角转换为半角的处理如果放到最后,则在处理空格时无法通过正则表达式[a-zA-Z]获得字母(因为字母可能均为全角字符),影响删除多余空格的效果。因此,一般采取先进行全角字符串转换,然后修正标点符号,最后修正空格的方式进行内容优化,保证效果最佳。
2.3段落切分方法
不规范的空格、错误的标点符号和全角符号等,一般基于中英文排版的特点,采用合适的正则表达式规则判断和替换即可,而要正确自动删除多余空行符,其前提是必须准确划分段落,优化处理复制文本时仅保留用于段落划分的换行符。为此,根据大多数PDF文档的排版特点,本文提出了3种策略进行段落切分优化。
2.3.1句子结束策略
对于复制PDF文档内容时得到的每一行,当行尾是一句话结束的标点符号时,称其为“句结束行”。中文表示一句话结束的标点符号主要有6种,分别是句号、感叹号、问号、下引号+句号、下引号+感叹号、下引号+问号。句子结束策略就是将所有的“句结束行”判定为段落结束。
这种策略实现简单,但会把正好在折行部分的句结束标点符号误认为是段落结束,从而增加段落。以图4为例,左侧PDF文档的第10行和14行由于句结束标点正好在折行部分,会被句子结束策略误以为是段落结束从而增加段落。
2.3.2行宽比较策略
为了规避句子结束策略的问题,该策略引入了“行宽”。其主要思路是,对于绝大多数PDF文档,文字显示的宽度是固定的,段落中间行占满整个宽度,而段落结束行通常比整行要短,因此通过“句结束行”和“行宽”两方面进行比较,可以较为精确地判定可能的段落结尾。
统计行宽时,按照英文和数字部分占1个字符、中文占2个字符的宽度进行计算,其计算实例如图4所示,通过右侧的行宽条形图明显看出,第7行和第19行明显比其他行要短,因此第7和第19行有可能是正确的段落结束行。
行宽比较策略最重要的就是获取“整行宽”,即整行能容纳的字符宽度。其计算方式如下:如果行数为n,将n行按照行宽从小到大进行排序,取第[0.75n]行的行宽为“整行宽度”widthline,其中,[·]表示向上取整符号。例如,图4中共19行,将19行的行宽按照从小到大进行排序,第15行的行宽44为“整行宽”。
在判定时,如果该行是“句结束行”,且行宽小于整行宽度的λ倍,则认为是段落结束,其中0<λ≤1,λ的值越大,可能获得的段落数越多,段落切分越不精确,一般可令λ=0.8。以图4为例,第7行结尾是句号,该行宽度为32,小于λ·widthline=0.8×44=35.2,即可判定改行是段落结束行。该策略实现较为复杂,获取段落精度比句子结束策略要好,但不适用于列宽不固定的文字,例如文字环绕版面等,也有可能存在漏判的风险。
2.3.3上下文判定策略
为了解决PDF文档因行宽不同导致行宽比较策略失效的问题,引入上下文判定策略。该策略的基本思路是放弃计算“整行宽”,转而通过“句结束行”的上下文环境进行判定。具体来说,就是将“句结束行”的行宽与其上一行和下一行的行宽进行对比,如果上一行和下一行都比“句结束行”要长,则说明该行可能为段落结束。以图4为例,第7行对应的第6行和第8行都比它的行宽要大,因此第7行可能为段落结束。该策略实现较为简单,能够克服行距比较策略的弱点,但也存在将可能的自然分段判定为不分段的情况。
3实验与分析
实验代码使用Python3.7编写,计算机配置为64位Windows10专业版,运行内存为16GB,CPU为Intel Core i7-7700HQ,主频2.8GHz。
3.1基准数据集
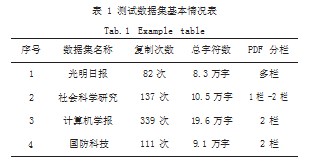
基准数据集使用《光明日报》报纸和《社会科学研究》《计算机学报》《国防科技》等期刊近几年PDF格式的版面,涵盖报纸、社科类、理工类和国防类期刊,下载地址来自光明网(epaper.gmw.cn)、中国知网(www.cnki.net)、计算机学报网站(cjc.ict.ac.cn)和万方数据(www.wanfangdata.com.cn),打开PDF文档后随机进行复制,复制字符数从100~2000不等,测试数据集基本情况如表1所示。
3.2比较函数
本文使用编辑距离比较文本间差距,编辑距离也叫莱文斯坦距离(Levenshtein Distance),是针对两个字符串差异程度的量化度量,测量方式是看最少需要多少次的处理(包括增加、删除或修改一个字符)才能将一个字符串变成另一个字符串[11],例如字符串“大学生”和“大学毕业”编辑距离为2。
比较时,首先将复制PDF文档的内容通过人工将其调整为正确的格式,该内容作为原文。在调整时除了格式以外的部分均不进行处理,例如变量的上下标、公式错误等。比较时只需要计算原文和比较内容的编辑距离,编辑距离越大,说明两者差距越大,需要修改的工作量越大。
3.3实验结果
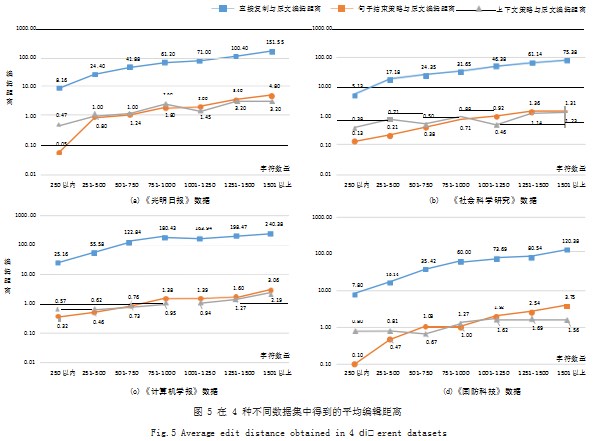
在实验中,分别比较3种方法,即直接复制PDF内容、“内容优化+句子结束策略”“内容优化+上下文判定策略”得到的结果,与原文进行比较。由于上下文判定策略是行宽比较策略的优化,因此实验中就不单独使用行宽比较策略。经统计,在4种不同的数据集中,3种方法与原文的平均编辑距离如图5所示。
其中,横轴为复制不同数量字符时的情况,纵轴为各种方法与原文的编辑距离的平均值,由于句子结束策略与上下文判定策略结果很相似,为了便于区分,纵轴采用以10为底的对数坐标。
从结果可以看出,本文提出的文本优化方法远远好于直接复制时的结果,在大多数情况下能够减少95%以上的格式错误。而本文提出的句子结束策略和上下文判定策略,当复制字符数量较少时,句子结束策略占优,但是随着字符数的增加,由于上下文判定策略获得的段落数量正确率提升,逐渐优于句子结束策略。
从类型上看,《计算机学报》这类理工类期刊中包含英文单词较多,直接复制的编辑距离与原文差距最大(复制字符大于1501时平均编辑距离为240),优化难度很大;而PDF原文分栏仅为1栏的《社会科学研究》直接复制时差别最小(复制字符大于1501时平均编辑距离为75),优化效果最好。仔细分析文本优化方法失误情况,大多集中在中文标题的段落切分上,由于中文标题换行时没有句子结束的标点符号,极容易判定错误。
4结语
本文提出了一种适用于PDF复制的文本优化方法,该方法通过监听剪贴板达到用户“无感知”处理PDF复制文本的目的,采取内容优化方法修正文本格式错误,并提出3种不同的段落切分策略帮助用户区分正确的段落。从实验结果来看,本文提出的文本优化方法能够降低95%以上直接复制PDF文本时产生的格式错误,极大地提高了工作效率。
参考文献
[1]刘现营.面向医疗知识的PDF文本内容提取系统设计与实现[D].哈尔滨:哈尔滨工业大学,2018.
[2]林青.支持多终端HTML资源生成的PDF转化系统研究与实现[D].北京:北京工业大学,2014.
[3]宋艳娟,张文德.基于XML的PDF文档信息抽取系统的研究[J].现代图书情报技术,2005(9):10-13.
[4]陈云榕,刘立柱,丁志鸿.PDF文件中关键信息的提取与组织方法研究[J].计算机工程与设计,2007(7):1688-1690.
[5]张秀秀,张立峰.PDF文件文本内容提取研究[J].科技情报开发与经济,2008,18(36):118–120.
[6]黄江平,黄理灿,徐玲.基于Lucene的PDF文档的全文检索的实现[J].工业控制计算机,2012,25(5):103-104.
[7]王伟,孙成胜,伍少梅,等.一种轻量级文本蕴含模型[J].四川大学学报(自然科学版),2021,58(5):37-44.
[8]张擂,李清宝,贾天江,等.基于剪贴板监控的电子文档多级保护[J].计算机与现代化,2015(6):12-18.
[9]BECCHI M,CROWLEY P.An Improved Algorithm to Accelerate Regular Expression Evaluation[C]//Proceed-ings of the 3rd ACM/IEEE Symposium on Architecture for Networking and Communications Systems,2007:145-154.
[10]张晓培,李祥.从Unicode到GBK的内码转换[J].微计算机应用,2006(6):757-759.
[11]NAVARRO G.A Guided Tour to Approximate String Matching[J].ACM Computing Surveys(CSUR),ACM New York,NY,USA,2001,33(1):31–88.
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/46706.html