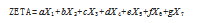摘要:文章采用理论分析与实证检验结合的方法,以76家公司的综合财务数据为研究基础,对债券违约企业与非违约企业的财务特征进行研究,以ZETA模型参数变量和Fisher判别分析方法,搭建违约风险评估模型,对企业的违约风险实施分析评价,并进行检验,以期为国家金融监管机构、金融机构和投资者等利益相关方提供科学的评价方法和决策依据。
关键词:违约,非违约,ZETA模型,Fisher判别分析
目前,我国经济处于转变发展方式、优化结构的调整关键期,金融领域的改革也不断深化,其中,债券市场作为金融市场的重要组成部分,发生了翻天覆地的变化,特别是债券种类不断丰富、投融资监管的适度放宽,让债券市场迎来了蓬勃发展时期。债券的发行有利于提高中央银行货币政策自上而下的传导效率,稳定经济增长和促进结构调整。据央行统计,截至2022年末,债券市场共发行各类债券61.9万亿元,其中,公司信用类债券发行13.8万亿元。现阶段,经济增长下行压力增大,宽松性货币政策推出,财务杠杆率迅速上升,随之带来了一定的系统性金融风险,在转向高质量发展的过程中,对于企业发行债券提出了更高的要求,违约事件陆续曝光,债券市场的信用风险面临不少挑战[1]。
债券融资具有独特的优点,如成本低、维持控股权、受限制较少等,可以预见,越来越多的企业将会依赖债券市场筹集资金。然而,高评级发行主体陆续出现债券违约事件,并可能变得常态化和复杂化,且近几年受国内外宏观因素影响,经济增长下行压力增大,债券违约风险日渐突出,因此,如何有效控制和管理公司债券的信用风险,合理化解伴随而来的金融风险,对我国经济平稳运行至关重要,也是目前债券市场风险管理的主要问题。现有大众普遍依据标普、穆迪的企业信用评级作为决策参考,但是这种评级往往适用于大中型企业,而量化评价标准则主要依托财务风险模型分析,特别是有关偿债能力指标的变化,但企业信用违约可能涉及多方面的因素,基于此,寻找一种涵盖多因素的风险度量方法,不但有助于监管部门和投资者及时识别出潜在风险,还有利于完善企业债券的违约防范和处置机制,恢复投资者的信心,更健康地引导债券市场服务于融资需求,让其充分发挥造血功能。本研究选取近几年违约企业与非违约企业若干作为样本,以ZETA模型的变量为基准,以违约企业违约前相应变量的特征作识别,代入Fisher检验作判别分析,由此产生相应的预测模型,并随机选取若干样本作为检验工具,观察分类落点,判断归类准确程度,以此寻找一种既建基于财务风险模型,又能结合统计分析的风险度量方法,降低纯粹应用财务分析风险模型的误判概率。
一、研究基础
(一)数据来源
本文的数据来源于东方财富网choice平台,以在我国债券市场已发行信用债的企业为研究对象,选取首次违约在2022年的企业24家,在2021年的企业21家,合计35家违约企业编入组1(违约组);随机选取截至2022年末未发生违约的33家企业编入组2(非违约组);选取首次违约在2023年的企业6家,随机选取5家非违约企业作为检验样本,样本选取时间截至2023年9月,数据主要以2022年年报为基准。
(二)ZETA模型
1977年,阿尔特曼(Altman)、赫尔德门(Haldeman)和纳内亚南(Narayanan)对原始的Z-score模型进行扩展,建立了第二代模型,也就是ZETA模型[2],表示如下。
式中,X1为息税前利润与总资产之比,属于资产收益率指标;X2为公司资产收益率5到10年变化的标准差值,属于收益稳定性指标;X3为息税前利润与利息费用之比,属于偿债能力指标;X4为留存收益与总资产之比,属于盈余积累指标;X5为流动资产与流动负债之比,属于流动性指标;X6为公司普通股市值与长期资本总额之比,普通股市值一般取5年的平均市值,属于资本化程度指标;X7为公司总资产的对数,属于规模指标。虽然上述模型相较早期的预警模型而言,增加了参数,考虑范围更广,预测更加准确,但是该模型中参数a、b、c、d、e、f、g因涉及商业机密问题而并未公开,使其应用受到一定限制。
(三)Fisher判别分析法
1.模型构建
Fisher判别分析法是一种经典的线性判别方法,由统计学家R.A.Fisher在1936年提出。该方法的原理是通过分析对象若干特征指标,并从中筛选出有效的变量来建立判别函数,以确认研究对象所属的类别。该方法基本是利用方差的理念,通过n维不同总体数量特征差异的变量,构造线性判别函数[3]。
二、实证研究
(一)指标体系搭建
本文的指标选取以全面性、系统性、实用性和科学性原则为基础,通过对国内外有关研究的分析整理,结合操作难度,以ZETA模型7个维度能力为基准,构建违约风险评价模型。具体如下。
1.盈利能力
盈利能力是指企业获取利润的能力,也称企业的资金或资本增值能力,直接影响其债券兑付程度的能力。企业的盈利能力越强,其债券按时履约能力就越强,违约可能性就越低。本模型反映盈利能力的指标有:X1资产收益率指标。
2.偿债能力
企业的偿债能力是指企业用资产偿还长期债务和短期债务的能力,即企业有无支付现金的能力和偿还债务能力,这是企业能否生存和健康发展的关键,直接体现债券履约能力,是企业的债权人、投资者、金融机构和经营管理者等利益关联方重点关注的核心能力之一。本模型反映偿债能力的有X3债务偿还能力指标、X5流动性指标和X7规模指标。
3.经营能力和成长能力
企业经营能力主要是指企业营运资产的效率与效益,具体表现为各项资产的周转速度,使用效率的高低;成长能力是指企业在资产规模、利润等方面的增长和扩张能力。本模型反映经营能力和成长能力的有X2收益稳定性指标和X4积累盈余指标。
4.资本结构和风险水平
资本结构是企业权益资金和借入资金的比例关系,直观反映了企业的偿债能力和风险水平,也可间接反映企业的再融资能力。本模型反映资本结构的有X6资本化程度指标。另外,考虑到数据的可获得性,为了便于操作,指标中X2收益稳定性指标采用3年期复合增长率CAGR替代,表现为:

,X6资本化程度指标则采用资产负债率替代。
(二)模型检验与模型结果
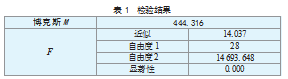
1.Box’M检验(见表1)
博克斯检验可以检验出样本之间的协方差矩阵是否齐次,由表1可以看出,检验值接近0,说明协方差矩阵不是单位阵,总体间的协方差存在显著性差异,适合做判别分析。
对等同群体协方差矩阵的原假设进行检验。
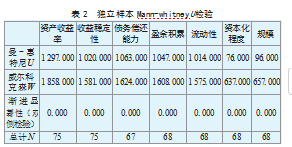
2.Mann-whitney U检验(见表2)
Mann-Whitney U检验,也被称为Wilcoxon秩和检验,是一种非参数统计检验,用于比较两个样本或群体。Mann-Whitney U检验评估了两个抽样群体是否来自同一群体,比较其数据特征方面形状的一致性,换言之,就是要证明这两个群体是否来自具有不同水平的相关变量企业。现围绕ZETA模型的7个变量进行Mann-whitney U检验,观察这些指标维度对企业违约行为是否产生显著影响,还有组1(违约组)与组2(非违约组)7个指标是否有显著差异,表2检验结果显示,7个指标p-value均小于0.05,故拒绝原假设,说明不同的组别之间其分布具有显著性差异,也就是这7个维度对企业违约状态有着显著影响。
表2显示了渐进显著性,显著性水平为0.05。
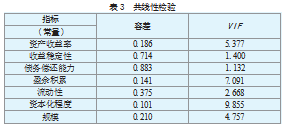
3.变量多重共线性检验(见表3)
线性回归模型中,自变量之间可能存在某种相关或者高度相关的关系,从而导致模型估计失真或难以估计准确。共线性的存在可能降低估计的精准度,并且稳定性也会降低,无法判断单独变量的影响。回归方程的标准误差增大,变量显著性可能会失去意义。一般而言,以容差、方差膨胀因子VIF作为共线性诊断指标,容忍度的值一般介于0和1之间,越接近0,共线性越强;VIF值一般应小于10,值越大,则共线性问题越明显。表3检验结果显示,7个变量的容差均大于0.1,VIF值均小于10,说明这7个变量不存在多重共线性问题。
(三)Fisher判别分析结果
1.模型结果
本文使用Fisher判别分析法对我国企业债券兑付情况进行实证预测,以ZETA模型中7个变量为自变量,以X1、X2、X3、X4、X5、X6、X7表示;以企业债券兑付情况为因变量,以y表示,分为y=1和y=2,分别表示“违约”“非违约”两个组别;以它们的关系构造多元线性回归模型来预测企业违约风险。经样本数据处理得出如下判别函数,系数见表4。
y=-11.509+(-0.036X1)+0.001X2+0.008X4+(-0.045X5)+0.032X6+0.966X7
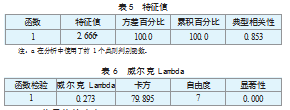
由表5得出特征值λ=2.666a,方差贡献率达到100%,说明函数解释能力很高。而在构造的函数中,指标为利息保障倍数,其系数为0,说明本指标在区分违约企业与非违约企业时效果不明显,原因可能是无论违约企业还是非违约企业,本身财务费用都比较高。各变量的影响程度从大到小分别为:规模、流动性、资产收益率、资本化程度、盈余积累,收益稳定性。而表6对所构造的典型判别函数的检验结果显示:在假设典型判别函数不显著的前提下,wilk's Lamda值为0.273,卡方统计量为79.895,p值为0.000,小于0.05,因此,所构造的典型判别函数是显著的。
2.临界值的确定
由表7可知,违约组和非违约组的重心坐标值分别为1.583和-1.632,为两组之间的重心点,因此,违约风险预测模型的判别规则为样本数据X1、X2、X3、X4、X5、X6、X7代入模型中,计算u'X值,再将其与1.583和-1.632的绝对离差距离进行比较,取较小值作为判断依据,如果u'X值与1.583较近,则判断为“违约组”。如果离-1.632较近,则判断为“非违约组”。或者依据公式(11),确定两组间的重心的加权平均值为-0.024 5,当u'X>-0.024 5时,将其归入“违约组”;当u'X<-0.024 5时,将其归入“非违约组”。
按组平均值进行求值的未标准化典则判别函数。
3.模型的预测效果
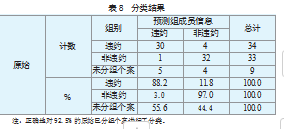
剔除数据不全的样本后,本文选取了首次发生违约在2021年和2022年的企业34家,在2022年未发生违约的随机企业33家,共计有效样本67家。而选取了9家企业作为检验样本,其中发生在2023年的违约企业6家,剔除了2家数据不全,有效入选4家,随机选取了5家非违约企业。分类结果如表8所示。
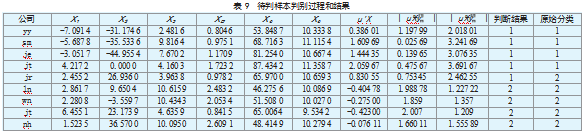
表8的检验结果显示,模型正确地对92.5%的原始个案进行分类。其中,在原样本67家企业中,违约组34家,错判4家,准确率88.2%;非违约组33家,错判1家,准确率97%;在检测样本9家企业中,实际情况是4家违约,5家非违约。而Fisher判断结果为5家违约,4家非违约,错判1家,准确率约89%。判断过程见表9。
根据Fisher对检验样本数据判别分析的结果,虽然未能达到100%准确判断,但仍能保持近90%的准确率,投资者或金融机构可据此对不同的企业实施不同的信贷政策,如预判为“非违约”,则可对该企业适当放心,按常规监管程序处理即可;但如果预判为“违约”,则要对该企业给予密切关注,通过控制授信额度或增加抵押、质押等方式保障信贷资金安全。
三、结语
本研究基于ZETA模型,通过对企业首次债券违约前1~3年的7个参数变量建立企业债券违约风险测量体系。通过Fisher判别分析的建模并验证,其判别准确率在90%以上,有较好的应用价值。
本研究的不足之处在于数据获取渠道有限,样本主要来源于上市公司,多数规模一般及以下企业的数据难以获取,因此,对于未上市或规模一般及以下的企业,其判断准确性仍有待验证。综上所述,从监管层面需要做出以下努力:一是完整企业数据库建设。数据是否完整、准确对模型的评价效果影响巨大。目前,数据库建设仍比较欠缺,因法律强制性规定,通常只能查找到上市公司的财务数据,其他类型的企业数据较难获取。二是违约风险管理体系和预警机制的建立。目前,我国已初步建成全国性的征信系统,但是基于全领域的数据库建设仍有所欠缺。基于大数据发展,建立工商管理、税务系统、银行、劳动保障等数据互联平台具有现实意义,能够以此促使各经营主体阳光经营,帮助利益相关者科学决策;就企业经营管理者而言,资产规模、资产收益率、流动性、资本化程度对信用风险影响较大,为避免陷入财务困境而导致违约,企业管理层应着重关注这些维度,持续监测企业在此方面的能力状况,对未来企业能否实现规模性扩张和持续性增长尤为重要。为最大限度降低违约风险,企业管理层应关注盈利质量,及时评估盈利模式和收入结构,确保企业获得持续且稳定的发展动力;另外,要考虑长期的战略布局,科学决策,拓展企业的发展前景;财务信息使用者在决策时也要关注相关维度,以此判断企业财务状况和自身决策。
参考文献:
[1]林采薇,张慧敏.碧桂园流动性压力如何化解?债务重整或提上日程[N].第一财经日报,2023-08-10(A2).
[2]ALTMAN E I.Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].Journal of Finance,1968,23(4):589-609.
[3]袁力,李艳午,杨菲.基于费舍尔判别分析的中药材鉴别[J].山西师范大学学报(自然科学版),2023,37(2):6-12.
文章出自SCI论文网转载请注明出处:https://www.lunwensci.com/guanlilunwen/81193.html