SCI论文(www.lunwensci.com):
摘要:为应对宽带精准营销、装维上门维护等需要,待处理的地址数据大量增加,而因为大量数据是由用户手工填写,同一地址由不同人书写往往会呈现不同文本,所以难免给地址的使用带来诸多不便。要提升地址使用效率,对地址进行规范化操作不失为一种有效的方法。本文提出建立规范地址库,借助少量标注数据进行度量学习,再通过习得距离矩阵在规范地址库中找到合适的地址,从而实现对自由文本地址规范化的目的。如此,可以以较小的计算代价实现中文地址的规范化,并为其他子系统提供一个统一的数据接口。
关键词:地址规范化;度量学习;中文地址
A Chinese Address Normalization Method Based on Metric Learning
Lu Guoliang,Yuan Tieshan
(China Mobile Zhejiang Co.,Ltd.Shaoxing Branch,Shaoxing Zhejiang,312000)
Abstract:In order to meet the needs of broadband precision marketing,on-site installation and maintenance,etc.,the address data to be processed increases greatly,and because a large amount of data isfilled in manually by users,the same address written by different people often presents different texts.A lot of inconvenience.In order to improve the efficiency of address usage,normalizing the address is an effective method.This paper proposes to establish a canonical address library,perform metric learning with the help of a small amount of labeled data,and thenfind suitable addresses in the canonical address library through the learned distance matrix,so as to realize the normalization of free text addresses.As a result,the normalization of Chinese addresses can be realized with a small computational cost,and a unified data interface can be provided for other subsystems at the same time.
Key words:address planning;metric learning;Chinese address
一、背景
随着通信企业服务的转型,宽带精准营销、装维上门服务等呈现出信息化趋势。为精确定位目标,快速提供上门服务,相关单位通常需要使用目标用户地址,但用户提供的地址往往缺乏规范性与正确性,会影响服务方良好服务的提供。地址规范化就是将现实中收集到的地址划分为符合规范的分级地址的一个过程,对提升地址的使用效率有较大帮助,但是,在实践中存在诸多问题,如某些地理分级可能被省略。例如:“浙江省绍兴市越城区胜利东路360号”会被省略为“绍兴胜利东路360号”;又由于中文语义的多样性,地址写明的“2幢”可能被写为“2号楼”或“2#”。以上种种问题,都会给中文地址的规范化带来不小的困难。
为解决中文地址规范化的问题,各学者提出了多种方法。Guo等人[1]提出了一种面向自由文本的地址规范化方法,指出了除对地理元素的分词外,挖掘自由文本中的语义关联性,能在较小的训练集上获得较好的标准化性能。邱泉清等人[2]利用条件随机场在真实微博数据上有效地完成了中文微博的命名实体识别,条件随机场是挖掘地址语义的一种常用的方法。Liao等人[3]利用独立特征为未标记数据提供高精度的标签,通过这些标签迭代改进分类器,实现了一种半监督的基于条件随机场的实体识别方法。为提升地址识别率,一些基于层叠条件随机场的方法被提出,用以改善地址文本长距离依赖和交叠性的特征。徐娟等人[4]提出一种基于层叠条件随机场的中文地址规范化方法,在真实地址语料库上获得了较好的识别率。基于深度学习的方法也被提出,主要用以提高地址识别的准确率。深度学习是近些年最热门的机器学习算法,也被用于地址规范化。Matci等人[5]提出了基于深度学习的地址规范化方法,提高了准确率的同时,也提供了多种规范地址输出的方式。现有方法在进行地址规范化时具有较高的准确性,但是方法的复杂度较高,无法在数据库上实现实时处理,同时规范化的数据受输入文本影响,规范化后的地址数据无法为下一级子系统提供一个统一的数据接口。
基于上述情况,本文提出一种利用度量学习的中文地址规范化方法,利用通信企业现有的规范地址数据库,度量学习学习距离度量矩阵,将自由文本关联最接近的地址规范化,在较小的复杂度范围内提高准确率。该方法在训练完成后,可以集成于数据库上运行,极大地减小下一级子系统的开发难度,同时为宽带精准营销、装维上门维护等提供统一、高效的规范化地址数据。
二、基于度量学习的中文地址规范化
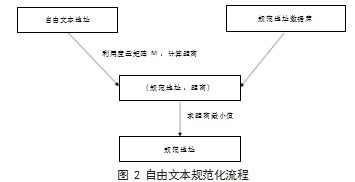
本文采用的方法需依赖规范化数据库的建立,通过少量标记数据及度量学习的方法训练获得自由文本地址数据与规范数据库的距离矩阵。少量标记数据可以由通信企业的一线收集得到,度量学习训练获得可以用Python等语言完成,之后的过程可以在数据库上实现,从而减小下一级子系统的开发难度。
(一)度量学习
度量学习提供了一种直接获得数据对象间的距离度量的方法,度量学习的目标是直接尝试学习获得一个合适的距离度量。相似数据对象间的距离小,不相似数据对象间的距离大,在习得的距离度量下,可以获得较好的学习效能。对于难以数量化的变量,如“西瓜”“人参果”“番茄”之间难以定义的距离,被称为“非距离度量”,有必要基于数据样本来确定合适的距离度量,这种“非距离度量”也是度量学习的重要作用之一。
度量学习可以直接使用原始特征空间对象间的欧式距离(Euclidean Distance)进行度量,著名的KNN算法在度量对象之间的距离时就直接使用了欧式距离。也有利用马氏距离(Mahalanobis distance),按主成分对源向量投影后再进行距离度量的,解决了欧式距离维度上不统一带来的度量标准不一致的问题。
(二)规范数据库建立
邮政快递企业可以依托投递端更正地址,通过报刊系统、两网互通系统与名址系统等途径建立规范的地址库。而通信企业则可以通过建设宽带资源点维护一个规范地址库。随着宽带的普及,从宽带方式获得规范地址库可以与邮政快递企业达到相似的结果。
一个规范的地址库包括到末端地址点的详细地址与地址的基本属性等信息,还包括对地址数据的拆分,即将地址拆分为数个层级。
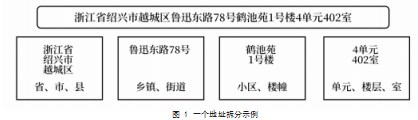
在图1示例中,地址“浙江省绍兴市越城区鲁迅东路78号鹤池苑1号楼4单元402室”被拆分为“浙江省,绍兴市,越城区,鲁迅东路78号,鹤池苑,1号楼,4单元,‘’,402室”这9级,在本文之后叙述中的假设地址被分为“省、市、县(乡镇)、街道、小区、楼幢、单元、楼层、室”这9级。在规范地址数据库的过程中,9级地址中的某些级别可能空缺,空缺值以空字符串‘’填充。
(三)模糊匹配
对于自由文本,直接使用规范地址库的地址分级数据进行匹配会出现大量失配,进而给规范化的结果带来很大影响。本文设计了加权的模糊匹配方法,令
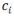
为规范地址库的分级地址的第i级,
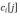
为该分级地址的第j个字符,在自由文本中是第k位的一个匹配,为其赋权2-k,
在自由文本上某个匹配的权值可以表示为以下公式。
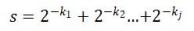
(1)
上式中kj代表在自由文本中的匹配位置,这里约定
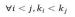
,对于特定
总是选择权值最大的匹配,同时设定一个阈值S,当s<S时认为在自由文本中不存在匹配,这样能使的匹配位置在自由文本中尽可能靠前,也能使匹配的字符尽可能多。
(四)度量学习与文本匹配
为了将自由文本地址输出为规范地址,本文使用了基于度量学习的匹配方式。

是规范地址数据库中的一个条目,上标标识了该条目在规范地址数据库中的第k个条目,下标i标识了条目中地址第i个分级。在本文中,max(i)=9。利用上文的模糊匹配方法,可以得到c在用户登记的地址中是否存在对应匹配子串的布尔值s,按下标排列s可以获得分级地址k
与用户登记地址a的距离,如下所示。
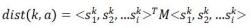
(2)
其中,M是一个i*i的(半)正定的对称方阵,以下称为度量矩阵。
利用部分标记数据,可以将度量矩阵M的学习转化为求解下面这个凸优化问题。
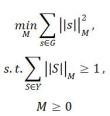
(3)
其中
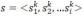
是规范地址数据库与自由文本地址之间的一个匹配向量,Y是度量学习训练集,S是其中一条规范地址数据库与自由文本地址的匹配向量。
在获得度量矩阵M后,对于任意一条自由文本地址可以获得与规范地址数据库k的距离,取距离的最小值作为用户的自由文本地址的规范化结果。

(4)
求解上式即是自由文本a,是使用规范化地址数据库规范化的结果。
本小节的标记数据通过度量学习获得了自由文本地址与规范地址数据库之间的距离矩阵,利用此距离矩阵在规范地址数据库中可寻找到最接近的规范地址,实现对自由文本地址的规范化。
三、结语
自由地址文本规范化可以极大限度地提升地址使用效率,对提升通信企业的服务及时性、提升用户的满意度有重大意义。本文提出一种先建立规范地址库,再通过少量标注数据进行度量学习,最后通过度量学习在规范地址库与自由地址文本之间建立一种距离衡量的方法,这一能在规范地址库中寻找距离最近的规范地址,实现对自由文本地址的规范化。本文的方法相较其他方法,能在相似性准确度高的情况下,以较小的计算代价实现中文地址的规范化,训练完成后可以在数据库中实现实时的中文地址规范化。由于能集成于数据库,因此能方便开发其他子系统,统一数据接口,优化数据安全管理,为通信企业宽带精准营销、装维上门维护等服务提供支持。
【参考文献】
[1]Guo H,Zhu H,Guo Z,et al.Address standardization with latent semantic association[C]//Acm Sigkdd International Conference on Knowledge Discovery&Data Mining.ACM,2009.
[2]邱泉清,苗夺谦,张志飞.中文微博命名实体识别[J].计算机科学,2013(6).
[3]Liao W,Veeramachaneni S.A Simple Semi-supervised Algorithm For Named Entity Recognition.Association for Computational Linguistics,2009.
[4]徐娟,曹晔,张奇.面向自由文本的中文地址规范化[J].计算机应用与软件,2015(08).
[5]Matci D K,Avdan U.Address standardization using the natural language process for improving geocoding results[J].Computers Environment and Urban Systems,2018,70(JUL.).
关注SCI论文创作发表,寻求SCI论文修改润色、SCI论文代发表等服务支撑,请锁定SCI论文网!
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/jisuanjilunwen/45317.html